When computing the derivative of a function by finite difference, which step size is optimal? The answer depends on the kind of difference (forward, backward or central), and the degree of the derivative (first or second typically for finance).
For the first derivative, the result is very quick to find (it’s on wikipedia). For the second derivative, it’s more challenging. The Lecture Notes of Karen Kopecky provide an answer. I wonder if Copilot or ChatGPT would find a good solution to the question:
“What is the optimal step size to compute the second derivative of a function by centered numerical differentiation?”
Here is the answer of copilot:
and the one of chatGPT:
and a second answer from chatGPT:
Copilot always fails to provide a valid answer. ChatGPT v4 proves to be quite impressive: it is able to reproduce some of the reasoning presented in the lecture notes.
Interestingly, with centered difference, for a given accuracy, the optimal step size is different for the first and for the second derivative. It may, at first, seem like a good idea to use a different size for each. In reality, when both the first and second derivative of the function are needed (for example the Delta and Gamma greeks of a financial product), it is rarely a good idea to use a different step size for each. Firstly, it will be slower since more the function will be evaluated at more points. Secondly, if there is a discontinuity in the function or in its derivatives, the first derivative may be estimated without going over the discontinuity while the second derivative may be estimated going over the discontinuity, leading to puzzling results.
The COS method is a fast way to price vanilla European options under stochastic volatility models with a known characteristic function. There are alternatives, explored in previousblogposts. A main advantage of the COS method is its simplicity. But this comes at the expense of finding the correct values for the truncation level and the (associated) number of terms.
A related issue of the COS method, or its more fancy wavelet cousin the SWIFT method, is to require a huge (>65K) number of points to reach a reasonable accuracy for some somewhat extreme choices of Heston parameters. I provide an example in a recent paper (see Section 5).
Gero Junike recently wrote severalpapers on how to find good estimates for those two parameters. Gero derives a slightly different formula for the put option, by centering the distribution on \( \mathbb{E}[\ln S] \). It is closer to my own improved COS formula, where I center the integration on the forward. The estimate for the truncation is larger than the one we are used to (for example using the estimate based on 4 cumulants of Mike Staunton), and the number of points is very conservative.
The bigger issue with this new estimate, is that it relies on an integration of a function of the characteristic function, very much like the original problem we are trying to solve (the price of a vanilla option). This is in order to estimate the \( ||f^{(20)}||_{\infty} \). Interestingly, evaluating this integral is not always trivial, the double exponential quadrature in Julia fails. I found that reusing the transform from \( (0,\infty) \) to (-1,1) of Andersen and Lake along with a Gauss-Legendre quadrature on 128 points seemed to be ok (at least for some values of the Heston parameters, it may be fragile, not sure).
While very conservative, it seems to produce the desired accuracy on the extreme example mentioned in the paper, it leads to N=756467 points and a upper truncation at b=402.6 for a relative tolerance of 1E-4. Of course, on such examples the COS method is not fast anymore. For comparison, the Joshi-Yang technique with 128 points produces the same accuracy in 235 μs as the COS method in 395 ms on this example, that is a factor of 1000 (on many other examples the COS method behaves significantly better of course).
Furthermore, as stated in Gero Junike’s paper, the estimate fails for less smooth distributions such as the one of the Variance Gamma (VG) model.
I never paid too much attention to it, but the term-structure of variance swaps is not always realistic under the Schobel-Zhu stochastic volatility model.
This is not fundamentally the case with the Heston model, the Heston model is merely extremely limited to produce either a flat shape or a downward sloping exponential shape.
Under the Schobel-Zhu model, the price of a newly issued variance swap reads
$$ V(T) = \left[\left(v_0-\theta\right)^2-\frac{\eta^2}{2\kappa}\right]\frac{1-e^{-2\kappa T}}{2\kappa T}+2\theta(v_0-\theta)\frac{1-e^{-\kappa T}}{\kappa T}+\theta^2+\frac{\eta^2}{2\kappa},,$$
where \( \eta \) is the vol of vol.
When \( T \to \infty \), we have \( V(T) \to \theta^2 + \frac{\eta^2}{2\kappa} \).
Unless \( \kappa \) is very large, or the vol of vol is very small, the second term will often dominate. In plain words, the prices of long-term variance swaps are almost purely dictated by the vol of vol when the speed of mean reversion is lower than 1.0.
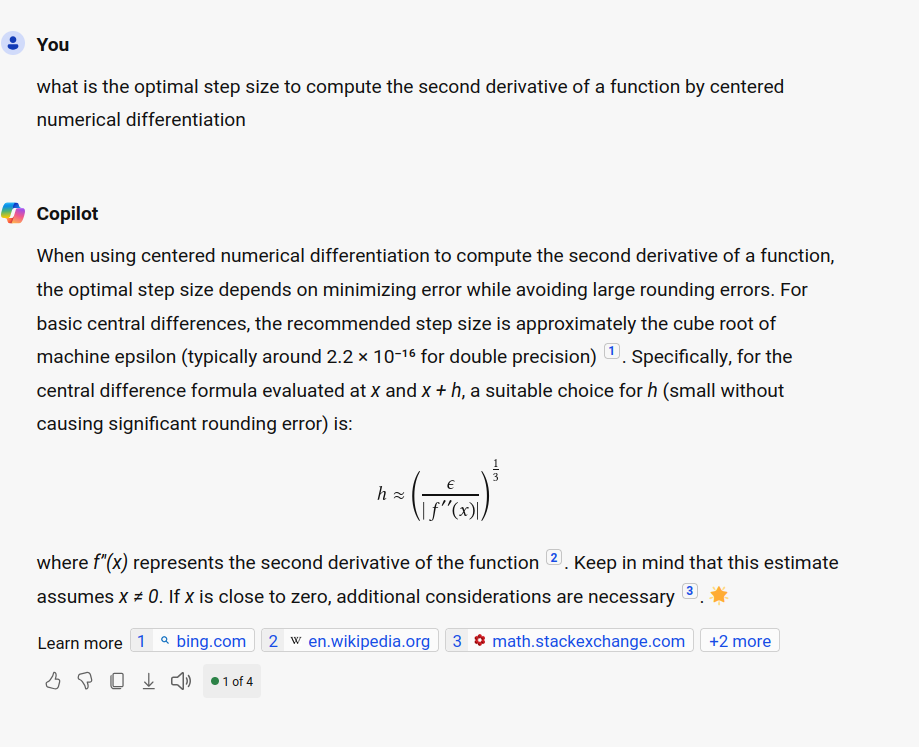
Below is an example of fit to the market. If the vol of vol and kappa are exogeneous and we calibrate only the initial vol v0, plus the long term vol theta to the term-structure of variance swaps, then we end up with upward shapes for the term-structure, regardless of theta. Only when we add the vol of vol to the calibration, we find a reasonable solution. The solution is however not really better than the one corresponding to the Heston fit with only 2 parameters. It thus looks overparameterized.
Term-structure of variance swap prices on Russell 2000 index
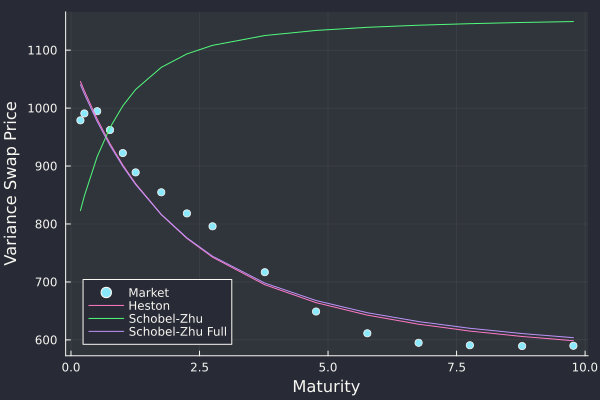
There are some cases where the Schobel-Zhu model allows for a better fit than Heston, and makes use of the flexibility due to the vol of vol.
Term-structure of variance swap prices on SPX 500 index
It is awkward that the variance swap term-structure depends on the vol of vol in the Schobel-Zhu model.
In the previous post, I presented a new stochastic expansion for the prices of Asian options. The stochastic expansion is generalized to basket options in the paper, and can thus be applied on the problem of pricing vanilla options with cash dividends.
I have updated the paper with comparisons to more direct stochastic expansions for pricing vanilla options with cash dividends, such as the one of Etoré and Gobet, and my own refinement on it.
The second and third order basket expansions turn out to be significantly more accurate than the previous, more direct stochastic expansions, even on extreme examples.
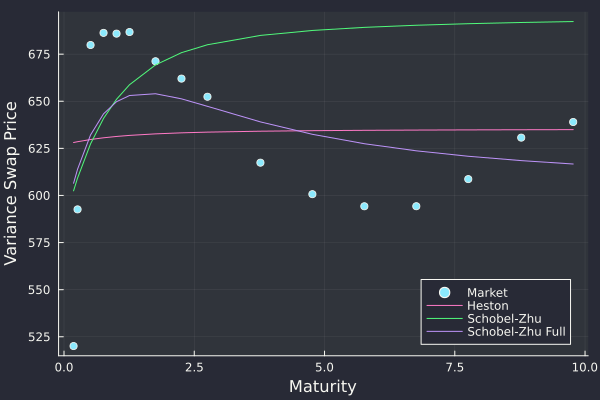
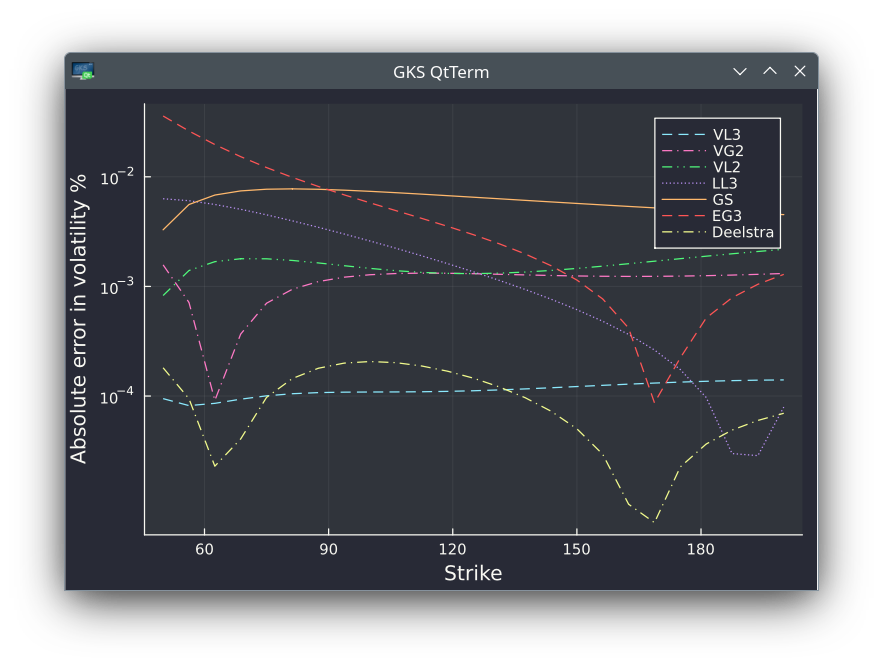
Extreme case with large volatility (80% on 1 year) and two unrealistically large dividends of 25 (spot=100). VGn and VLn are stochastic expansions of order n using two different proxies. EG3 and LL3 are the third order expansions of Etore-Gobet and Le Floc'h. Deelstra is the refined Curran moment matching technique.
Long maturity (10y) with dividend (amount=2) every six month. VGn and VLn are stochastic expansions of order n using two different proxies. EG3 and LL3 are the third order expansions of Etore-Gobet and Le Floc'h. Deelstra is the refined Curran moment matching technique.
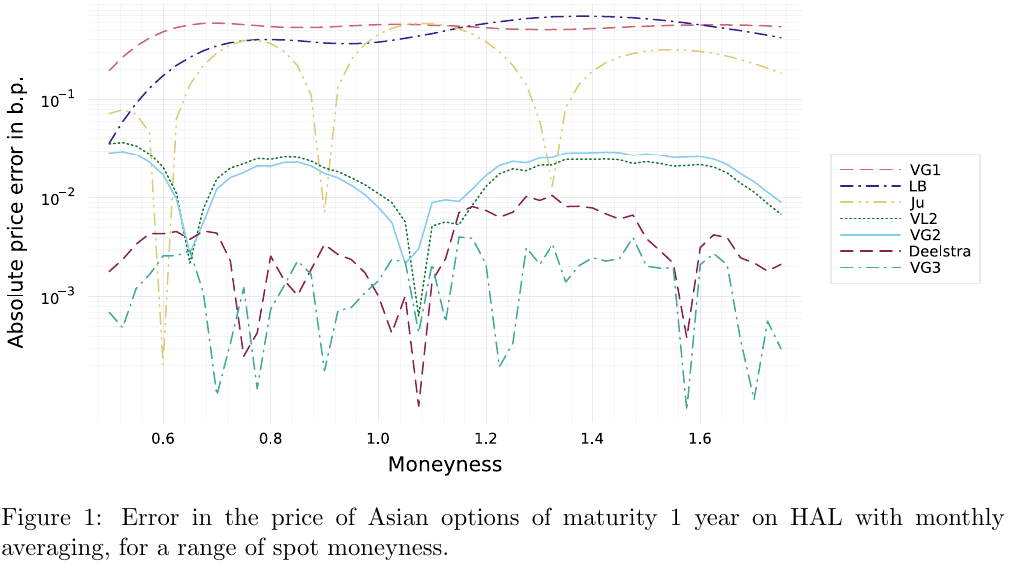
Recently, I had the idea of applying the same stochastic expansion technique to the prices of Asian options, and more generally to the prices of vanilla basket options. It works surprising well for Asian options. A main advantage is that the expansion is straightforward to implement: there is no numerical solving or numerical quadrature needed.
VGn and VLn are stochastic expansions of order n using two different proxies
It works a little bit less well for basket options. Even though I found a better proxy for those, the expansions behave less well with large volatility (really, large total variance), regardless of the proxy. I notice now this was also true for the case of discrete dividends where, clearly the accuracy deteriorates somewhat significantly in “extreme” examples such as a vol of 80% for an option maturity of 1 year (see Figure 3).
I did not compare the use of the direct stochastic expansion for discrete dividends, and the one going through the vanilla basket expansion, maybe for a next post.
In the Black-Scholes model with a term-structure of volatilities, the Log-Euler Monte-Carlo scheme is not necessarily exact.
This happens if you have two assets \(S_1\) and \(S_2\), with two different time varying volatilities \(\sigma_1(t), \sigma_2(t) \). The covariance from the Ito isometry from \(t=t_0\) to \(t=t_1\) reads $$ \int_{t_0}^{t_1} \sigma_1(s)\sigma_2(s) \rho ds, $$ while a naive log-Euler discretization may use
$$ \rho \bar\sigma_1(t_0) \bar\sigma_2(t_0) (t_1-t_0). $$
In practice, the \( \bar\sigma_i(t_0) \) are calibrated such that the vanilla option prices are exact, meaning
$$ \bar{\sigma}_i^2(t_0)(t_1-t_0) = \int_{t_0}^{t_1} \sigma_i^2(s) ds.$$
As such the covariance of the log-Euler scheme does not match the covariance from the Ito isometry unless the volatilities are constant in time. This means that the prices of European vanilla basket options is going to be slightly off, even though they are not path dependent.
The fix is of course to use the true covariance matrix between \(t_0\) and \(t_1\).
The issue may also happen if instead of using the square root of the covariance matrix in the Monte-Carlo discretization, the square root of the correlation matrix is used.
In my previous blog post, I looked at the roughness of the SVCJ stochastic volatility model with jumps (in the volatility). In this model, the jumps occur randomly, but at discrete times. And with typical parameters used in the litterature, the jumps are not so frequent. It is thus more interesting to look at the roughness of pure jump processes, such as the CGMY process.
The CGMY process is more challenging to simulate. I used the approach based on the characteristic function described in Simulating Levy Processes from Their Characteristic Functions and Financial Applications. Ballota and Kyriakou add some variations based on FFT pricing of the characteristic function in Monte Carlo simulation of the CGMY process and option pricing and pay much care about a proper truncation range. Indeed, I found that the truncation range was key to simulate the process properly and not always trivial to set up especially for \(Y \in (0,1) \). I however did not implement any automated range guess as I am merely interested in very specific use cases, and I used the COS method instead of FFT.
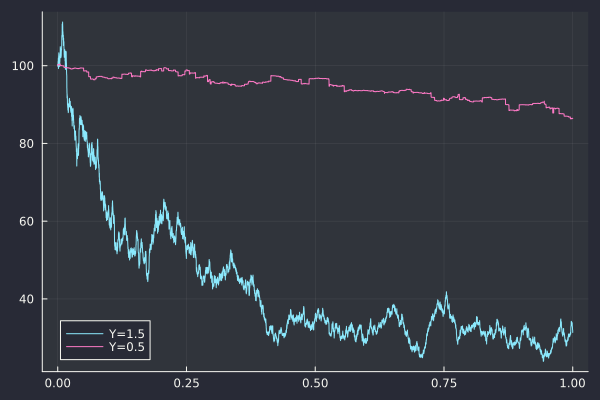
I also directly analyze the roughness of a sub-sampled asset path (the exponential of the CGMY process), and not of some volatility path as I was curious if pure jump processes would mislead roughness estimators. I simulated the paths corresponding to parameters given in Fang thesis The COS Method - An Efficient Fourier Method for Pricing Financial Derivatives: C = 1, G = 5, M = 5, Y = 0.5 or Y = 1.5.
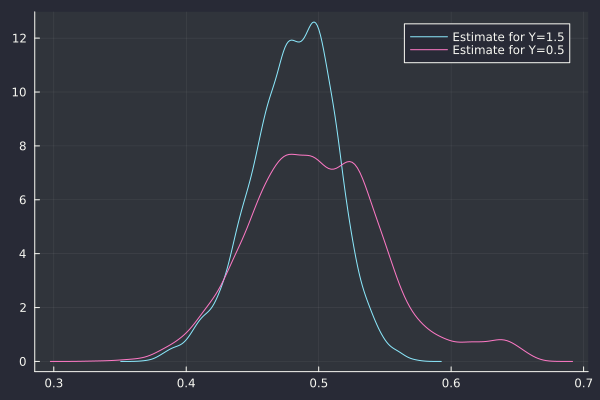
And the corresponding Hurst index estimate via the Cont-Das method:
Similarly the Gatheral-Rosenbaum estimate has no issue finding H=0.5.
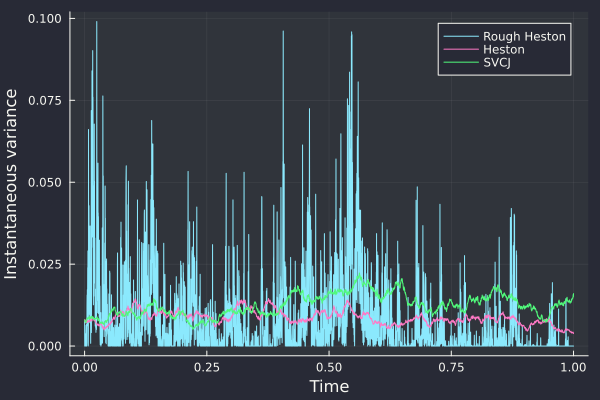
I was wondering if adding jumps to stochastic volatility, as is done in the SVCJ model of Duffie, Singleton and Pan “Transform Analysis and Asset Pricing for Affine Jump-Diffusion” also in Broadie and Kaya “Exact simulation of stochastic volatility and other affine jump diffusion processes”, would lead to rougher paths, or if it would mislead the roughness estimators.
The answer to the first question can almost be answered visually:
The parameters used are the one from Broadie and Kaya: v0=0.007569, kappa=3.46, theta=0.008, rho=-0.82, sigma=0.14 (Heston), jump correlation -0.38, jump intensity 0.47, jump vol 0.0001, jump mean 0.05, jump drift -0.1.
The Rough Heston with H=0.1 is much “noisier”. There is not apparent difference between SVCJ and Heston in the path of the variance.
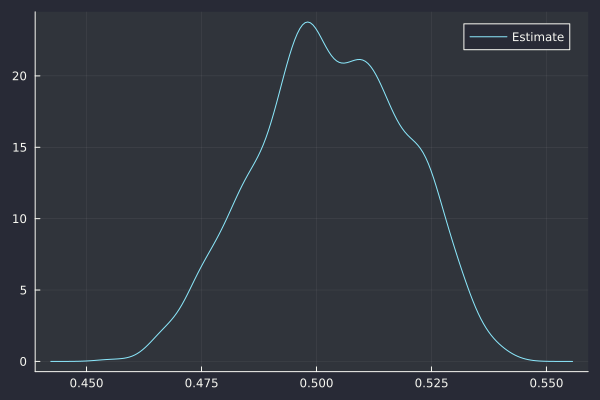
The estimator of Cont and Das (on a subsampled path) leads to a Hurst exponent H=0.503, in line with a standard Brownian motion.
Cont-Das estimate H=0.503.
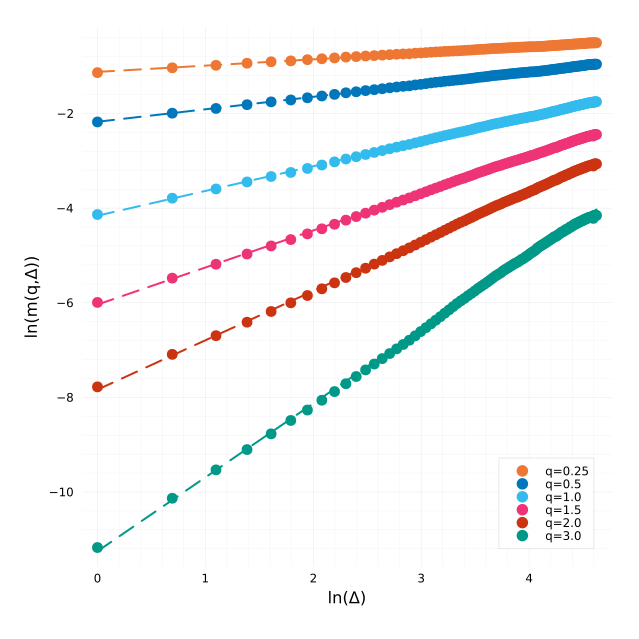
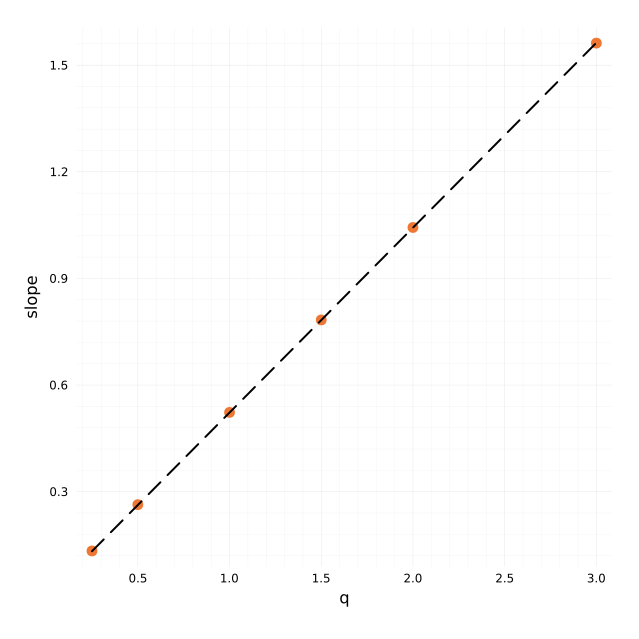
The estimator from Rosenbaum and Gatheral leads to a Hurst exponent (slope of the regression) H=0.520 with well behaved regressions:
Regressions for each q.
Regression over all qs which leads to the estimate of H.
On this example, there are relatively few jumps during the 1 year duration. If we multiply the jump intensity by 1000 and reduce the jump mean accordingly, the conclusions are the same. Jumps and roughness are fundamentally different.
Of course this does not mean that the short term realized volatility does not look rough as evidenced in Cont and Das paper:
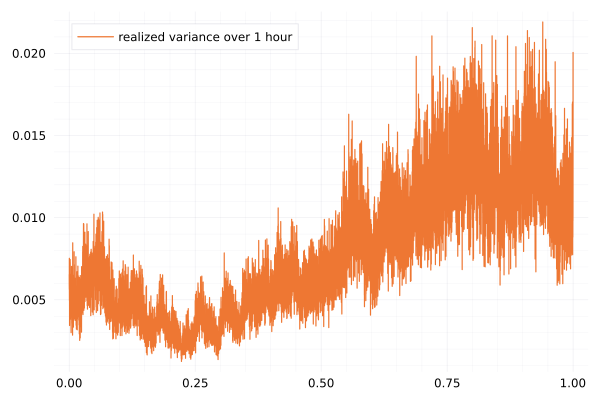
The 1 hour realized volatility looks rough.
I computed the realized volatility on a subsampled path, using disjoint windows of 1h of length.
It is not really rough, estimators will have a tough time leading to stable estimates on it.
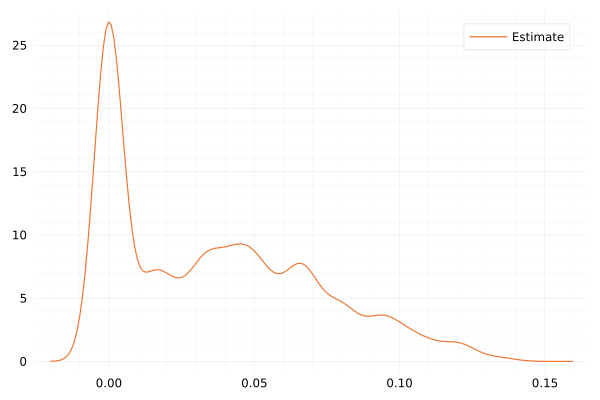
Hurst exponent estimation based on the 1h realized variance. The mean H=0.054 but is clearly not reliable.
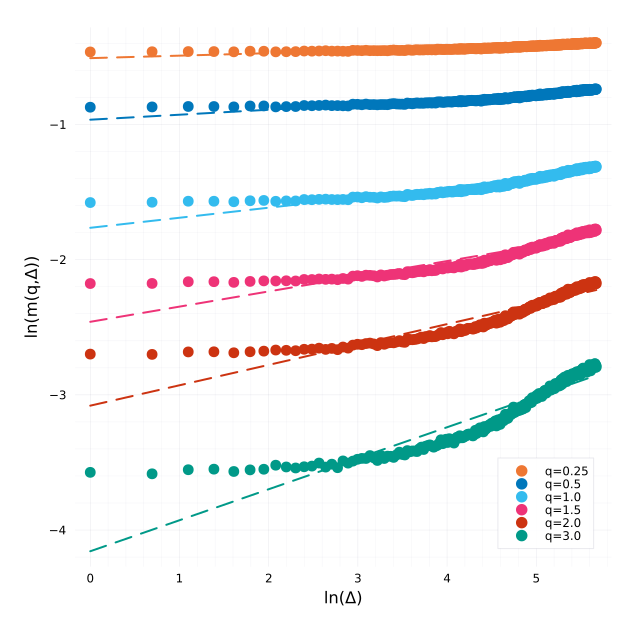
This is very visible with the Rosenbaum-Gatheral way of estimating H, we see that the observations do not fall on a line at all but flatten:
Regressions for each q based on the 1h realized variance.
The pure Heston model leads to similar observations.
I received a few e-mails asking me for the code I used to measure roughness in my preprint on the roughness of the implied volatility. Unfortunately, the code I wrote for this paper is not in a good state, it’s all in one long file line by line, not necessarily in order of execution, with comments that are only meaningful to myself.
In this post I will present the code relevant to measuring the oxford man institute roughness with Julia. I won’t go into generating Heston or rough volatility model implied volatilities, and focus only on the measure on roughness based on some CSV like input. I downloaded the oxfordmanrealizedvolatilityindices.csv from the Oxford Man Institute website (unfortunately now discontinued, data bought by Refinitiv but still available in some github repos) to my home directory
using DataFrames, CSV, Statistics, Plots, StatsPlots, Dates, TimeZones
df = DataFrame(CSV.File("/home/fabien/Downloads/oxfordmanrealizedvolatilityindices.csv"))
df1 = df[df.Symbol.==".SPX",:]
dsize = trunc(Int,length(df1.close_time)/1.0)
tm = [abs((Date(ZonedDateTime(String(d),"y-m-d H:M:S+z"))-Date(ZonedDateTime(String(dfv.Column1[1]),"y-m-d H:M:S+z"))).value) for d in dfv.Column1[:]];
ivm = dfv.rv5[:]
using Roots, Statistics
function wStatA(ts, vs, K0,L,step,p)
bvs = vs # big.(vs) bts = ts # big.(ts) value = sum( abs(log(bvs[k+K0])-log(bvs[k]))^p / sum(abs(log(bvs[l+step])-log(bvs[l]))^p for l in k:step:k+K0-step) * abs((bts[k+K0]-bts[k])) for k=1:K0:L-K0+1)
return value
endfunction meanRoughness(tm, ivm, K0, L)
cm = zeros(length(tm)-L);
for i =1:length(cm)
local ivi = ivm[i:i+L]
local ti = tm[i:i+L]
T = abs((ti[end]-ti[1]))
try cm[i] =1.0/ find_zero(p -> wStatA(ti, ivi, K0, L, 1,p)-T,(1.0,100.0))
catch e
ifisa(e, ArgumentError)
cm[i] =0.0else throw(e)
endendend meanValue = mean(filter( function(x) x >0end,cm))
stdValue = std(filter( function(x) x >0end,cm))
return meanValue, stdValue, cm
endmeanValue, stdValue, cm = meanRoughness(tm, ivm, K0,K0^2)
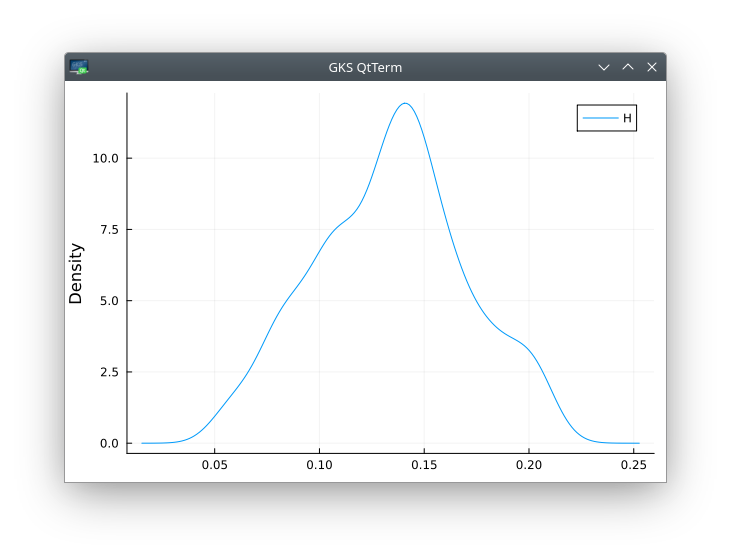
density(cm,label="H",ylabel="Density")
The last plot should look like
It may be slightly different, depending on the date (and thus the number of observations) of the CSV file (the ones I found on github are not as recent as the one I used initially in the paper).
I was experimenting with the recent SABR basket approximation of Hagan. The approximation only works
for the normal SABR model, meaning beta=0 in SABR combined with the Bachelier option formula.
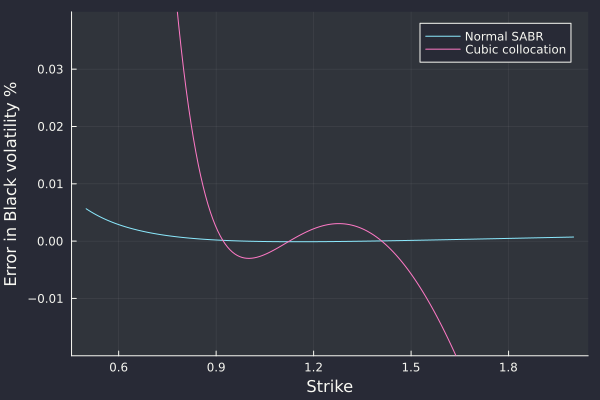
I was wondering how good the approximation would be for two flat smiles (in terms of Black volatilities). I then noticed something that escaped me before: the normal SABR model is able to fit the pure Black model (with constant vols) extremely well. A calibration near the money stays valid very out-of-the-money and the error in Black volatilities is very small.
For very low strikes (25%) the error in vol is below one basis point. And in fact, for a 1 year option of vol 20%, the option value is extremely small: we are in deep extrapolation territory.
It is remarkable that a Bachelier smile formula with 3 free parameters can fit so well the Black vols. Compared to stochastic collocation on a cubic polynomial (also 3 free parameters), the fit is 100x better with the normal SABR.
Error in fit against 10 vanilla options of maturity 1 year and volatility 20% within strike range [0.89, 1.5] .