When writing a Monte-Carlo simulation to price financial derivative contracts, the most straightforward is to code a loop over the number of paths, in which each path is fully calculated. Inside the loop, a payoff function takes this path to compute the present value of the contract on the given path. The present values are recorded to lead to the Monte-Carlo statistics (mean, standard deviation).
I ignore here any eventual callability of the payoff which may still be addressed with some work-arounds in this setup. The idea can be schematized by the following go code:
fori:=0;i<numSimulations;i++{pathGenerator.ComputeNextPath(&path)//path contains an array of n time-steps of float64.pathEvaluator.Evaluate(&path,output)statistics.RecordValue(output)}
A python programmer would likely not write a simulation this way, as the python code inside the large loop will not be fast. Instead, the python programmer will write a vectorized simulation, generating all paths at the same time.
pathGenerator.ComputeAllPaths(&paths)//paths contains an array of n time-steps of vectors of size numSimulations pathEvaluator.EvaluateAll(&paths,output)statistics.RecordValues(output)
The latter approach sounds nice, but may easily blow up the memory, if all paths are stored in memory. One solution is to store only packages of path, and do the simulation multiple times, being careful as to where we start the random numbers along the way. It is possible to further optimize memory by not keeping each full path in memory, but just the current path values, along with a list of vector variables which track the payoff path dependency. This requires a special Brownian-bridge implementation in the context of Sobol quasi-random numbers, as described in Jherek Healy’s book.
We can thus summarize the various approaches by (A) iterative on scalars (B) fully vectorized (C) iterative on vectors. I intentionally abuse the language here as the scalars are not scalars, but 1 path comprised of values at all relevant times - in this terminology, scalar means a single path.
Which one is most appropriate?
I first heard about this debate in a Quantlib user meeting a long time ago. Alexander Sokol was arguing for (B) as it simplified the implementation of AAD, while Peter Caspers was more a (A) kind of guy. At the time, I had not fully grasped the interest of (B) as it seemed more complex to put in place properly.
It is interesting to think about those in terms of parallelization. At first, it may seem that (A) is simple to parallelize: you just process N/M package where M is the number of processors and N the total number of paths. Unfortunately, such a design implies a stateful payoff, which is not necessarily trivial to make thread-safe (actually very challenging). So the first drawback is that you may have to limit the parallelization to the path generation and to perform the payoff evaluation in a single thread. And then if you think more about it, you notice that while the first package is being computed, the payoff evaluation will just wait there. Sure, other packages will be computed in parallel, but this may again blow off the memory as you essentially keep all the paths in each package in memory. In practice, we would thus need to compute each path in some sort of thread pool and push those to a path queue of fixed length (blocking), which is read by the single thread, by taking a path from the queue, evaluate the payoff on this path, and pushing it back to a free queue in order to recycle the path. Alternatively, some sort of ring buffer structure could be used for the paths. One has also to be quite careful as well about the random number generator skipping to the correct position in order to keep the same sequence of random numbers as in a fully single threaded approach.
Taking parallelization into account, (A) is not that the trivial approach anymore. In contrast, (B) or (C) would parallelize the payoff evaluation by design, making the implementation of the full simulation parallelization much easier. Arguably, the package of paths approach may consume less memory than (C), as (1) the path generation usually involves many intermediate time-steps which may be discarded (kept only in cache per core) while in a vectorized approach, the full vector of those intermediate time-steps may be needed (typically for a classical Brownian-Bridge variance reduction), (2) the payoff evaluates scalars (and its state is thus comprised of scalars). A clever vectorized payoff evaluation would however reuse most vectors. The memory reduction may not be real in practice.
Now, if we include callability or particle method kind of evaluation, full vectorization, but keeping only the payoff (vector) variables in memory and building up the path step by step may be the most effective as described in Jherek Healy’s book.
To conclude, not vectorizing the path generation and payoff evaluation would be a design mistake nowadays.
This blog post from Jherek Healy presents some not so obvious behavior of automatic differentiation, when a function is decomposed
into the product of two parts where one part goes to infinity and the other to zero, and we know the overall result must go to zero (or to some other specific number).
This decomposition may be relatively simple to handle for the value of the function, but becomes far less trivial to think of in advance, at the derivative level.
I played myself with Julia’s excellent ForwardDiff package, and found out a completely different example which illustrates a simple and easy trap with automatic differentiation. The example is a typical cubic spline evaluation routine:
function evaluate(self, z)
i = searchsortedfirst(self.x, z) # x[i-1]<z<=x[i]if z == self.x[i]
return self.a[i]
endif i >1 i -=1end h = z - self.x[i]
return self.a[i] + h * (self.b[i] + h * (self.c[i] + h * (self.d[i])))
end
The ForwardDiff will lead to derivative = 0 at z = x[i], while, in reality, it is not - the derivative is b[i]. The case z = x[i] is just a (not so clever) optimization.
Granted, it is wrong only at the spline knots, but if those correspond to key points we evaluate as part of a minimization, it might become very problematic.
Another interesting remark to make on automatic differentiation is on the choice of backward (reverse) vs. forward (tangent) automatic differentiation: we often read that backward is more appropriate when the dimension of the output is low compared to the dimension of the input, and forward when the dimension of the output is large compared to the dimension of the input.
This is however not strictly true. A good example is the case of a least-squares minimization. The objective could be seen as a one-dimensional output: the sum of squares of the values of an underlying function.
But in reality, it is really N-dimensional, where N is the number of terms in the sum, as one sum involves N calculations of the underlying function.
And thus, for least-squares, backward automatic differentiation will likely be slower than forward since the number of terms in the sum is typically larger than the number of input parameters we are trying to fit.
lsqnonlin defaults to forward AD when the number of elements in the objective vector is greater than or equal to the number of variables. Otherwise, lsqnonlin defaults to reverse AD.
As described on wikipedia, a quadratic programming problem with n variables and m constraints is of the form
$$ \min(-d^T x + 1/2 x^T D x) $$ with the
constraints \( A^T x \geq b_0 \), were \(D\) is a \(n \times n\)-dimensional real symmetric matrix, \(A\) is a \(n \times m\)-dimensional real matrix, \( b_0 \) is a \(m\)-dimensional vector of constraints, \( d \) is a \(n\)-dimensional vector, and the variable \(x\) is a \(n\)-dimensional vector.
Solving convex quadratic programming problems happens to be useful in several areas of finance. One of the applications is to find the set of arbitrage-free option prices closest to a given set of market option prices as described in An arbitrage-free interpolation of class C2 for option prices (also published in the Journal of Derivatives). Another application is portfolio optimization.
In a blog post dating from 2018, Jherek Healy found that the sparse solve_qp solver of scilab was the most efficient across various open-source alternatives. The underlying algorithm is actually Berwin Turlach quadprog, originally coded in Fortran, and available as a R package. I had used this algorithm to implement the techniques described in my paper (and even proposed a small improvement regarding machine epsilon accuracy treatment, now included in the latest version of quadprog).
Julia, like Python, offers several good convex optimizers. But those support a richer set of problems than only the basic standard quadratic programming problem. As a consequence, they are not optimized for our simple use case. Indeed, I have ported the algorithm to Julia, and found out a 100x performance increase over the COSMO solver on the closest arbitrage-free option prices problem. Below is a table summarizing the results (also detailed on the github repo main page).
In the context of my thesis, I explored the use of stochastic collocation to capture the marginal densities of a positive asset.
Indeed, most financial asset prices must be non-negative. But the classic stochastic collocation towards the normally distributed random variable, is not.
A simple tweak, proposed early on by Grzelak, is to assume absorption and use the put-call parity to price put options (which otherwise depend on the left tail).
This sort of works most of the time, but a priori, there is no guarantee that we will end up with a positive put option price.
As an extreme example, we may consider the case where the collocation price formula leads to \(V_{\textsf{call}}(K=0) < f \) where \(f \) is the forward price to maturity.
The put-call parity relation applied at \(K=0 \) leads to \(V_{\textsf{put}}(K=0) = V_{\textsf{call}}(K=0)-f < 0 \). This means that for some strictly positive strike, the put option price will be negative, which is non-sensical.
In reality, it thus implies that absorption must happen earlier, not at \(S=0 \), but at some strictly positive asset price. And then it is not so obvious to chose the right value in advance.
In the paper, I look at alternative ways of expressing the absorption, which do not have this issue. Intuitively however, one may wonder why we would go through the hassle of considering a distribution which may end up negative to model a positive price.
In finance, the assumption of lognormal distribution of price returns is very common. The most straighforward would thus be to collocate towards a lognormal variate (instead of a normal one), and use an increasing polynomial map from \([0, \infty) \) to \([0, \infty) \).
There is no real numerical challenge to implement the idea. However it turns out not to work well, for reasons explained in the paper, one of those being a lack of invariance with regards to the lognormal distribution volatility.
This did not make it directly to the final thesis, because it was not core to it. Instead, I explore absorption with the Heston driver process (although, in hindsight, I should have just considered mapping 0 to 0 in the monotonic spline extrapolation). I recently added the paper on the simpler case of positive collocation with a normal or lognormal process to the arxiv.
Steven Koonin, who was Secretary for Science, Department of Energy, in the Obama administration recently wrote a somewhat controversial book on climate science with the title Unsettled. I was curious to read what kind of critics a physicist who partly worked in the field had, even if I believe that climate warming is real, and humans have an influence on it. It turns out that some of his remarks regarding models are relevant way beyond climate science, but some other subjects are not as convincing.
The first half of the book explains how the influence of humans on climate is not as obvious as what many graphs suggest, even those published by well known groups such as CSSR or IPCC.
A recurring theme is plots presented without context/with the wrong context. Many times, when we extend the time span in the past, a very different picture emerges of cyclic variations with cycles of different lengths and amplitudes. Other times, the choice of measure is not appropriate. Yey another aspect is the uncertainty of the models, which seems too rarely discussed in reports/papers, as well as the necessary model parameters tweaking.
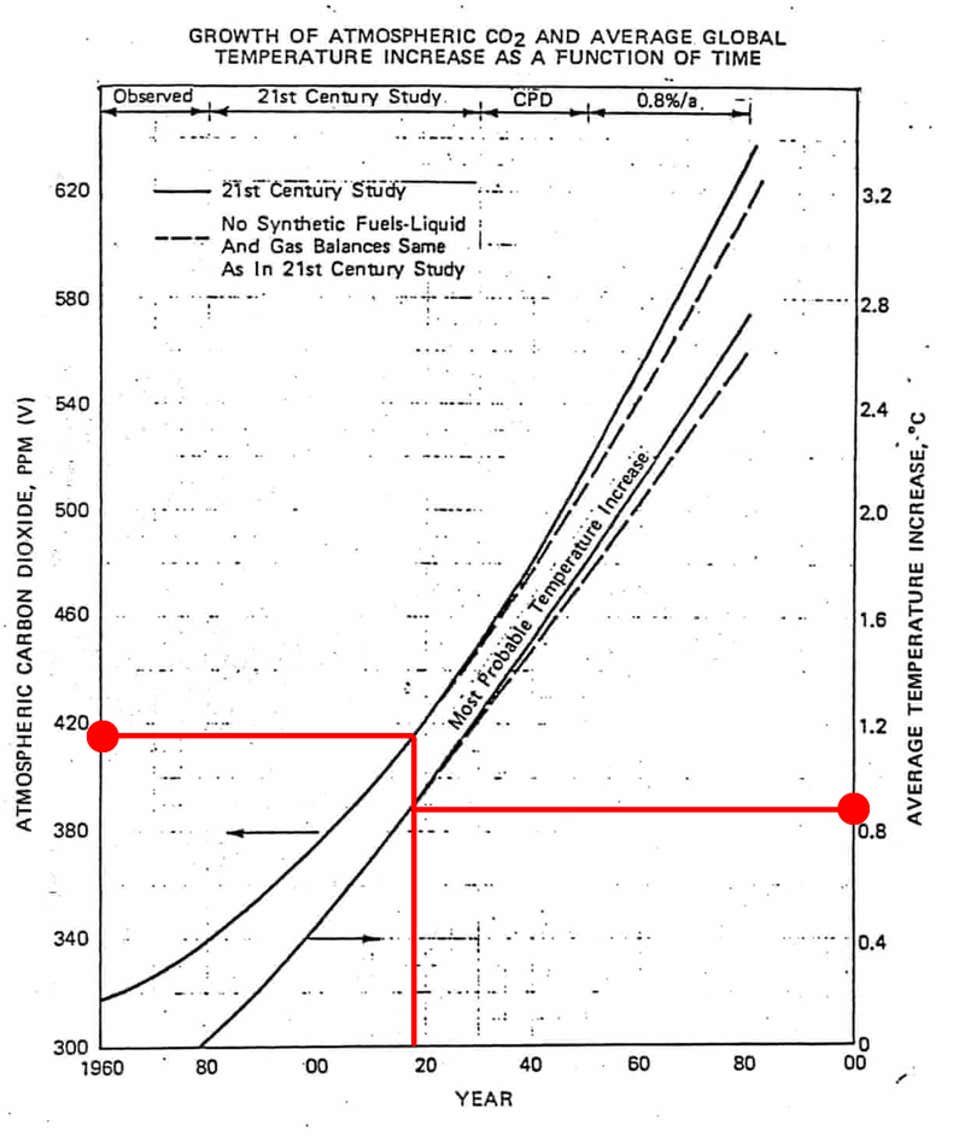
When it comes to CO2, Koonin explains that the decrease in cooling power is much much lower from 400ppm to 800ppm than from 0ppm to 400ppm, because, at 400ppm (the 2019 average) most of the light frequencies are already absorbed. The doubling corresponds only to a 0.8% change in heat intercepting. 1% is however not so small, as it corresponds to 3 degrees Kelvin/Celcius variation. Furthermore, while humans may increase warming with greenhouse gas, they also increase cooling via aerosols, the latter being much less well known and measured (with those taken into account, we arrive at the 1 degree Celcius impact). The author also presents some plots on CO2 on a scale of millions of years to explain that we live in an era of low CO2 ppm. While an interesting fact, this may be a bit misleading since, if we look at at up to 800,000 years back, the CO2 concentration stayed between 200 and 250 ppm, with an explosion only in the recent decades. The climate.gov website provides more context around the latter plot:
In fact, the last time the atmospheric CO₂ amounts were this high was more than 3 million years ago, when temperature was 2°–3°C (3.6°–5.4°F) higher than during the pre-industrial era, and sea level was 15–25 meters (50–80 feet) higher than today.
On this plot, the relation between the temperature increase and the CO2 ppm looks linear, which would be somewhat more alarming.
The conclusion from the first half of the book may be summarized as follows: while climate warming is real, it is not so obvious how much of it is due to humans. The author agrees for maybe around 1 degree Celcius, and suggests it is not necessarily accelerating. The causes are much less clear. There are some interesting subtleties: temperature increases in some places and decreases in others; around cities, the increase mostly due to the expansion of cities (more buildings).
I found the second half to be in contradiction with the first half, although it is clearly not the author’s intent: the second half focuses on how to address humans influence on the climate, and several times, suggests a strong influence of humans emissions on the climate, while the first half of the book was all about minimizing that aspect. This is especially true for carbon emissions, where it is suggested in the first half that additional emisssions will have a comparatively small impact.
The overall message is relatively simple: reducing emissions won’t help much as concentration will only increase in the coming decades (but then wouldn’t it perhaps be so bad to think beyond the coming decades?). Also the scales of emission reductions necessary for a minimum increase (2 degrees) is not realistic at all in the world we live in. Instead, we’d be better off trying to adapt.
Overall, the author denounce the issue of scientific integrity, which is too often absent or not strongly present enough. Having reviewed many papers, and published some in specialized journals, I can’t say I am surprised. Peer review is important, but perhaps not good enough by itself, especially in the short run. Over decades, I think the system may autocorrect itself however.
Github recently moved to support only ssh access via public/private keys. As I use github to host this blog, I was impacted.
The setup on Linux is not very complicated, and relatively well documented on Github itself but all the steps are not listed in a simplistic manner, and some Google search is still required to find out how to setup multiple private keys for various different servers or different repos.
Here is my short guide. In bash, do the following:
ssh-keygen -t ed25519 -C "your_email@example.com"
Make sure to give a specific name, e.g. /home/you/.ssh/id_customrepo_ed25519
One thing that motivated me for vaccination is the fake news propaganda against the Covid-19 vaccines.
A mild example relates to the data from Israel about the delta variant. This kind of article, with the title “Covid 19 Case Data in Israel, a Troubling Trend”, puts emphasis on the doubts on the effectivness of the vaccine:
the vaccine appears to have a negligible effect on an individual as to whether he/she catches the current strain. Moreover, the data indicates that the current vaccines used (Moderna, Pfizer-BioNTech, AstraZeneca) may have a decreasing effect on reduced hospitalizations and death if one does get infected with the Delta variant.
CNBC (far from the best news site) is much more balanced and precise in contrast:
However, the two-dose vaccine still works very well in preventing people from getting seriously sick, demonstrating 88% effectiveness against hospitalization and 91% effectiveness against severe illness, according to the Israeli data published Thursday.
Much more shocking is a tweet from Prashant Bhushan (whoever that is) which was relayed widely enough that I got to see it
Public Health Scotland have revealed that 5,522 people have died within twenty-eight days of having a Covid-19 vaccine within the past 6 months in Scotland alone! This is 9 times the people who died due to Covid from March 2020 till Jan 2021 in Scotland!
It points to an article in the Daily Expose (worse than a tabloid?) with a link to the actual study. Giving an actual link to the source is a very good practice, even if in this case, the authors of the news article write a lengthy text which says the opposite as the paper they cite as being the source. Indeed, p.27 of the paper says
Using the 5-year average monthly death rate (by age band and gender) from 2015 to 2019 for comparison, 8,718 deaths would have been expected among the vaccinated population within 28 days of receiving their COVID-19 vaccination.
This means the observed number of deaths is lower than expected compared with mortality rates for the same time period in previous years…
Why do people write such fake news articles?
I can imagine 3 kinds of motivations:
The author wants to make money/be famous. Writing controversial things, even if completely false, seems to work wonder to attract readership, as long as there is a trend of readers curious about this controverse. The author will gather page views and followers easily, which he may then monetize.
The author is just someone so convinced in his beliefs that everything is interpreted through a very narrow band-pass filter. They will read and pay attention only to the words in the text that will validate their beliefs and forget everything else. I know examples (not on this particular subject) in my own family.
Farm trolls. There are many farm trolls (we always hear of the Russian farm trolls, but they really exist in most countries), where people are paid to spread disinformation on social media. A simple example is the fake reviews on Amazon. Sometimes the goal is to promote a particular political party ideas. Sometimes this political party is financed by a foreign country with specific interests.
The third motivation may act as an amplifier of the first two.
Why are fake news successful?
People do not trust the official government message. On the coronavirus, the French government was initially quite bad at presenting the situation, with the famous “masks are useless” (because they did not have any stock), a couple of months before enforcing masks everywhere. Too many decisions are purely political. A good example is the policy to close a school class on a single positive test when the full school is being tested for coronavirus. The false positive rate guarantees that at least 1/3 of the classes will close. Initially the policy was 3 positive tests, which was much more rational, but not as obvious to understand for the masses. My son ended up being one of those false positives, and it wasn’t a particularly nice experience.
People do not trust traditional media anymore. As the quality of standard newspapers dwindled with the rise of the internet, people do not trust those much anymore. Also, perhaps fairly, it is not clear if classic tradional media present better news than free modern social media. There are exceptions of course (typically with monthly publications).
Social media bias: almost all social networks act as narrow band-pass filter. If you look at one video of cat on youtube, you will end up with videos of cats in your youtube frontpage every day. Controversial subjects/videos are given a considerable space. A main reason for this behavior is that they are optimized for page views/to attract your attention.
Generalized attention deficit disorder due to the ubiquity of smart phones. Twitter got famous because of the 127 characters message limit. Newspaper articles are perhaps five times shorter than they used to be in the early 1990s. The time we have is limited and a lot of it is spent reading/writing short updates to various Whatsapp groups or other social network apps.
Conclusion
This was not the only motivator, another strong one is a Russian friend who caught the Covid-19 in July 2021, who was not very pro-vaccination, but thought, once it was too late, “I really should have applied for the vaccine”, as he realized it impacted the whole circle of relations around him. Then, one by one, his whole family caught the Covid. Fortunately, no-one died.
After several weeks, my parents and I were finally able to have a real world meeting with the advisor at the bank. The advisor is a young woman with an obvious background in sales.
In order to process the paperwork around the reimbursement of the phishing scam, the main issue was the request of the original phishing e-mail by the bank, as my mother had deleted the e-mail. It turns out, that in Thunderbird, deleted e-mails are not deleted on disk until an operation of compactification of the mailbox is done. I was thus able to recover the deleted e-mail. Interestingly, the deleted e-mail was not in the trash file, but directly in the inbox file.
At first, I sent the message source as PDF, along with a screenshot to the bank. The bank asked to forward the e-mail instead. Interestingly, it turns out that once a phishing e-mail is registered in the various anti-phishing filters, it is not possible to forward (directly or in attachment) or copy paste the email as most servers (including the bank servers) will detect the new email as potential phishing and directly reject the e-mail (reject error).
So the standard process of the bank is not really appropriate. It can be followed only during the very short period (more luck than anything) where the phishing has not yet been registered in the anti-phishing filters. I noticed by a simple Google search that many other institution follow a similar process, where they ask to forward the phishing e-mail to a specific e-mail address.
The good news so far is that officially, the advisor pushed the fraud case forward, although it is not entirely clear at this point if it will be processed properly. What shocked me more was the speech of the bank advisor. First, she scared us by telling stories of various credit card frauds (obviously not related to our bank credentials fraud). When she mentioned insurances against credit card frauds, without selling them yet to us, her goal became clear. Then she thought comforting that this kind of fraud only happens once, because once you are confronted to a fraud, you would then be more careful and not make the same mistake anymore, not a convincing argument at all in my views. She indirectly kept blaming my mother for entering her credentials, but was much less clear about the strong authentication at the bank, especially when I explained that, usually, at another bank, I receive a text message with a unique code to enter each time I try to wire money towards a new account, something this bank obviously did not implement properly. Strong authentication is now part of the European law (DSP-2). Then she found every single argument to not close some of the accounts of my parents (they have far too many pointless accounts at this bank). And finally she tried to sell us some special managed account for stock trading (managed by the bank entirely, with the money from my parents), claiming the economy was really great in these COVID-19 times.
Overall there is a real important problem with bank frauds in the 21st century. The system currently in place expects that most people, including 80 years old, must be tech experts, who know how to carefully look at any suspicious email header, such as the from field email address (which could also be better forged than the phishing email my parents received). It expects that everybody carefully checks the http address in the browser (which may also interestingly forged via UTF-8 codes). It relies on somewhat buggy phone applications, which constantly change, and are different for every bank. It expects that most people never click on a link, but then banks themselves send emails with links to promote various products they sell. Banks should really think of adopting a more unified, standard approach to authentication, such as FreeOTP, based on HOTP and TOTP.
My mother became so paranoid that she does not recognize a valid message from the bank as a normal, standard communication from the bank anymore.
And we are left me with a bank advisor who is not far of being a fraudster him/herself. One may wonder if things would really be much worse with a bitcoin wallet.
By the time I am writing this, my parents were fully reimbursed by the bank, the phishing e-mail was really all they needed.
Yesterday evening, I received a call from my mother, frantic over the phone. She says she sees alerts of withdrawals from her bank account on her phone, with new alerts every 5 minutes or so. I try to ask her if she clicked recently on some e-mail related to her bank. She is so panicked that I don’t manage to have an answer. While trying to understand if those alerts are real or not, my wife suggests immediately that my mother should call her bank. On the phone, I ask
did you call the bank? You should really call the bank right now if you did not.
I don’t have any number to call them, she replies.
After a 5 seconds Google search, my wife finds a number to call in case of phishing at this bank. I start spelling the number to my mother. Before I finish my mother replies
ah this number does not work.
so you had already this number and tried to call it? I ask
yes, it does not work.
She starts shouting and asks me to come over. I hang up and tell her I will call back shortly, when she is calmer. I call her back 1 minute later and tell her I will come over.
In the meantime, my wife attempts to call the number. She stumbles upon some bot asking for bank credentials or alternatively if she wants to speak to a person. She opts for a person, and indeed, ends up with someone hanging up the phone without having the chance to say a word. She then calls the international number, just below that first number. Bingo, someone helpful is here. She asks the person to call my parents.
When I arrive at my parents place, the person from the bank had reached to my mother, and closed internet access to her bank account to the great relief of everyone. Then, I search the computer, her phone, her tablet, for any text message or e-mail that was suspicious that day. I could not find any. She did receive some legitimate emails from the bank, but only alerts around what was happening in the evening. It started with a message of a new device being allowed to access the bank account website.
I then have the idea to look into the browser history. What is the first page of the day being consulted, around noon?
A phishing website with my mother’s bank name as title.
Then I try to find out how she managed to stumble upon that site. I don’t find anything. And when I ask her, it’s not entirely clear at first, there may have been another email she received. She may have clicked on that email. And she may have given various personal information on, what she believed to be, the bank website. Ok, the classic phishing story then. I tell my parents that they know they should never click on a link in an e-mail. My father then asks “but what do you mean exactly by a link?”. I fail to understand the true meaning of the question at the time, and show him what is a link exactly and elaborate further.
It does not stop there. Out of curiosity, I look at the whois information for this phishing web site. It’s on godaddy, there is not much information, except
some arab name servers, and the country of registration is Saudi Arabia. When I mention this to my father later on, he says:
This might be a coincidence, but yesterday, I gave two checks (of the same bank) to the guy in charge of the repairs (or replacement?) of the water softener I had contacted. He has an arabic name.
I know his tendencies to be “racist”, and tell him it probably does not have any relation. And then we think a bit more about the situation, and there is indeed a strange coincidence, as the phishing e-mail (which I never saw since my mother may have deleted it on purpose) was “from” the same bank, only 1 day later. How could the hackers know my parents bank? They did not receive any phishing e-mail for any other bank. The time and place point towards some sort of targeting.
I go back home, and we further discuss with my wife about all this. And she asks me:
If the two are related, how could the water softener guys have the e-mail address of your parents?
Good question. I call my father and ask him. It turns out he had received an e-mail (a SPAM) from the water softener company and replied to it. This is how he contacted them. And perhaps, this explains why he wanted to know more about what “clicking on a link” means. I guess he knows now.
Although I have no real proof, I am quite confident the water softener SPAM and the bank hack are very closely related. I did not think phishing was so “targeted”, and again it is my wife, who told me that targeting is apparently common in phishing. All this targeting makes me think of another story, involving an 80-years old member of the family, where the special forces broke into his house around 3 a.m. a few months back, shouting “target, target”, pointing their big guns, and arresting everybody in the house. But that’s a story for another time.
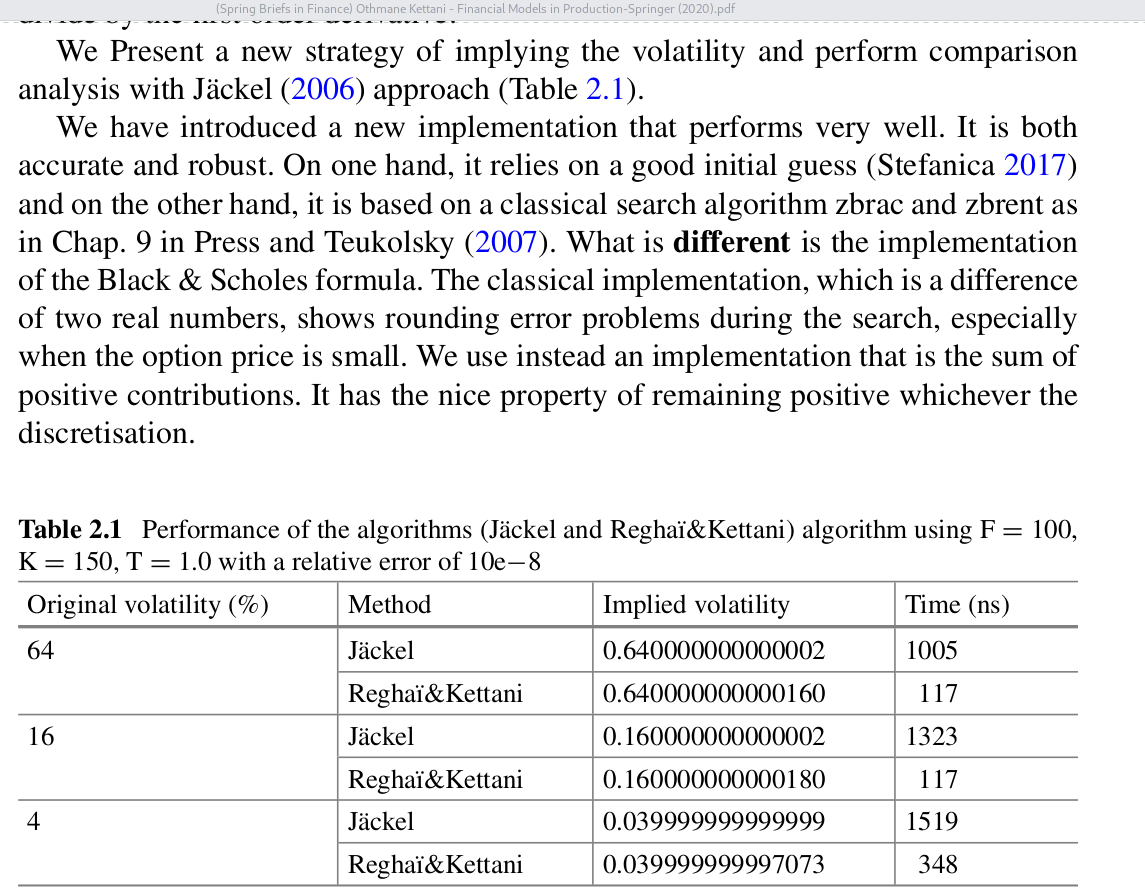
I stumbled upon a new short book Financial Models in Production from O. Kettani and A. Reghai. A page attracted my attention
A page from Kettani and Reghai's book.
This is the same example as I used on my blog, where I also present the Li’s SOR method combined with the good initial guess from Stefanica. The idea has also been expanded on in Jherek Healy’s book. What is shocking is that, beside reusing my example, they reuse my timing for Jäckel and my implementation is in Google Go, with a timing done on some older laptop. The numbers given are thus highly inconsistent. Of course, none of this is mentioned anywhere, and the book does not reference my blog.
I also find the description of how they improve the implied volatility algorithm (detailed on the next page) to not make much sense. After this kind of stuff, you can’t really trust anything that is in the book…
Worst perhaps, is that the authors advertise their “novel” technique in otherwise decent talks and conferences, such as the one from mathfinance. Here is a quote
Enforced Numerical Monotonicity (ENM) beats Jäckel’s implied volatility calculations – an implied vol calculator that never breaks and automatically fits vanilla option prices.
It is really unfortunate that the world we live in encourages such boasting. Papers always need to present some novel ideas to be published, but there is too often no check on whether the idea actually works, or is worth it. The temptation to make exagerated claims is very high for authors. In the end, it becomes not so easy to sort out the good from the bad.