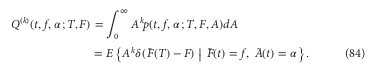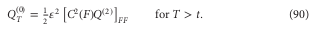In his book "Monte Carlo Methods in Finance", P. Jäckel explains a simple way to clean up a correlation matrix. When a given correlation matrix is not positive semi-definite, the idea is to do a singular value decomposition (SVD), replace the negative eigenvalues by 0, and renormalize the corresponding eigenvector accordingly.
One of the cited applications is "stress testing and scenario analysis for market risk" or "comparative pricing in order to ascertain the extent of correlation exposure for multi-asset derivatives", saying that "In many of these cases we end up with a matrix that is no longer positive semi-definite".
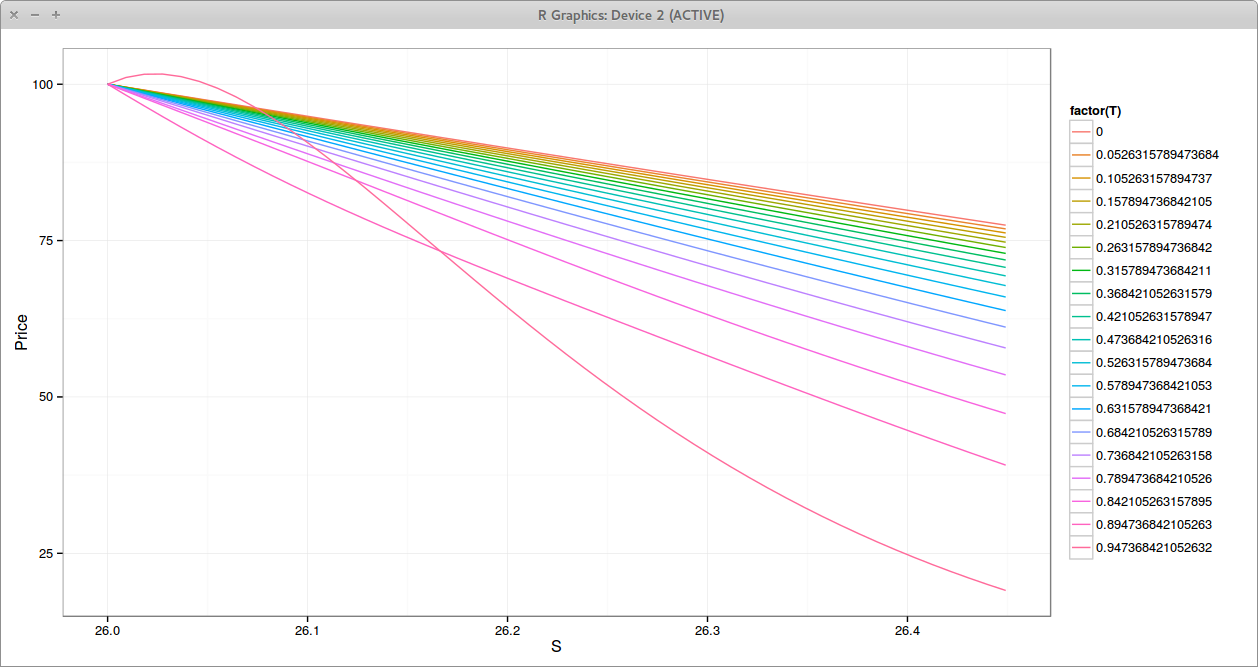
It turns out that if one bumps an invalid correlation matrix (the input), that is then cleaned up automatically, the effect can be a very different bump. Depending on how familiar you are with SVD, this could be more or less obvious from the procedure,
As a simple illustration I take the matrix representing 3 assets A, B, C with rho_ab = -0.6, rho_ac = rho_bc = -0.5.
For those rho_ac and rho_bc, the correlation matrix is not positive definite unless rho_ab in in the range (-0.5, 1). One way to verify this is to use the fact that positive definiteness is equivalent to a positive determinant. The determinant will be 1 - 2*0.25 - rho_ab^2 + 2*0.25*rho_ab.
It turns out that rho_bc has changed by only 0.66% and rho_ac by -0.30%, rho_ab by -0.34%. So our initial bump (0,0,1) has been translated to a bump (-0.34, -0.30, 0.66). In other words, it does not work to compute sensitivities.
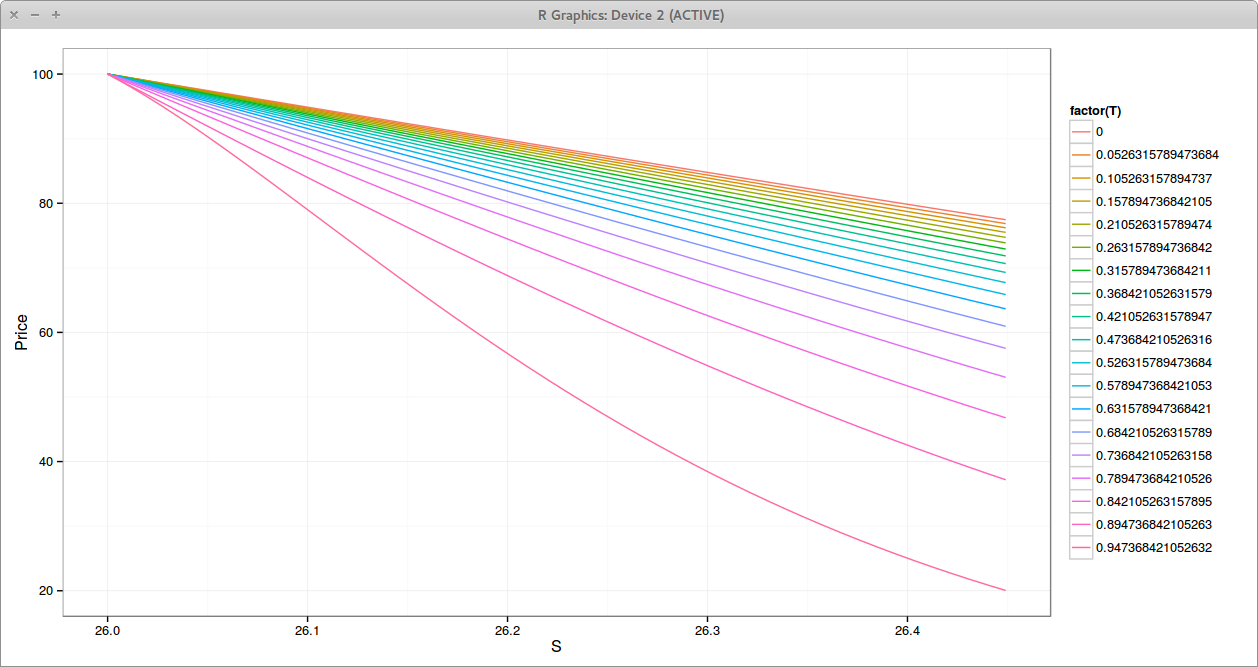
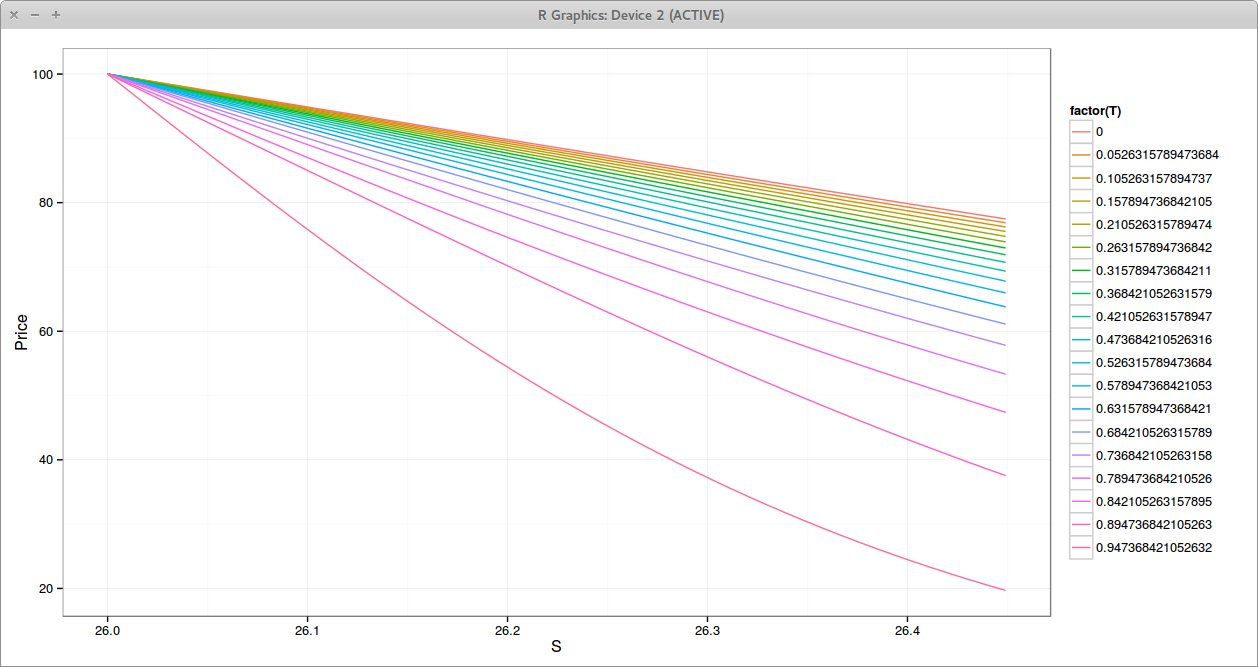
One can optimize to obtain the nearest correlation matrix in some norm. Jaeckel proposes a hypersphere decomposition based optimization, using as initial guess the SVD solution. Higham proposed a specific algorithm just for that purpose. It turns out that on this example, they will converge to the same solution (if we use the same norm). I tried out of curiosity to see if that would lead to some improvement. The first matrix becomes
We find back the same issue, rho_bc has changed by only 0.67%, rho_ac by -0.31% and rho_ab by -0.33%. We also see that the SVD correlation or the real near correlation matrix are quite close, as noticed by P. Jaeckel.
Of course, one should apply the bump directly to the cleaned up matrix, in which case it will actually work as expected, unless our bump produces another non positive definite matrix, and then we would have correlation leaking a bit everywhere. It's not entirely clear what kind of meaning the risk figures would have then.
There are not many arbitrage free extrapolation schemes. Benaim et al. extrapolation is one of the few that claims it. However, despite the paper’s title, it is not truely arbitrage free. The density might be positive, but the forward is not preserved by the implied density. It can also lead to wings that don’t obey Lee’s moments condition.
On a Wilmott forum, P. Caspers proposed the following counter-example based on extrapolating SABR: \( \alpha=15%, \beta=80%, \nu=50%, \rho=-48%, f=3%, T=20.0 \). He cut this smile at 2.5% and 6% and used the BDK extrapolation scheme with mu=nu=1.
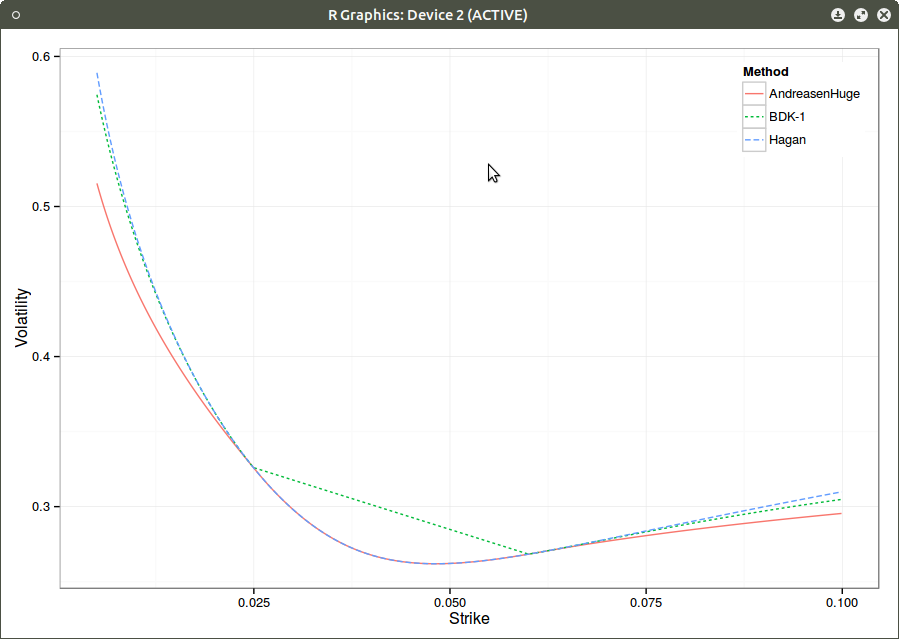
A truly arbitrage free extrapolation can be obtained through Andreasen Huge volatility interpolation, making sure the grid is wide enough to allow extrapolation. Their method is basically a one step finite difference implicit Euler scheme applied to a local volatility parameterization that has as many parameters than prices. The method is presented with piecewise constant local volatility, but actually used with piecewise linear local volatility in their example.
Smile.
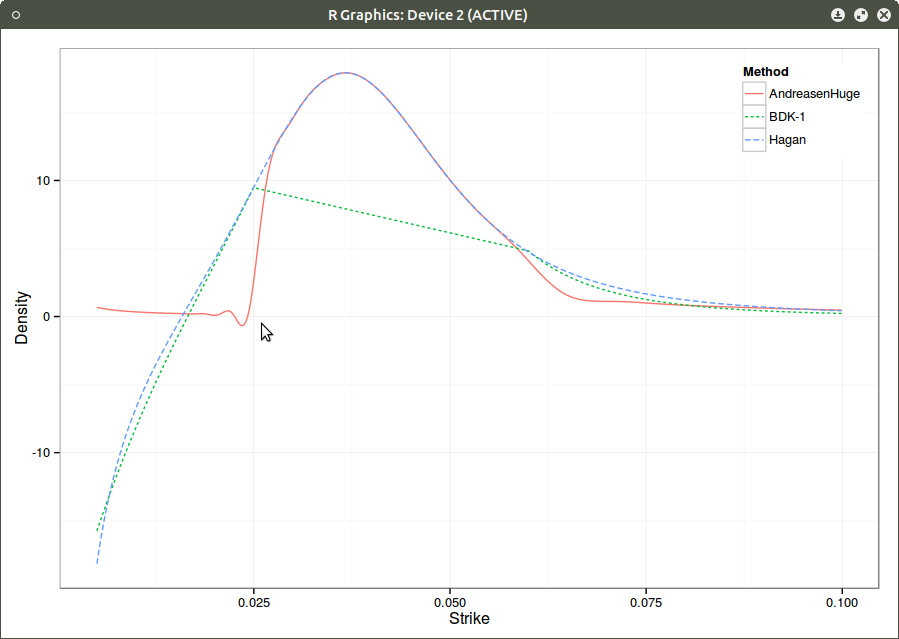
Density with piecewise linear local volatility.
There is still a tiny oscillation that makes the density negative, but one understands why typical extrapolations fail on the example: the change in density must be very steep.
Note that moving the left extrapolation point even closer to the forward might fix BDK negative density, but we are already very close, and we can really wonder if going closer is really a good idea since we would effectively use a somewhat arbitrary extrapolation in most of the interpolation zone.
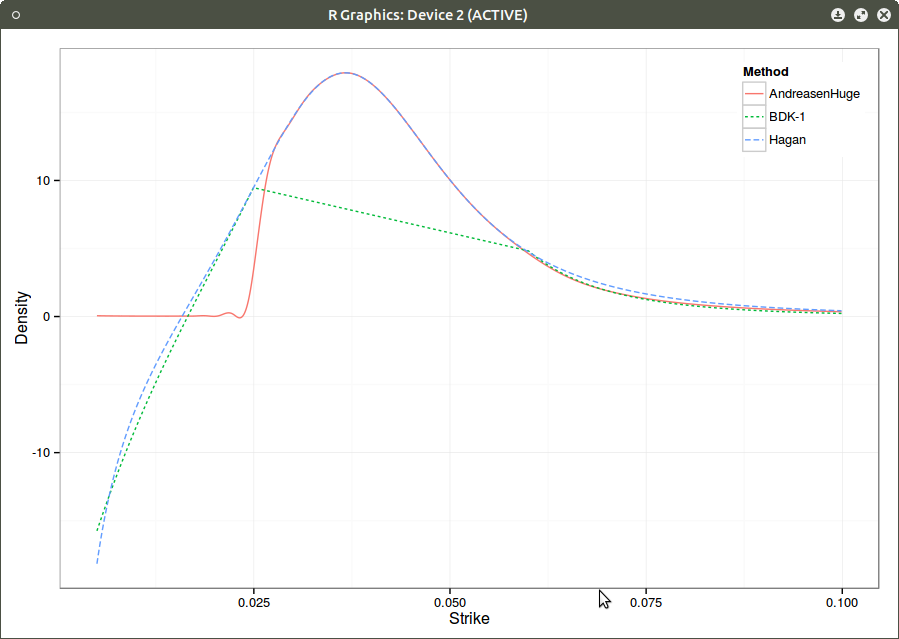
It turns out that we can also use a cubic spline local volatility with linear extrapolation, and the density would look then:
Density with cubic spline local volatility.
Interestingly, the right side of the density is much better captured.
The wiggle persists, although it is smaller. This is likely due to the fact that I am using a cubic spline on top of the finite difference prices (in order to have a C2 density). Using a better C2 convexity preserving interpolation would likely remove this artefact.
Those figures also show why relying just on extrapolation to fix SABR is not necessarily a good idea: even a real arbitrage free extrapolation will make a not so meaningful density. The proper solution is to really use Hagan’s arbitrage free SABR PDE, which would be as nearly fast in this case.
I am looking at various extrapolation schemes of the implied volatilities. An interesting one I stumbled upon is due to Kahale. Even if his paper is on interpolation, there is actually a small paragraph on using the same kind of function for extrapolation. His idea is to simply lookup the standard deviation \( \Sigma \) and the forward \(f\) corresponding to a given market volatility and slope:
$$ c_{f,\Sigma} = f N(d_1) - k N(d_2)$$
with
$$ d_1 = \frac{\log(f/k)+\Sigma^2 /2}{\Sigma} $$
We have simply:
$$ c’(k) = - N(d_2)$$
He also proves that we can always find those two parameters for any \( k_0 > c_0 > 0, -1 < c_0’ < 0 \)
Then I had the silly idea of trying to match with a put instead of a call for the left wing (as those are out-of-the-money, and therefore easier to invert numerically). It turns out that it works in most cases in practice and produces relatively nice looking extrapolations, but it does not always work. This is because contrary to the call, the put value is bounded with \(f\).
$$ p_{f,\Sigma} = k N(-d_2) - f N(-d_1)$$
Inverting \( p_0’ \) is going to lead to a specific \( d_2 \), and you are not guaranteed that you can push \( f \) high and have \( p_{f, \Sigma} \) large enough to match \( p_0 \). As example we can just take \(p_0 \geq k N(-d_2)\) which will only be matched if \( f \leq 0 \).
This is slightly unintuitive as put-call parity would suggest some kind of equivalence. The problem here is that we would need to consider the function of \(k\) instead of \(f\) for it to work, so we can’t really work with a put directly.
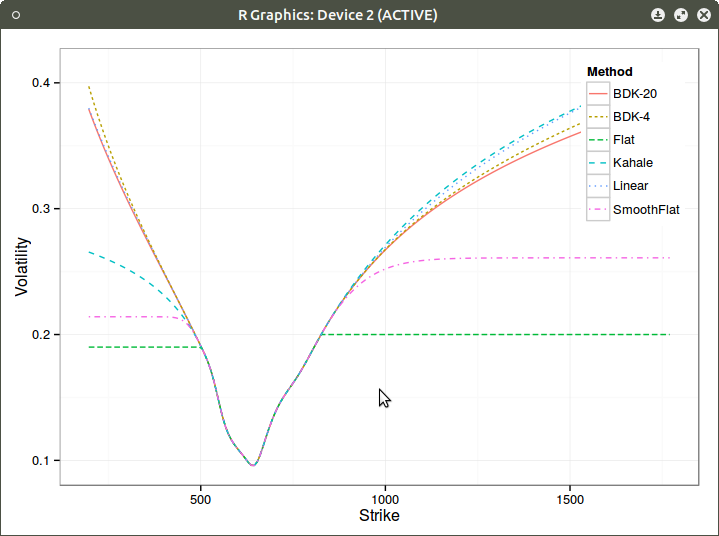
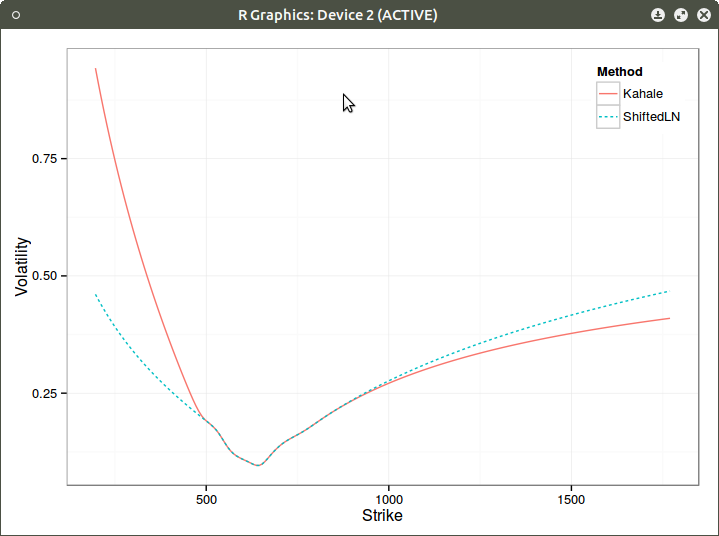
Here are the two different extrapolations on Kahale own example:
Window Extrapolation of the left wing with calls (blue doted line)
Extrapolation of the left wing with puts (blue doted line)
Displaced diffusion extrapolation is sometimes advocated. It is not the same as Kahale extrapolation: In Kahale, only the forward variable is varying in the Black-Scholes formula, and there is no real underlying stochastic process. In a displaced diffusion setting, we would adjust both strike and forward, keeping put-call parity at the formula level. But unfortunately, it suffers from the same kind of problem: it can not always be solved for slope and price. When it can however, it will give a more consistent extrapolation.
I find it interesting that some smiles can not be extrapolated by displaced diffusion in a C1 manner except if one allows negative volatilities in the formula (in which case we are not anymore in a pure displaced diffusion setting).
Extrapolation of the left wing using negative displaced diffusion volatilities (blue dotted line)
sometimes (rarely) my laptop would not wake up from sleep.
notifications sometimes keep popping up too much.
on my desktop, experienced strong tearing issues with the Radeon graphic card, except with some very specific combination of video player settings and desktop settings (and then I had annoying redraw issue when pushing volume up/down in movies).
I am satisfied with two different approaches since:
OpenSuse 13.2 with KDE 4. I use that on my desktop, all issues are gone, and the integration of KDE in OpenSuse is clearly the best I have experienced. In contrast, KDE 5 on Ubuntu was a disaster for me. I also managed to fuck up the apt dependencies so much that I thought it would be simpler to reinstall a new distribution.
Mate on Ubuntu 15.04. Very impressed so far. It’s probably what Gnome should have been instead of going to 3.0. Even if there are nice aspects of the Gnome shell, Mate is fast, pretty, user friendly, much better than Cinnamon. There are even a few layouts to choose (most of them are good), here is “Eleven with Mate menu” (it installed and setup the Plank dock automatically for that layout, more traditional layouts without dock are available):
C. Reisinger kindly pointed out to me this paper around square root Crank-Nicolson. The idea is to apply a square root of time transformation to the PDE, and discretize the resulting PDE with Crank-Nicolson. Two reasons come to mind to try this:
the square root transform will result in small steps initially, where the solution is potentially not so smooth, making Crank-Nicolson behave better.
it is the natural time of the Brownian motion.
Interestingly, it has nicer properties than what those reasons may suggest. On the Fokker-Planck density PDE, it does not oscillate under some very mild conditions and preserves density positivity at the peak.
Out of curiosity I tried it to price a one touch barrier option. Of course there is an analytical solution in my test case (Black-Scholes assumptions), but as soon as rates are assumed not constant or local volatility is used, there is no other solution than a numerical method. In the later case, finite difference methods are quite good in terms of performance vs accuracy.
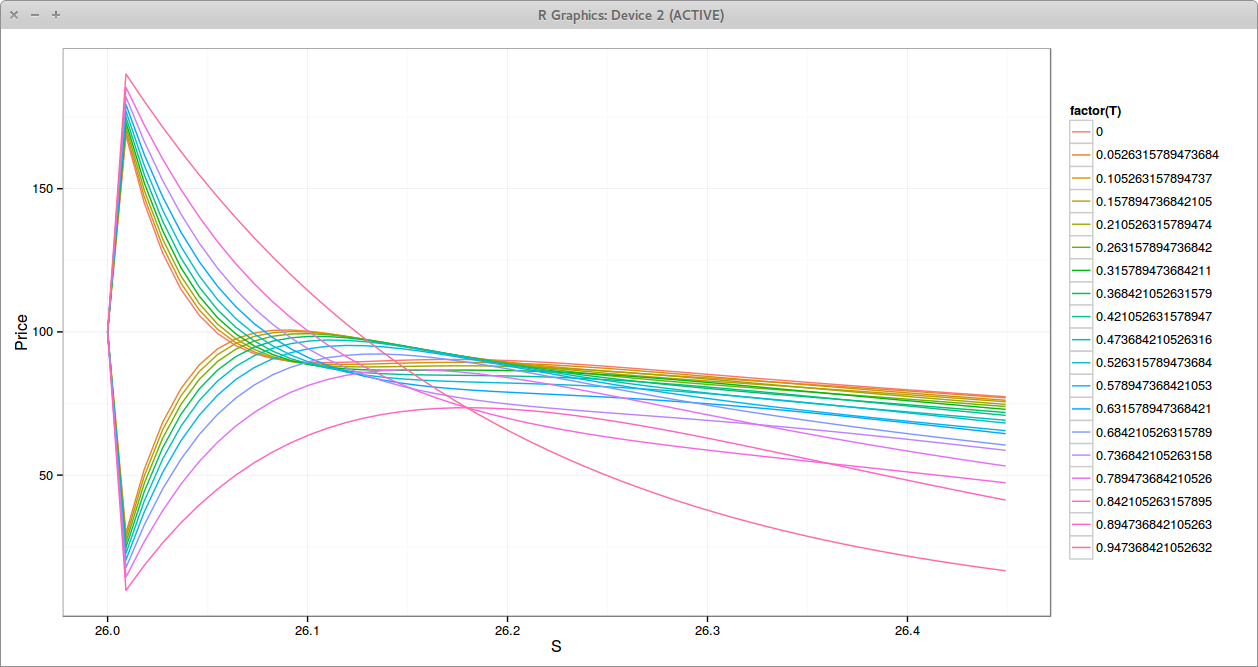
The classic Crank-Nicolson gives a reasonable price, but the strong oscillations near the barrier, at every time step are not very comforting.
Crank-Nicolson Prices near the Barrier. Each line is a different time.
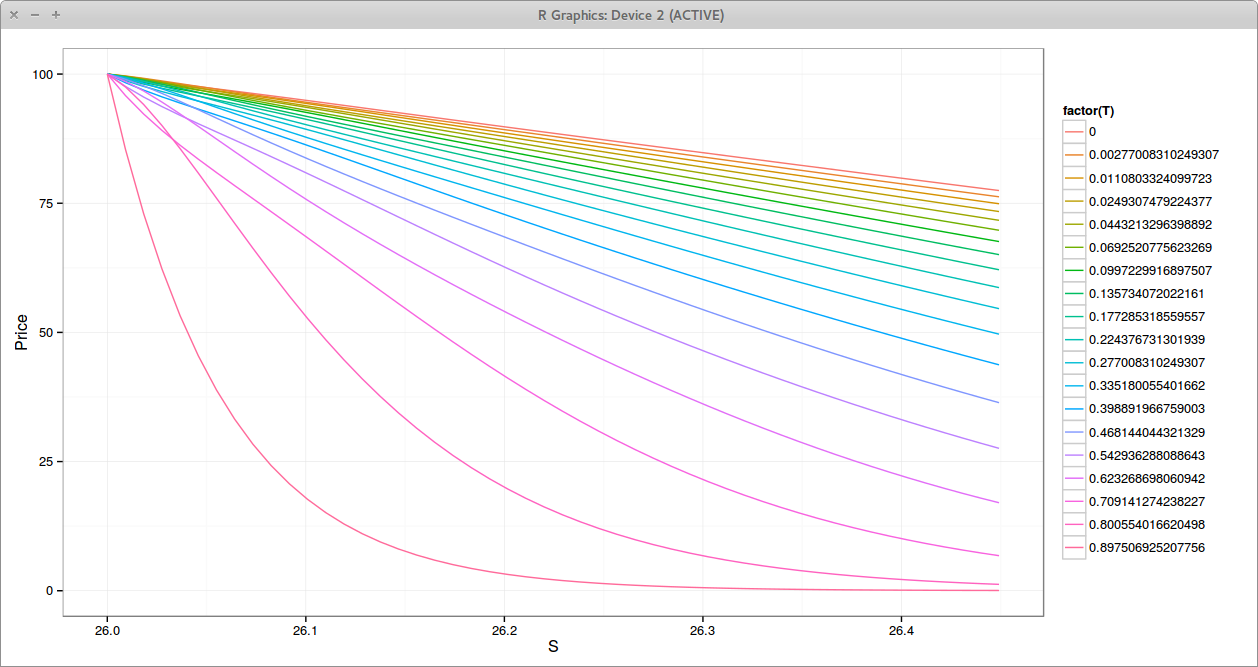
Moving to square root of time removes nearly all oscillations on this problem, even with a relatively low number of time steps compared to the number of space steps.
Square Root Crank-Nicolson Prices near the Barrier. Each line is a different time.
We can see that the second step prices are a bit higher than the third step (the lines cross), which looks like a small numerical oscillation in time, even if there is no oscillation is space.
TR-BDF2 Prices near the Barrier. Each line is a different time.
As a comparison, the TR-BDF2 scheme does relatively well: oscillations are removed after the second step, even with the extreme ratio of time steps vs space steps used on this example so that illustrations are clearer - Crank-Nicolson would still oscillate a lot with 10 times less space steps but we would not see oscillation on the square root Crank-Nicolson and a very mild one on TR-BDF2.
The LMG2 scheme (a local richardson extrapolation) does not oscillate at all on this problem but is the slowest:
LMG2 Prices near the Barrier. Each line is a different time.
The square root Crank-Nicolson is quite elegant. It can however not be applied to that many problems in practice, as often some grid times are imposed by the payoff to evaluate, for example in a case of a discrete weekly barrier. But for continuous time problems (density PDE, Vanilla, American, continuous barriers) it's quite good.
In reality, with a continuous barrier, the payoff is not discontinuous at every step, but it is only discontinuous at the first step. So Rannacher smoothing would work very well on that problem:
Rannacher Prices near the Barrier. Each line is a different time.
The somewhat interesting payoff left for the square root Crank-Nicolson is the American.
Here are the main steps of Hagan derivation. Let's recall his notation for the SABR model where typically, \\(C(F) = F^\beta\\)
First, he defines the moments of stochastic volatility:
Then he integrates the Fokker-Planck equation over all A, to obtain
On the backward Komolgorov equation, he applies a Lamperti transform like change of variable:
And then makes another change of variable so that the PDE has the same initial conditions for all moments:
This leads to
It turns out that there is a magical symmetry for k=0 and k=2.
Note that in the second equation, the second derivative applies to the whole.
Because of this, he can express \\(Q^{(2)}\\) in terms of \\(Q^{(0)}\\):
And he plugs that back to the integrated Fokker-Planck equation to obtain the arbitrage free SABR PDE:
There is a simple more common explanation in the world of local stochastic volatility for what's going on. For example, in the particle method paper from Guyon-Labordère, we have the following expression for the true local volatility.
In the first equation, the numerator is simply \(Q^{(2)}\) and the denominator \(Q^{(0)}\). Of course, the integrated Fokker-Planck equation can be rewritten as:
Karlsmark uses that approach directly in his thesis, using the expansions of Doust for \(Q^{(k)}\). Looking a Doust expansions, the fraction reduces straightforwardly to the same expression as Hagan, and the symmetry in the equations appears a bit less coincidental.
I looked nearly two years ago already at the arbitrage free SABR of Andreasen-Huge in comparison to the arbitrage free PDE of Hagan and showed how close the ideas were: Andreasen-Huge relies on the normal Dupire forward PDE using a slightly simpler local vol (no time dependent exponential term) while Hagan works directly on the Fokker-Planck PDE (you can think of it as the Dupire Forward PDE for the density) and uses an expansion of same order as the original SABR formula (which leads to an additional exponential term in the local volatility).
One clever idea from Andreasen-Huge is the use of a single step. It turns out that their idea is not completely new. Daniel Duffy sent me some old papers from Shishkin around fitted schemes (here is one). This is very much the same thing, except Shishkin concern is about a good handling of discontinuity in the initial condition, and therefore makes the association step function => cumulative density to fit the diffusion parameter. Andreasen-Huge work directly with the call prices as this is what they solve.
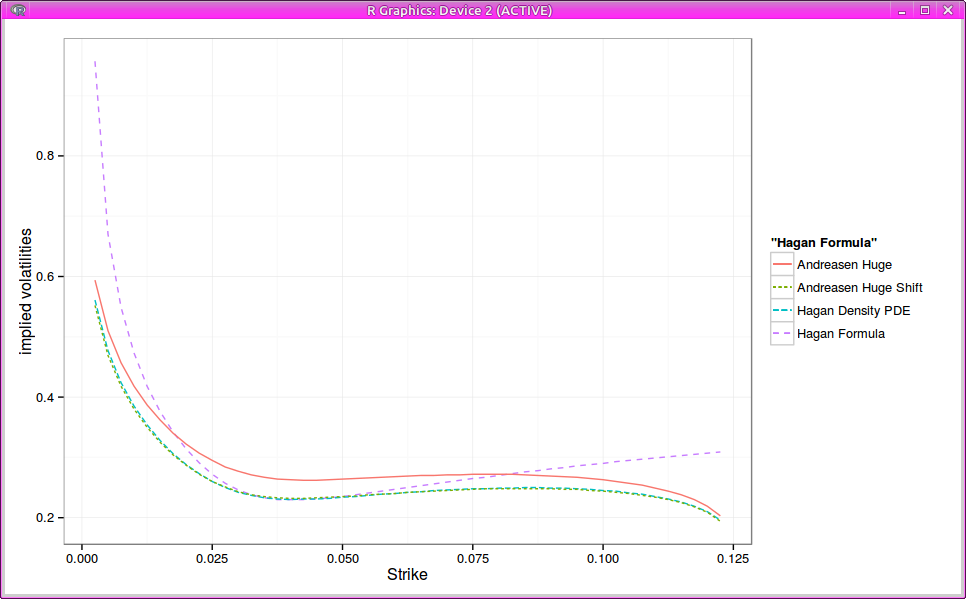
One drawback of Andreasen-Huge one step method is the inability to match the standard SABR smile: the parameters don’t have exactly the same meaning. It turns out that by just shifting proportionally the local volatility by a constant factor, Andreasen Huge matches Hagan PDE vols quite closely.
Implied Black volatilities
Probability density
While this is interesting in itself, it’s still not so simple to backup this factor without solving for it (and then the method looses appeal).
A few recent programming languages sparked my interest:
Julia because of the wide coverage of mathematical functions, and great attention to quality of the implementations. It has also some interesting web interface.
Dart: because it’s a language focused purely on building apps for the web, and has a supposedly good VM.
Rust: it’s the latest fad. It has interesting concepts around concurrency and a focus on being low level all the while being simpler than C.
I decided to see how well suited they would be on a simple Monte-Carlo simulation of a forward start option under the Black model. I am no expert at all in any of the languages, so this is a beginner’s test. I compared the runtime for executing 16K simulations times a multiplier.
Multipl.
Scala
Julia
JuliaA
Dart
Python
Rust
1
0.03
0.08
0.09
0.03
0.4
0.004
10
0.07
0.02
0.06
0.11
3.9
0.04
100
0.51
0.21
0.40
0.88
0.23
1000
4.11
2.07
4.17
8.04
2.01
About performance
I am quite impressed at Dart performance versus Scala (or vs. Java, as it has the same performance as Scala) given that it is much less strict about types and its focus is not at all on this kind of stuff.
Julia performance is great, that is if one is careful about types. Julia is very finicky about casting and optimizations, fortunately @time helps spotting the issues (often an inefficient cast will lead to copy and thus high allocation). JuliaA is my first attempt, with an implicit badly performing conversion of MersenneTwister to AbstractRNG. It is slower first, as the JIT costs is reflected on the first run, very much like in Java (although it appears to be even worse).
Rust is the most impressive. I had to add the –release flag to the cargo build tool to produce a properly optimized binary, otherwise the performance is up to 7x worse.<
About the languages
My Python code is not vectorized, just like any of the other implementations. While the code looks relatively clean, I made the most errors compared to Julia or Scala. Python numpy isn’t always great: norm.ppf is very slow, slower than my hand coded python implementation of AS241.
Dart does not have fixed arrays: everything is a list. It also does not have strict 64 bit int: they can be arbitrarily large. The dev environment is ok but not great.
Julia is a bit funny, not very OO (no object method) but more functional, although many OO concepts are there (type inheritence, type constructors). It was relatively straightforward, although I do not find intuitive the type conversion issues (eventual copy on conversion).
Rust took me the most time to write, as it has quite new concepts around mutable variables, and “pointers” scope. I relied on an existing MersenneTwister64 that worked with latest Rust. It was a bit disappointing to see that some dSFMT git project did not compile with the latest Rust, likely because Rust is still a bit too young. This does not sound so positive, but I found it to be the language the most interesting to learn.
I was familiar with Scala before this exercise. I used a non functional approach, with while loops in order to make sure I had maximum performance. This is something I find a bit annoying in Scala, I always wonder if for performance I need to do a while instead of a for, when the classic for makes much more sense (that and the fact that the classic for leads to some annoying delegation in runtime errors/on debug).
I relied on the default RNG for Dart but MersenneTwister for Scala, Julia, Python, Rust. All implementations use a hand coded AS241 for the inverse cumulative normal.
Update
Using FastMath.exp instead of Math.exp leads a slightly better performance for Scala:
Multipl.
Scala
1
0.06
10
0.05
100
0.39
1000
2.66
I did not expect that this would still be true in 2015 with Java 8 Oracle JVM.
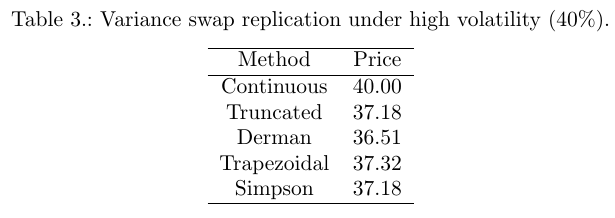
I have looked at jump effects on volatility vs. variance swaps. There is a similar behavior on tail events, that is, on truncating the replication. One main problem with discrete replication of variance swaps is the implicit domain truncation, mainly because the variance swap equivalent log payoff is far from being linear in the wings. The equivalent payoff with Carr-Lee for a volatility swap is much more linear in the wings (not so far of a straddle). So we could expect the replication to be less sensitive to the wings truncation.
I have done a simple test on flat 40% volatility:
As expected, the vol swap is much less sensitive, and interestingly, very much like for the jumps, it moves in the opposite direction: the truncated price is higher than the non truncated price.
Antonov et al. present an interesting view on SABR with negative rates: instead of relying on a shifted SABR to allow negative rates up to a somewhat arbitrary shift, they modify slightly the SABR model to allow negative rates directly:
$$ dF_t = |F_t|^\beta v_t dW_F $$
with \\( v\_t \\) being the standard lognormal volatility process of SABR.
Furthermore they derive a clever semi-analytical approximation for this model, based on low correlation, quite close to the Monte-Carlo prices in their tests. It's however not clear if it is arbitrage-free.
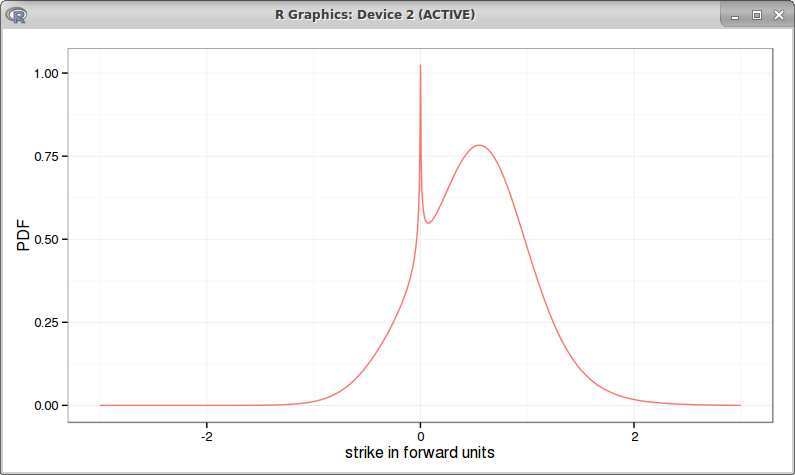
It turns out that it is easy to tweak Hagan SABR PDE approach to this "absolute SABR" model: one just needs to push the boundary \\(F\_{min}\\) far away, and to use the absolute value in C(F).
It then reproduces the same behavior as in Antonov et al. paper:
"Absolute SABR" arbitrage free PDE
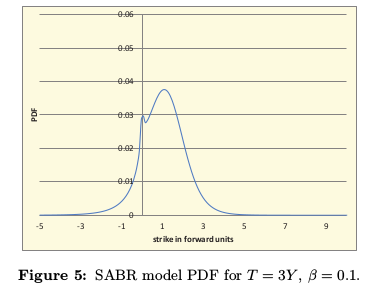
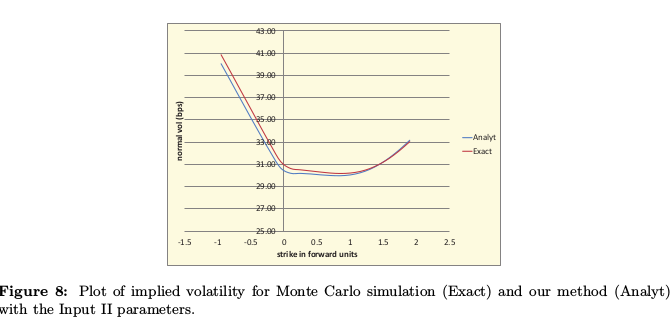
Antonov et al. graph
I obtain a higher spike, it would look much more like Antonov graph had I used a lower resolution to compute the density: the spike would be smoothed out.
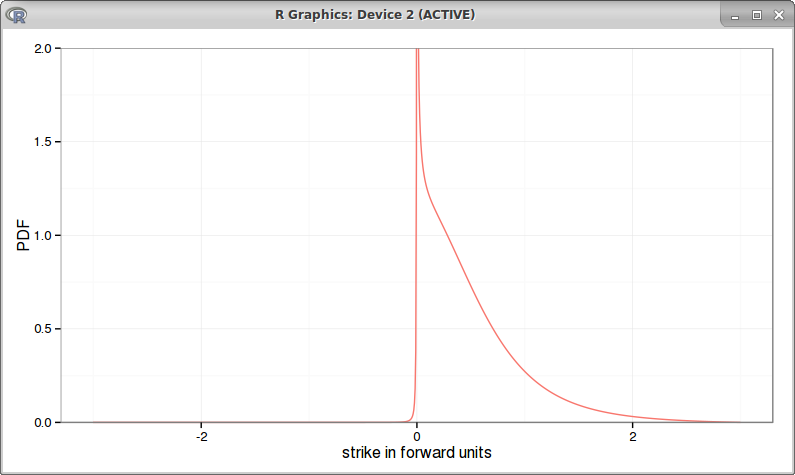
Interestingly, the arbitrage free PDE will also work for high beta (larger than 0.5):
beta = 0.75
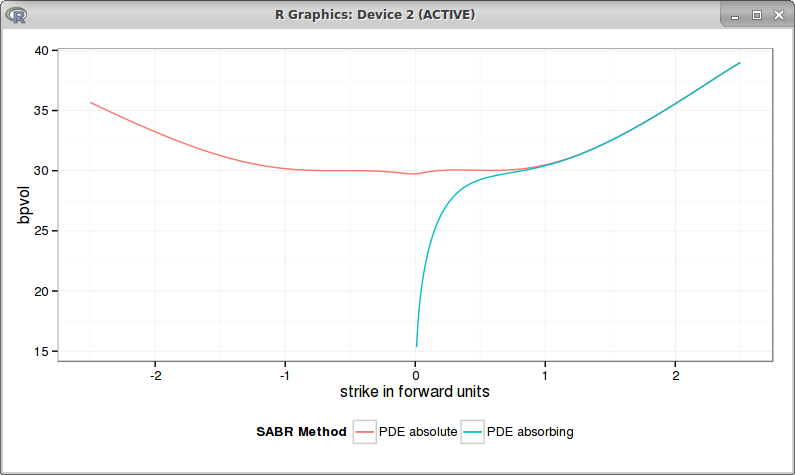
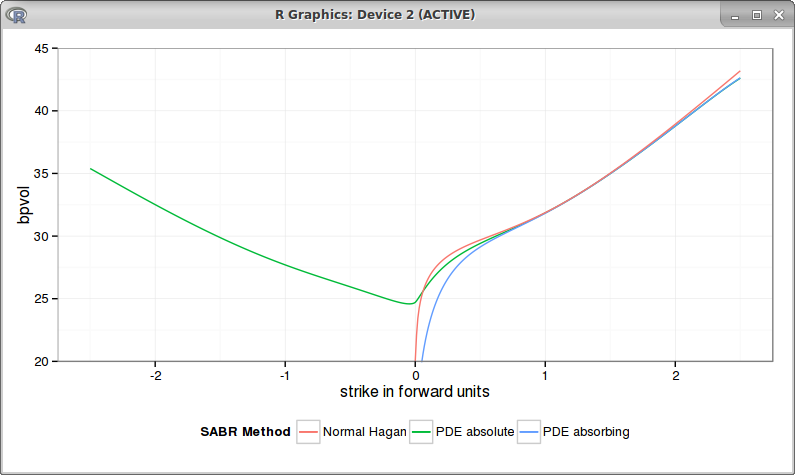
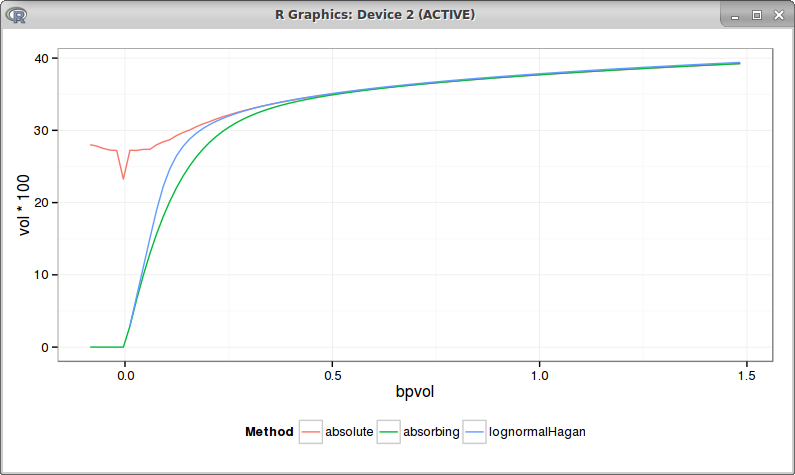
It turns out to be then nearly the same as the absorbing SABR, even if prices can cross a little the 0. This is how the bpvols look like with beta = 0.75:
red = absolute SABR, blue = absorbing SABR with beta=0.75
They overlap when the strike is positive.
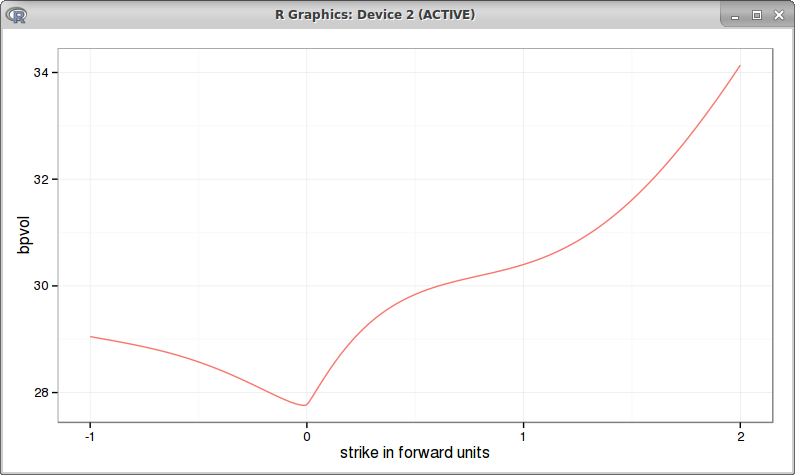
If we go back to Antonov et al. first example, the bpvols look a bit funny (very symmetric) with beta=0.1:
For beta=0.25 we also reproduce Antonov bpvol graph, but with a lower slope for the left wing:
bpvols with beta = 0.25
It's interesting to see that in this case, the positive strikes bp vols are closer to the normal Hagan analytic approximation (which is not arbitrage free) than to the absorbing PDE solution.
For longer maturities, the results start to be a bit different from Antonov, as Hagan PDE relies on a order 2 approximation only:
absolute SABR PDE with 10y maturity
The right wing is quite similar, except when it goes towards 0, it's not as flat, the left wing is much lower.
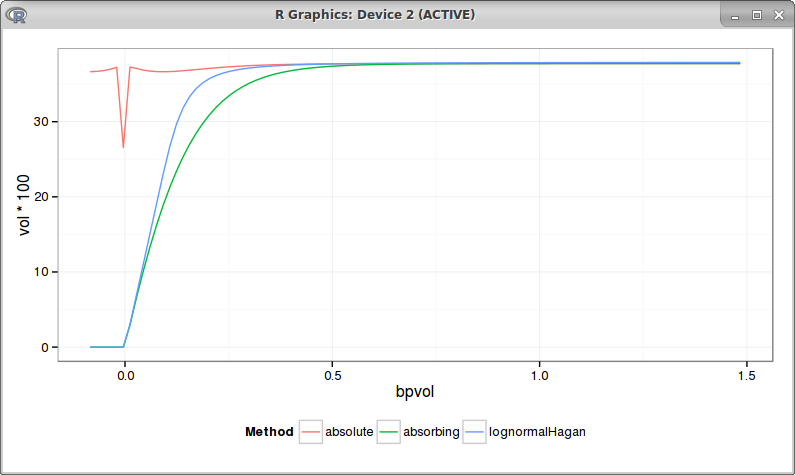
Another important aspect is to reproduce Hagan's knee, the atm vols should produce a knee like curve, as different studies show (see for example this recent Hull & White study or this other recent analysis by DeGuillaume). Using the same parameters as Hagan (beta=0, rho=0) leads to a nearly flat bpvol: no knee for the absolute SABR, curiously there is a bump at zero, possibly due to numerical difficulty with the spike in the density:
The problem is still there with beta = 0.1:
Overall, the idea of extending SABR to the full real line with the absolute value looks particularly simple, but it's not clear that it makes real financial sense.