We will assume zero interest rates and no dividends on the asset \(S\) for clarity.
The results can be easily generalized to the case with non-zero interest rates and dividends.
Under those assumptions, the Black-Scholes PDE is:
$$ \frac{\partial V}{\partial t} + \frac{1}{2}\sigma^2 S^2 \frac{\partial^2 V}{\partial S^2} = 0.$$
An implicit Euler discretisation on a uniform grid in \(S\) of width \(h\) with linear boundary conditions (zero Gamma) leads to:
$$ V^{k+1}_i - V^{k}_i = \frac{1}{2}\sigma^2 \Delta t S_i^2 \frac{V^{k}_{i+1}-2V^k_{i}+V^{k}_{i-1}}{h^2}.$$
for \(i=1,…,m-1\) with boundaries
$$ V^{k+1}_i - V^{k}_i = 0.$$
for \(i=0,m\).
This forms a linear system \( M \cdot V^k = V^{k+1} \) with \(M\) is a tridiagonal matrix where each of its rows sums to 1 exactly.
Furthermore, the payoff corresponding to the forward price \(V_i = S_i\) is exactly preserved as well by such a system as the discretized second derivative will be exactly zero.
The scheme can be seen as preserving the zero-th and first moments.
As a consequence, by linearity, the put-call parity relationship will hold exactly (note that in between nodes, any interpolation used should also be consistent with the put-call parity for the result to be more general).
This result stays true for a non-uniform discretisation, and with other finite difference schemes as shown in this paper.
It is common to consider the log-transformed problem in \(X = \ln(S)\) as the diffusion is constant then, and a uniform grid much more adapted to the process.
$$ \frac{\partial V}{\partial t} + \frac{1}{2}\sigma^2 \frac{\partial^2 V}{\partial X^2}-\frac{1}{2}\sigma^2 \frac{\partial V}{\partial X} = 0.$$
An implicit Euler discretisation on a uniform grid in \(X\) of width \(h\) with linear boundary conditions (zero Gamma in \(S\) ) leads to:
$$ V^{k+1}_i - V^{k}_i = \frac{1}{2}\sigma^2 \Delta t \frac{V^{k}_{i+1}-2V^k_{i}+V^{k}_{i-1}}{h^2}-\frac{1}{2}\sigma^2 \Delta t \frac{V^{k}_{i+1}-V^{k}_{i-1}}{2h}.$$
for \(i=1,…,m-1\) with boundaries
$$ V^{k+1}_i - V^{k}_i = 0.$$
for \(i=0,m\).
Such a scheme will not preserve the forward price anymore. This is because now, the forward price is \(V_i = e^{X_i}\). In particular, it is not linear in \(X\).
It is possible to preserve the forward by changing slightly the diffusion coefficient, very much as in the exponential fitting idea. The difference is that, here, we are not interested
in handling a large drift (when compared to the diffusion) without oscillations, but merely to preserve the forward exactly.
We want the adjusted volatility \(\bar{\sigma}\) to solve
$$\frac{1}{2}\bar{\sigma}^2 \frac{e^{h}-2+e^{-h}}{h^2}-\frac{1}{2}\sigma^2 \frac{e^{h}-e^{-h}}{2h}=0.$$
Note that the discretised drift does not change, only the discretised diffusion term. The solution is:
$$\bar{\sigma}^2 = \frac{\sigma^2 h}{2} \coth\left(\frac{h}{2} \right) .$$
This needs to be applied only for \(i=1,…,m-1\).
This is actually the same adjustment as the exponential fitting technique with a drift of zero. For a non-zero drift, the two adjustments would differ, as the exact forward adjustment will stay the same, along with an adjusted discrete drift.
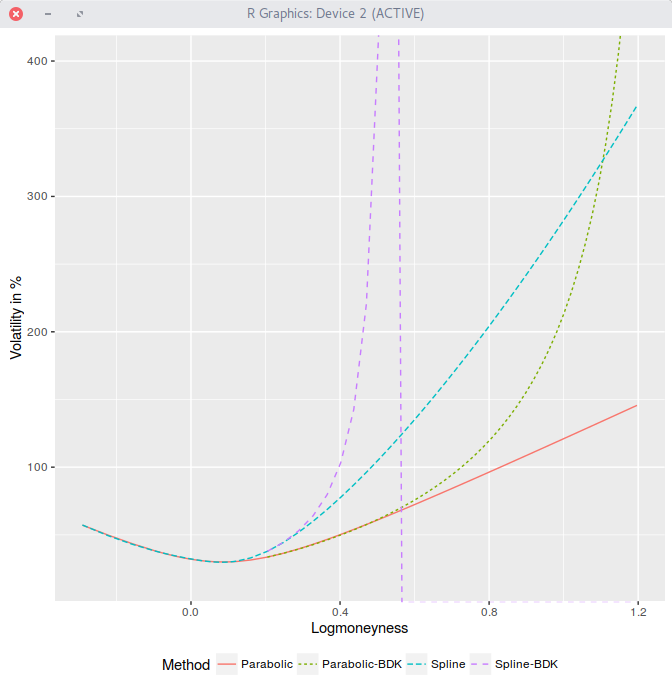
We have seen earlier that a simple parabola allows to capture the smile of AAPL 1m options surprisingly well. For very high and very low strikes,
the parabola does not obey Lee’s moments formula (the behavior in the wings needs to be at most linear in variance/log-moneyness).
Extrapolating the volatility smile in the low or high strikes in a smooth \(C^2\) fashion is however not easy.
A surprisingly popular so called “arbitrage-free”
method is the extrapolation of Benaim, Dodgson and Kainth developed to remedy the negative density of SABR in interest rates as
well as to give more control over the wings.
The call options prices (right wing) are extrapolated as:
$$
C(K) = \frac{1}{K^\nu} e^{a_R + \frac{b_R}{K} + \frac{c_R}{K^2}} \text{.}
$$
\(C^2\) continuity conditions for the right wing at strike \(K_R\) lead to:
$$
c_R =\frac{{C’}_R}{C_R}K_{R}^3+ \frac{1}{2}K_{R}^2 \left(K_{R}^2 \left(- \frac{{C’}_{R}^{2}}{C_{R}^2}+ \frac{{C’’}_R}{C_R}\right) + \nu \right)\text{,} \
$$
$$
b_R = - \frac{{C’}_R}{C_R} K_R^2 - \nu K_R-2 \frac{c_R}{K_R}\text{,}\
$$
$$
a_R = \log(C_R)+ \nu \log(K_R) - \frac{b_R}{K_R} - \frac{c_R}{K_{R}^2}\text{.}
$$
The \( \ nu \) parameters allow to adjust the shape of the extrapolation.
Unfortunately it does not really work for equities.
Very often, the extrapolation will explode, which is what we wanted to avoid in the first place. We illustrate it here on
our best fit parabola of the AAPL 1m options:
BDK explodes on AAPL 1m options.
The \( \nu\) parameter does not help either.
Update Dec 5 2016
Here are details about call option price, slope, curvature:
The strike cutoff is \(K_R=115.00001307390328\). For the parabola,
For the least squares spline,
$$\begin{align}
C(K_R)&=0.03892674300426042,\\
C’(K_R)&=-0.00171386452499034,\\
C’’(K_R)&=0.0007835686926501496.
\end{align}$$
which results in
$$a_R=131.894286, b_R=-26839.217814, c_R=1550285.706087.$$
In finance, and also in science, the Mersenne-Twister is the de-factor pseudo-random number generator (PRNG) for Monte-Carlo simulations.
By the way, there is a recent 64-bit maximally equidistributed version called MEMT19937 with 53-bit double precision floating point numbers in mind.
Historicaly, counter-based PRNGs based on cryptographic standards such as AES
were historically slow, which motivated the development of sequential PRNGs with good statistical properties,
yet not cryptographically strong like the Mersenne Twister for Monte-Carlo simulations.
The randomness of AES is of vital importance to its security making the use of the AES128 encryption algorithm as PRNG sound (see Hellekalek & Wegenkittl paper).
Furthermore, D.E. Shaw study shows that AES can be faster than Mersenne-Twister.
In my own simple implementation using the standard library of the Go language,
it was around twice slower than Mersenne-Twister to generate random double precision floats,
which can result in a 5% performance loss for a local volatility simulation.
The relative slowness could be explained by the type of processor used, but it is still competitive for Monte-Carlo use.
The code is extremely simple, with many possible variations around the same idea. Here is mine
Interestingly, the above code was 40% faster with Go 1.7 compared to Go 1.6, which resulted in a local vol Monte-Carlo simulation performance improvement of around 10%.
The stream cipher Salsa20 is another possible candidate to use as counter-based PRNG.
The algorithm has been selected as a Phase 3 design in the 2008 eSTREAM project organised by the European Union ECRYPT network,
whose goal is to identify new stream ciphers suitable for widespread adoption.
It is faster than AES in the absence of specific AES CPU instructions.
Our tests run with a straightforward implementation that does not make use of specific AMD64 instructions
and show the resulting PRNG to be faster than MRG63k3a and only 5% slower than MEMT19937 for local volatility Monte-Carlo simulations, that is the same speed as the above Go AES PRNG.
While it led to sensible results, there does not seem any study yet of its equidistribution properties.
Counter-based PRNGs are parallelizable by nature: if a counter is used as plaintext,
we can generate any point in the sequence at no additional cost by just setting
the counter to the point position in the sequence, the generator is not sequential.
Furthermore, alternate keys can be used to create independent substreams:
the strong cryptographic property will guarantee the statistical independence.
A PRNG based on AES will allow \(2^{128}\) substreams of period \(2^{128}\).
I found back some old notes I had written about the book “Le capital au XXI siecle” from Thomas Piketty. It took me a while to finish that book last summer.
So many journalists have written around Piketty, that I had to buy the book and read it. It turns out that some of the criticism I have read is not really founded once one reads the book, but here are other real obvious criticisms that I suprisingly did not hear.
The best part of the book is probably the introduction. It’s actually not so short and gives a good overall view of the main subjects of the book. But it’s a bit too concise to truely understand the point. Unfortunately as the book progresses, it feels more like someone trying to fill up empty pages than real content. The first half of the first chapter is still interesting, and then we are overwhelmed with too many graphs and even more words to just state the obvious in the graph, or to repeat over and over the same idea. His economic “laws” should really be summarized on one (or two) simple page, there is no need for hundreds of pages to understand them. Banks could learn a bit of basic statistics: Piketty makes the point of not considering only one measure of inequality like the Gini index, very much like banks should not consider only one measure of risk like the VaR.
The title is clever, as it is a direct reference to Marx “The Capital”, but it’s very far from the quality of Marx book. Marx can be wrong about many things, but in each chapter, he presents new ideas, a different way of looking at the problem. There is a real philosophical effort of defining the meaning of words, and there is fascinating analysis of the economic world of the 19th century. I am refering to the first volume, the only one Marx truly wrote.
I hardly understand why Piketty is so popular in the US. I remember how much fun it was to read Adam Smith “The Wealth of Nations”, and again how different perpectives it tries to bring, and it’s no small book either. Piketty is boring, extremely boring to read (except the intro). Maybe the Americans just stopped at the introduction. Likely it has more to do with Piketty being the intellectual defending the same ideas as the very popular Occupy movement (which we somehow don’t hear about so much anymore). Bourdieu was very talented in mixing the right amount of statistics with extremely original views along with a philosophical stance. I expected more from Piketty, an admirer of the likes of Bourdieu.
A much more interesting book would be something like a spiced up introduction to this book. One main leitmotiv is the fact that the 21st century will not look like the 20th century, but maybe more like the 19th century. Why wouldn’t the 21st century look like the 21st century, that is different from the 20th and the 19th century? Still, where Picketty is interesting is in the fact that there is something to learn from the 19th century economics, and something to unlearn from the 20th century economics which might be too prevalent today.
Last year, I was kindly invited at the workshop on Models and Numerics in Financial Mathematics at the Lorentz center.
It was surprinsgly interesting on many different levels. Beside the relatively large gap between academia and the industry, which this
workshop was trying to address, one thing that struck me is how difficult it was for people of slightly different specialties to communicate.
It seemed that mathematicians of different countries working on different subjects related to backward stochastic differential equations (BSDEs) would not truly understand each other. I know this is
very subjective, and maybe those mathematicians did not feel this at all. One concrete example is related to the number of regressors needed to solve a BSDE on 10 different variables.
Solving a BSDE on 10 variables for EDF was given as an illustration at the end of an otherwise excellent presentation.
Someone in the audience asked how possibly they could do that in practice since it would involve \(10^{10}\) regression factors. The answer of the speaker was more or less that it was what they do, with no particular trick but with a large computing power, as if \(10^{10}\) was not so big.
At this point I was really wondering why \(10^{10}\). Usually, when we do regressions in some BSDE like algorithm, for example Longstaff-Schwartz for American Monte-Carlo, we don’t consider all the powers of each variables from 0 to 10 as well as their cross products.
We only consider polynomials of degree 10, that is all the cross-combinations that lead to a total degree of 10 or less. On two variables \(X\) and \(Y\), we care about \(1, X, Y, XY, X^2, Y^2\) but we dont care about \(X^2 Y, X Y^2, X^2 Y^2\).
We can count then how many factors would be needed for 10 variables.
We can proceed degree by degree and compute how many ordered ways we can add \(N\) non negative integers to produce the given degree \(D\) for each degree and \(N=10\).
This number is simply \( C^{N+D-1}_{N-1} = C^{N+D-1}_D \) where \(C_k^n \) denotes the binomial coefficient.
If this number is not so obvious, we can proceed step by step as well: for degree 1, there is just \( N \) factors (we assign 1 to one of the variables).
For degree 2, there is \(N\) factors to place the number 2 on each variable, plus \( C^N_2 \) to place (1,1) on the variables. From Pascal triangle, we have \( C^{N+1}_{2} = C^N_2 + C^N_1\).
For degree 3, there is \(N\) factors to place the number 3 on each variable, plus \( C^N_3 \) to place the numbers (1,1,1) on the variables plus \(2C^N_2\) to place (1,2) and (2,1). Applying the Pascal identity twice, we have \( C^{N+2}_{3} = (C^N_1+ C^N_2) + (C^N_2 + C^N_3)\). etc.
Thus the total number of factors for \(N\) variables is
For \(N=10\), the total number of factors is 184756.
Although, the total number of factors is large, it is much less than \(10^{10}\). The surprising fact of the workshop is that there were many very advanced mathematicians in the audience, specialists of BSDEs, and none made a comment to help the presenter.
In my previous post, I looked at de-arbitraging volatilities of options of a specific maturity with the shooting method.
In reality it is not so practical. While the local volatility will be continuous at the given expiry \(T\), it won’t be so at the times \( t \lt T \)
because of the interpolation or extrapolation in time. If we consider a single market expiry at time \(T\),
it is standard practice to extrapolate the implied volatility flatly for \(t \lt T\), that is, \(w(y,t) = v_T(y) t\)
where the variance at time \(T\) is defined as \(v_T(y)= \frac{1}{T}w(y,T)\).
Plugging this into the local variance formula leads to
$$\sigma^{\star 2}\left(y, t\right) = \frac{ v_T(y)}{1 - \frac{y}{v_T}\frac{\partial v_T}{\partial y} + \frac{1}{4}\left(-\frac{t^2}{4}-\frac{t}{v_T}+\frac{y^2}{v_T^2}\right)\left(\frac{\partial v_T}{\partial y}\right)^2 + \frac{t}{2}\frac{\partial^{2} v_T}{\partial y^2}}$$
for \(t\leq T\). In particular, for \(t=0\), we have
$$\sigma^{\star 2}\left(y, 0\right) = \frac{ v_T(y)}
{1 - \frac{y}{v_T}\frac{\partial v_T}{\partial y} + \frac{1}{4}\left(\frac{y^2}{v_T^2}\right)\left(\frac{\partial v_T}{\partial y}\right)^2}$$
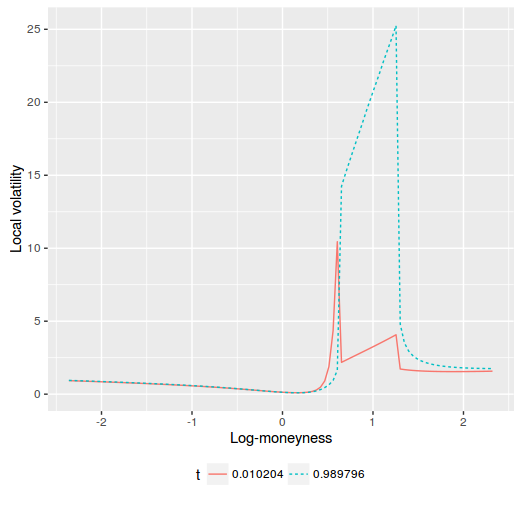
But the first derivative is not continuous, and jumps at \(y=y_0\) and \(y=y_1\). The local volatility will jump as well around those points. Thus, in practice, the technique can not be used for pricing under local volatility.
jumping local volatility on Axel Vogt example fixed by shooting
The local volatility stays very high in the original arbitrage region, very much like a capped local volatility would do. It should be then no surprise that in the equivalent implied volatility
is nearly the same as the one stemming from a capped local variance (we imply the smile from the prices of the local volatility PDE).
implied volatility on Axel Vogt example fixed by shooting or by capping
The discontinuity renders the shooting technique useless.
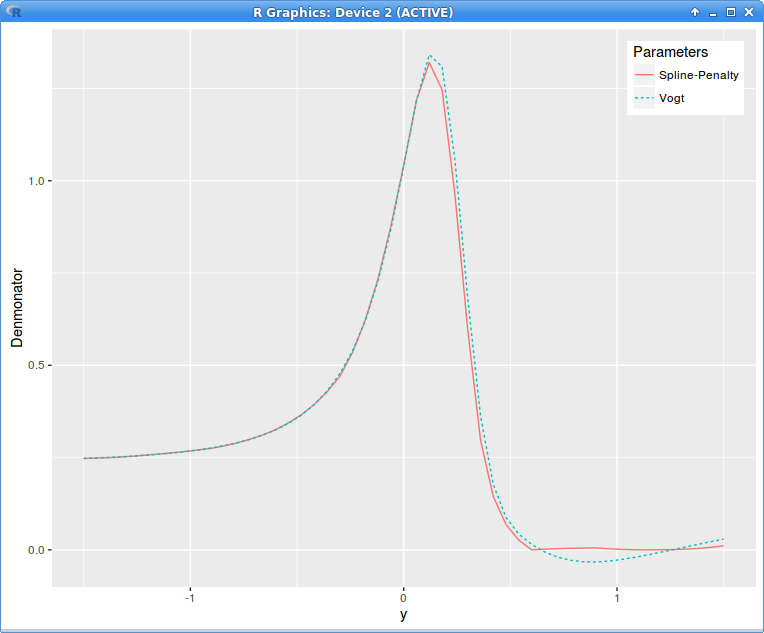
The penalized spline does not have this issue as the resulting local volatility is smooth from \(t=0\) to \(t=T\).
In my previous post, I looked at de-arbitraging volatilities of options of a specific maturity with SVI (re-)calibration.
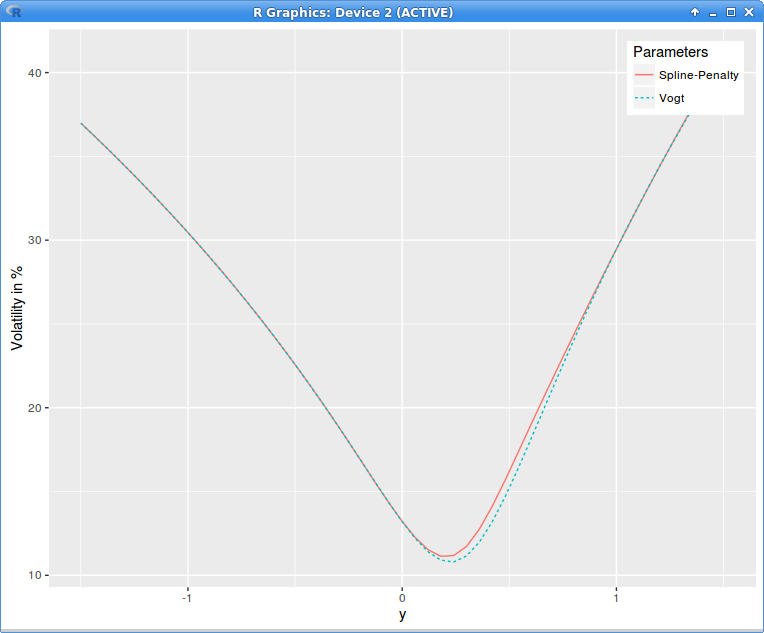
The penalty method can be used beyond SVI. For example I interpolate here with a cubic spline on 11 equidistant nodes the original volatility slice that contains arbitrages and then minimize with Levenberg-Marquardt
and the negative local variance denominator penalty on 51 equidistant points. This results in a quite small adjustment to the original volatilities:
implied variance with Axel Vogt SVI parameters
Interestingly the denominator looks almost constant, close to zero (in reality it is not constant, just close to zero, scales can be misleading):
local variance denominator g with Axel Vogt SVI parameters
The method does not work with too many nodes, for example 25 nodes was too much for the minimizer to do anything, maybe because there is too much interaction between nodes then.
I wondered then what would be the corresponding implied volatility for a constant denominator of 1E-4, glued to the implied volatility surface at the point where it reaches 1E-4.
$$10^{-4}=1 - \frac{y}{w}\frac{\partial w}{\partial y} + \frac{1}{4}\left(-\frac{1}{4}-\frac{1}{w}+\frac{y^2}{w^2}\right)\left(\frac{\partial w}{\partial y}\right)^2 + \frac{1}{2}\frac{\partial^{2} w}{\partial y^2}$$
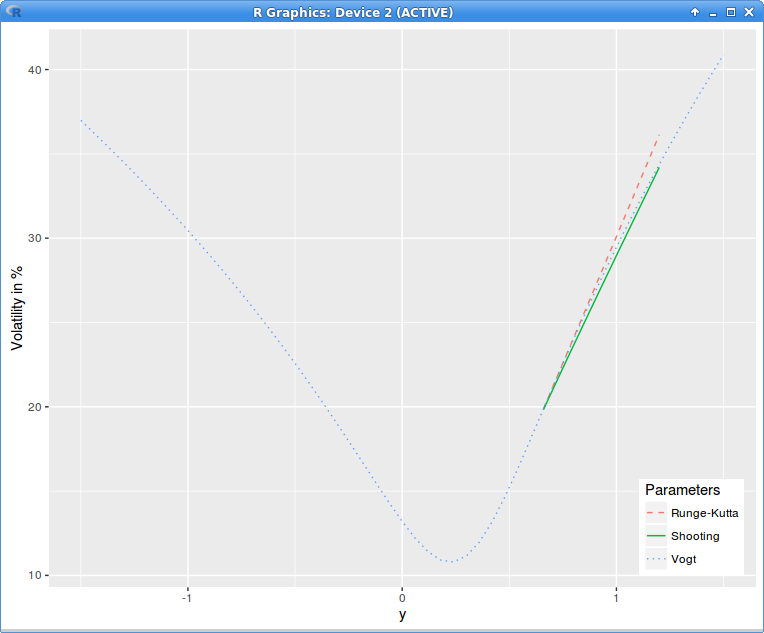
The equation can be easily solved with the Runge Kutta method by
reducing it to a system of first order ordinary differential equations.
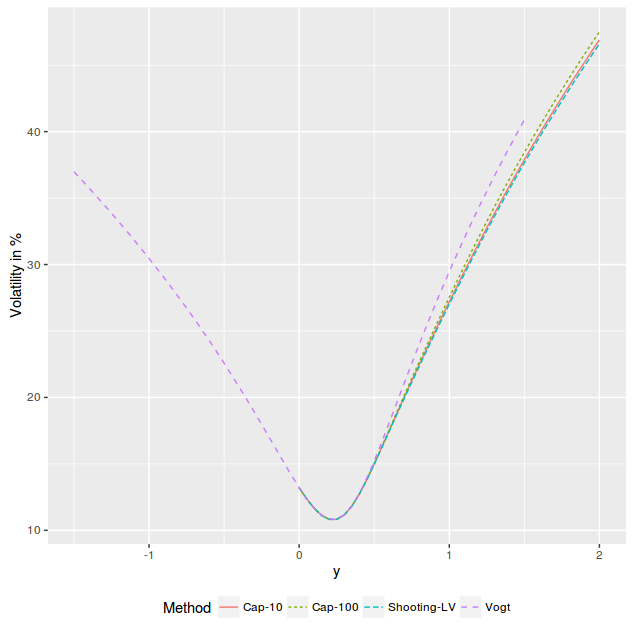
As the following figure will show, as the initial conditions are the variance and the slope at the glueing point, the volatility is not continuous anymore at the next point where the denominator goes back to 1E-4. So this is only good
if we replace the whole right wing: not so nice.
A simple idea is to adjust the initial slope so that the volatility is continuous at the next end-point. An ODE whose initial condition consists in the function values at two end-points is called a two-points boundary problem. A standard method to solve
this kind of problem is just the basic simple idea and it is called the shooting method: we are shooting a projectile from point A so that it lands at point B. Any solver can be used so solve for the slope (secant, Newton, Brent, etc.).
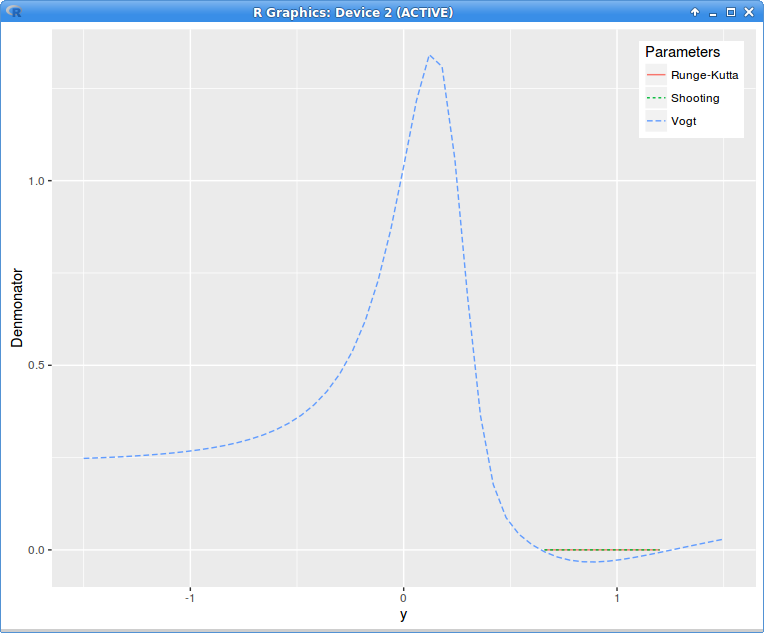
implied variance with Axel Vogt SVI parameters
The volatility is only continuous, not C1 or C2 at A and B, but the local volatility is well defined and continuous, the denominator is just 1E-4 between A and B. The adjustments to the original volatilities
is even smaller.
local variance denominator g with Axel Vogt SVI parameters
Yesterday, I wrote about some calendar spread arbitrages with SVI. Today I am looking at the famous example of butterfly spread arbitrage from Axel Vogt.
$$(a, b, m, \rho, \sigma) = (−0.0410, 0.1331, 0.3586, 0.3060, 0.4153)$$
The parameters obey the weak no-arbitrage constraint of Gatheral, and yet produce a negative density, or equivalently, a negative denominator in the local variance Dupire formula.
Those parameters are mentioned in Jim Gatheral and Antoine Jacquier paper on arbitrage free SVI volatility surfaces and also in Damghani’s paper dearbitraging a weak smile.
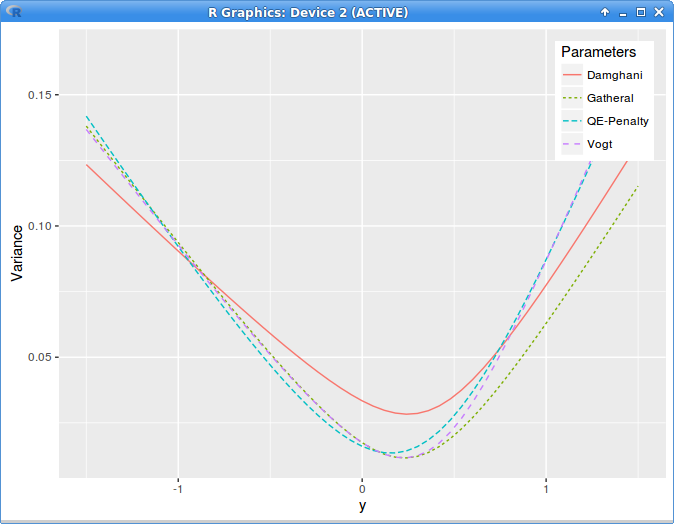
Gatheral proposes to adjust just two of the parameters (corresponding to call wing and minimum variance) and run an optimizer with a large penalty on arbitrage to find the best-fit SVI parameters.
The arbitrage can be easily detected by just computing the local variance denominator, which is not much more costly than computing the implied variance (the analytical derivatives come almost for free):
where \(w\) is the total implied variance in log-moneyness \(y\) coming from the SVI formula.
It is also possible include this penalty directly in the Nelder-Mead minimization of Zeliade’s quasi explicit calibration. In this case, all the parameters will be optimized. It is also not much slower than the more classic minimization without penalty.
While it results a much lower RMSE, the solution might not be as visually pleasing as Gatheral’s one.
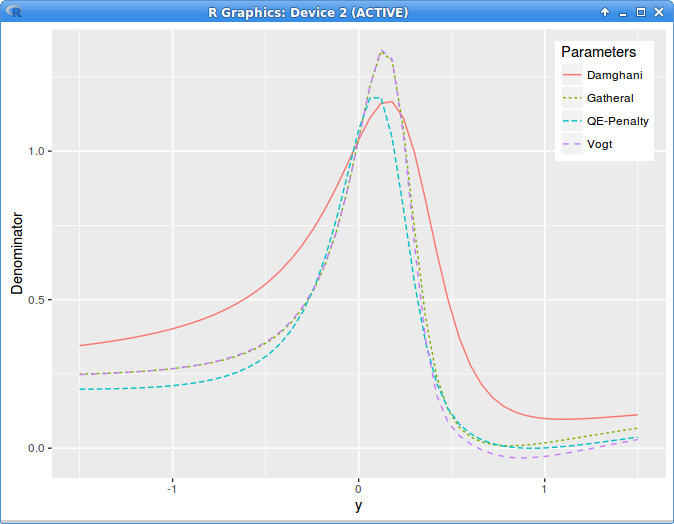
I was curious to see what Damghani’s technique would produce on this same example. Instead of doing the minimization with the full denominator evaluation, Damghani uses a simpler no-arbitrage necessary constraint
on the first derivative:
$$|\frac{\partial w}{\partial y}|<4 e $$
and iteratively search for \(e \in [0,1]\) so that no arbitrage remains in \(w\). The standard weak no-arbitrage constraint stands for \(e=1\). Dhamgani thus proposes to enforce a stronger “weak” constraint during the minimization, in order to de-arbitrage.
Note, the equations in the paper have a typo (everywhere), the \(b\) parameter should be a factor in front of the parenthesis.
Now, it seems twisted to not enforce directly the real no arbitrage constraint in the minimization, which is actually not much more complex to evaluate, and to instead rely on some weak condition, that we make stronger by steps.
There would be no loop over the minimization needed. Does this produce any good result?
implied variance with Axel Vogt SVI parameters
The graph is clear, the technique produces crap. This is the local variance denominator:
local variance denominator g with Axel Vogt SVI parameters
Maybe I misunderstood something big in this paper, but so far it was just a waste of time.
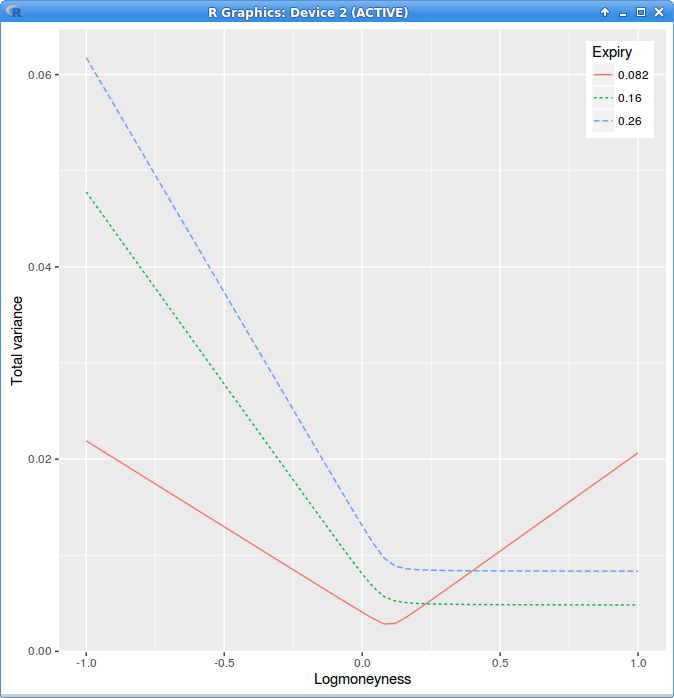
Zeliade wrote an excellent paper about the calibration of the SVI parameterization for the volatility surface in 2008. I just noticed recently
that their example calibration actually contained strong calendar spread arbitrages. This is not too surprising if you look at the parameters,
they vary wildly between the first and the second expiry.
T
a
b
rho
m
s
0.082
0.027
0.234
0.068
0.100
0.028
0.16
0.030
0.125
-1.0
0.074
0.050
0.26
0.032
0.094
-1.0
0.093
0.041
The calendar spread arbitrage is very visible in total variance versus log-moneyness graph:
in those coordinates if lines crosses, there is an arbitrage. This is because the total variance should be increasing with the expiry time.
Arbitrage in Zeliade's example
Why does this happen?
This is typically because the range of moneyness of actual market quotes for the first expiry is quite narrow, and looks more like a smile than a skew. The problem is that
SVI is then quite bad at extrapolating this smile, likely because the SVI wings were used to fit well the curvature and have nothing to do with any actual market wings.
A consequence is that that the local volatility will be undefined in the right wing of the second and third expiries, if we keep the first expiry.
It is interesting to look at what happens to the implied volatility if we decide either to:
set the undefined local volatility to zero
take the absolute value of the local variance
search for the closest defined local volatility on the log-moneyness axis
search for the closest positive local variance on the expiry axis and interpolate it linearly.
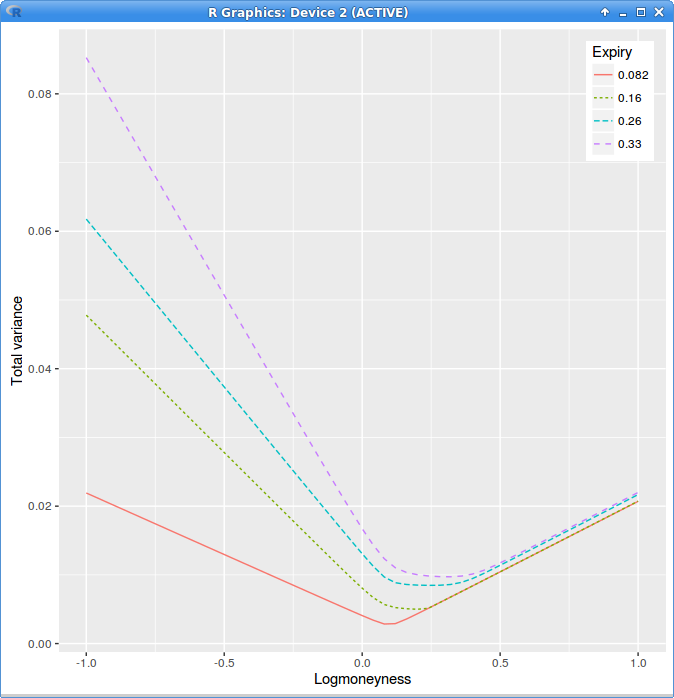
Total variance after flooring the local variance at zero.
Setting the undefined local volatility to zero makes the second, third, fourth expiry wings higher: the total variance is close to constant between expiries. One could have expected
that a zero vol would lead to a lower implied vol, the opposite happens, because the original local vol is negative, so flooring it zero is like increasing it.
We can now deduce that taking the absolute value of the local variance is just going to push the implied variance even higher, and will therefore create a larger bias. Similarly, searching for closest local volatility
is not going to improve anything.
Fixing the local volatility after the facts produces only a forward looking fix: the next expiries are going to be adjusted as a result.
Instead, in this example, the first maturity should be adjusted. A simple adjustment would be to cap the total variance of the first expiry so that it is never higher than the next expiry, before computing the local volatility.
Although the resulting implied volatility will not be C2 or even C1 at the cap, the local volatility can be computed analytically on the left side, before the cap, and also analytically after the cap, on the right side.
More care needs to be taken if the next expiry also needs to be capped (for example because there is another calendar spread arbitrage between expiry two and expiry three). In this case, the analytical calculation must be split in three zones: first-nocap + second-nocap, first-cap+second-nocap, first-cap+second-cap.
So in reality having non C2 extrapolation can work well with local volatility if we are careful enough to avoid the artificial spike at the points of discontinuity.
There is yet another solution to produce a similar effect while still working at the local volatility level: if there is an arbitrage with the previous expiry at a given moneyness,
we compute the local volatility ignoring the previous expiry (eventually extrapolating in constant manner) and we override the previous expiry local volatility for this moneyness.
In terms of implied variance, this would correspond to removing the arbitrageable part of a given expiry, and replacing it with a linear interpolation between encompassing expiries, working backwards in time.
I had a look at how to price under Local Volatility with Cash dividends in my previous post. I still had a somewhat large error in my FDM price. After too much time, I managed to find the culprit, it was the extrapolation of the prices when applying the jump continuity condition \(V(S,t_\alpha^-) = V(S-\alpha, t_\alpha^+) \) for an asset \(S\) with a cash dividend of amount \(\alpha\) at \( t_\alpha \).
I stumbled in the meantime on another alternative to compute the Dupire local volatility with cash dividends in the book of Lorenzo Bergomi, one can rely on the
classic Gatheral formulation in terms of total implied variance \(w(y,T)\) function of log-moneyness:
In this case the total implied variance corresponds to the Black volatility of the pure process (the process without dividend jumps), that is, the Black volatility corresponding to (shifted) market option prices. If the reference data consists of model volatilities for the spot model (with known jumps at dividend dates), the market prices can be obtained by using a good approximation of the spot model, for example the improved Etore-Gobet expansion of this paper, not with the Black formula directly.
In theory, it should be more robust to work directly with implied variances as there is not the problem of dealing with a very small numerator and denominator of the option prices equivalent formula. In practice, if we rely on one of the Etore-Gobet expansions, it can be much faster to work directly with option prices if we are careful when computing the ratio, as this ratio can be obtained in closed form. In theory as well, we need to use a fine discretisation in time to represent the pure Black equivalent smile accurately. In practice, if we are not too bothered by a mismatch with the true theoretical model, introducing volatility slices just before/at the dividends is enough to reproduce the market prices exactly, as long as we make sure that those obey the option price continuity at the dividend \(C(S_0,K,t_{\alpha}^-) = C(S_0, K-\alpha,t_{\alpha}^+)\). The difference is that the interpolation in time (linear in total variance) is going to describe a slightly different dynamic from the true spot process. The advantage, is that then, it is much faster.
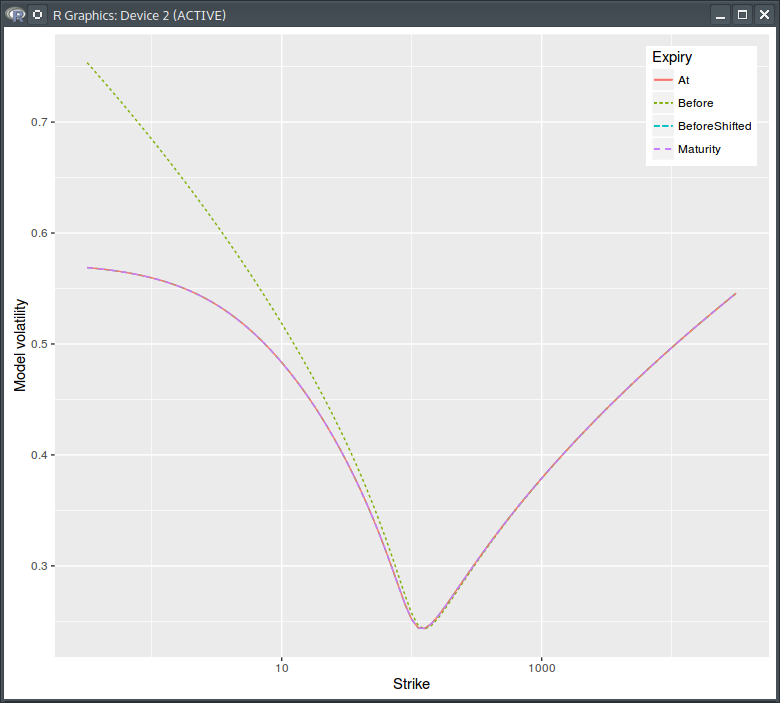
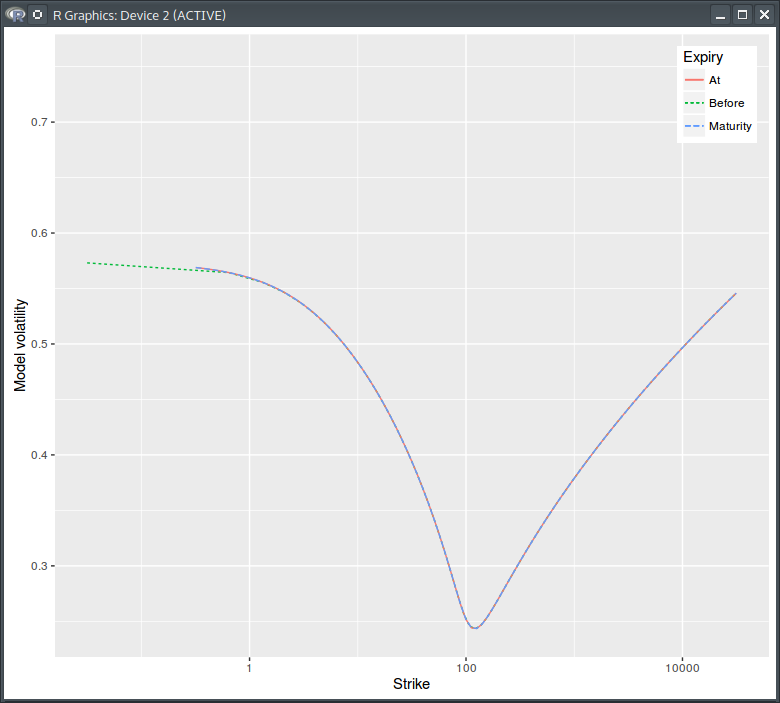
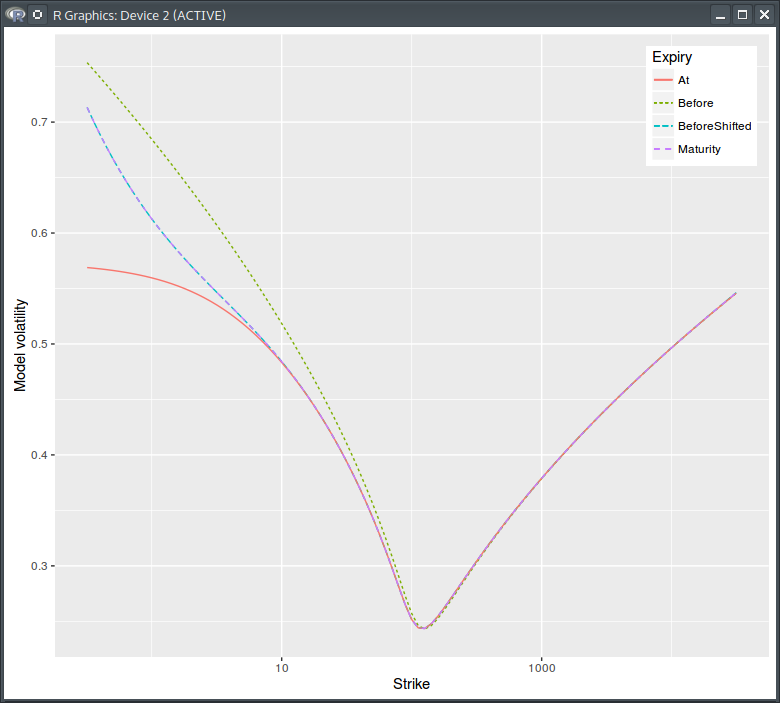
I thought it would be interesting to have a look at the various volatilities. My initial spot volatility is a simple smile constant in time:
Model volatility. Before,At = before the dividend, at the dividend. Log scale for strikes.
Actually it’s not all that constant since there is the need to introduce a shift at the dividend date to obey the option price continuity relationship. The pure process model volatility is however constant.
Pure process model volatility.
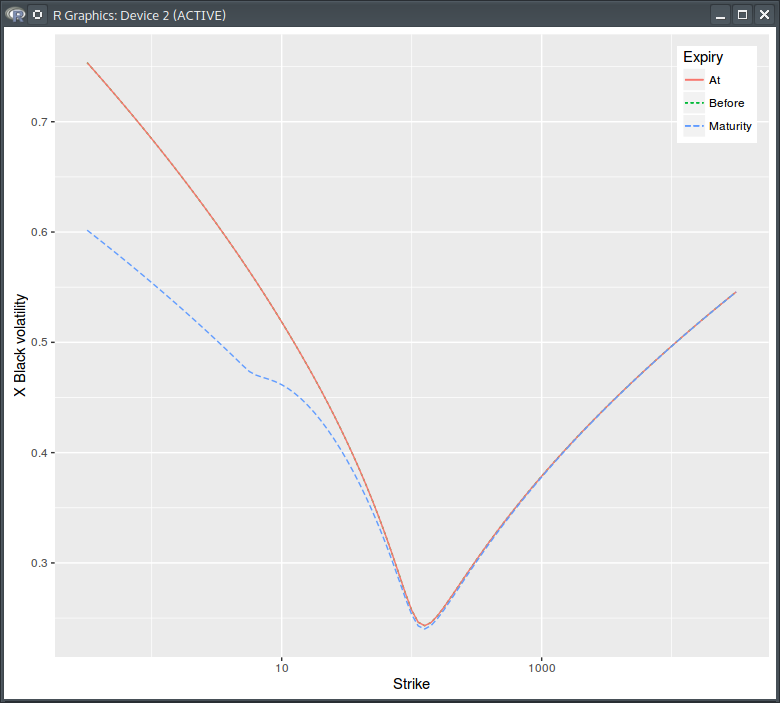
The equivalent pure process Black vols looks like this:
Pure process Black volatility
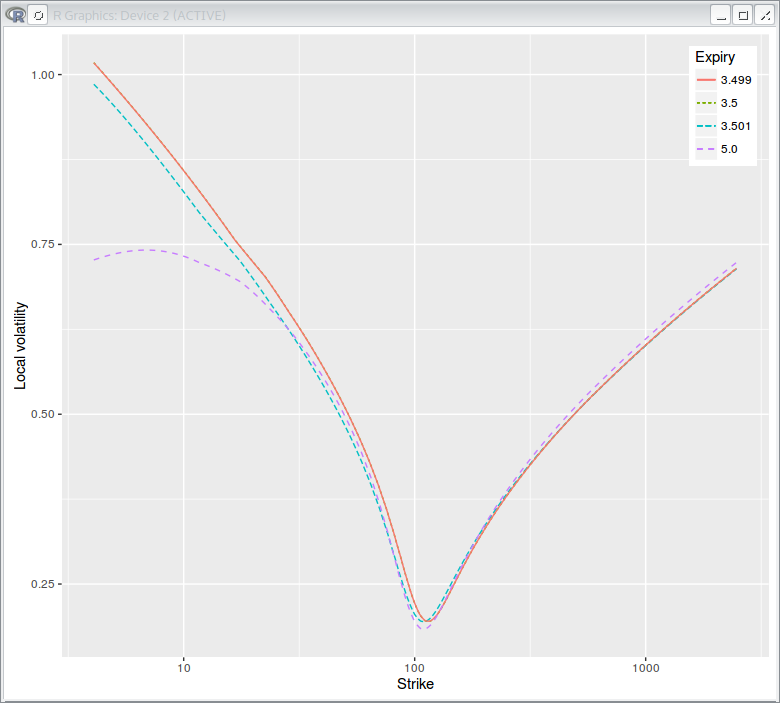
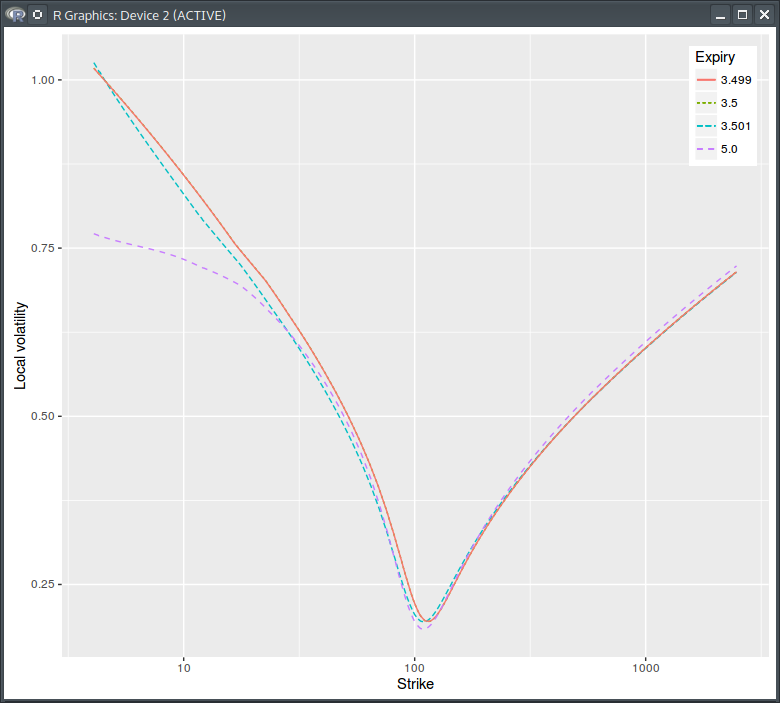
Notice how it does not jump at the dividend date, and how the cash dividend results in a lower Black volatility at maturity. The local volatility is:
Dupire Local Volatility under the spot model with jump at dividend date = 3.5
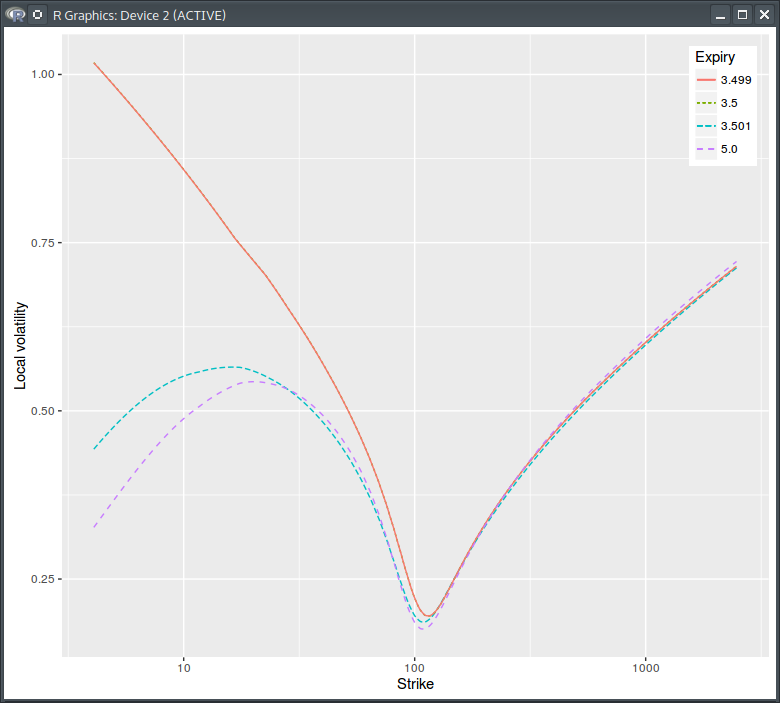
While the one of the pure process is:
Pure Process Local Volatility under the spot model with jump at dividend date = 3.5
It falls towards zero for low pure strikes or equivalently near the market strike corresponding to the dividend amount.
So far, this is not too far from the textbook theory. Now it happens that there is another subtlety related to the dividend policy. The dividend policy defines what happens when the spot price is lower than the cash dividend. Haug, Haug and Lewis defined two policies, liquidator and survivor as
\(V(S,K,t_\alpha^-) = V(0,K, t_\alpha^+) \) for the liquidator - the stock drops to zero.
\(V(S,K,t_\alpha^-) = V(S,K, t_\alpha^+) \) for the survivor - the dividend is not paid.
Not applying any particular policy would mean that the stock price can become negative:
\(V(S,K,t_\alpha^-) = V(S-\alpha,K, t_\alpha^+) \) also when \( S < \alpha \).
Which one should we use? The approximation formulae (when not adjusted by the call price at strike 0) actually correspond to the “no dividend policy” rule. It can be verified numerically on extreme scenarios. It appears then natural that the finite difference scheme should also follow the same policy. And the volatility slice after the dividend date is really a constant size shift of the volatility slice just before.
It becomes however more surprising if the model of reference is the liquidator (or the survivor) policy, that is, the market option prices are computed with a nearly exact numerical method according to the liquidator policy. In this case the volatility slice after the dividend date is not merely a constant size shift anymore, as the dividend policy will impact the option price continuity relationship.
Liquidator model volatility. Before,At = before the dividend, at the dividend. Notice the difference in the BeforeShifted curve compared to the graph with no dividend policy.
It turns out, that then, using the same policy in the FDM scheme at the dividend dates will actually create a bias, while discarding the dividend policy will make the method converge to the correct price. How can this be? My interpretation is that the Dupire local volatility already includes the dividend policy effect, and therefore it should not be taken into account once more in the finite difference scheme dividend jump condition. It is only a partial explanation, since imposing a liquidator policy via the jump condition seems to actually never work with Dupire (on non flat vols), even if the Dupire local volatility does not include the dividend policy effect.
Dupire Local Volatility under the spot model with liquidator policy and jump at dividend date = 3.5
Of course, this is not true when the volatility is constant until the option maturity (no smile, no Dupire). In this case, the policy must be enforced via the jump condition in the finite difference scheme.
Note that this effect is not always simple to see, in my example, it is visible, especially on Put options of low strikes, because the volatility surface wings imply a high volatility when the strike is low and the option maturity is relatively long (5 years). For short maturities or lower volatilities, the dividend policy impact on the price is too small to be noticed.