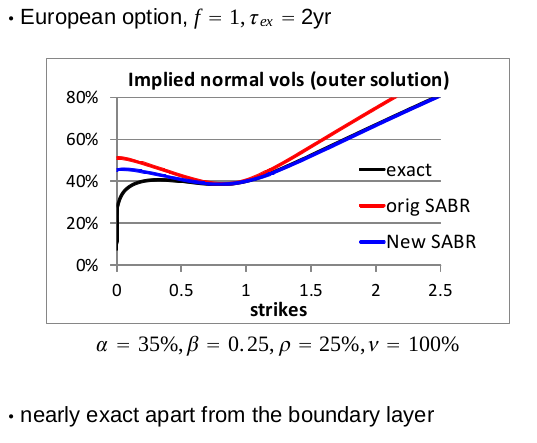
In a talk at the Global Derivatives conference of Amsterdam (2014), Pat Hagan presented some new SABR formulas, supposedly close to the arbitrage free PDE behavior.
I tried to code those from the slides, but somehow that did not work out well on his example, I just had something very close to the good old SABR formulas. I am not 100% sure (only 99%) that it is due to a mistake in my code. Here is what I was looking to reproduce:
Pat Hagan Global Derivatives example
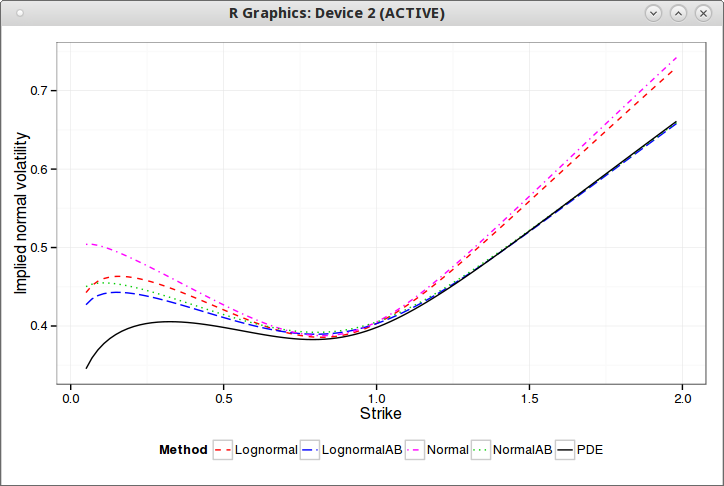
Fortunately, I then found in some thesis the idea of using Andersen & Brotherton-Ratcliffe local volatility expansion. In deed, the arbitrage free PDE from Hagan is equivalent to some Dupire local volatility forward PDE (see http://papers.ssrn.com/abstract=2402001), so Hagan just gave us the local volatility expansion to expand on (the thesis uses Doust, which is not so different in this case).
And then it produces on this global derivatives example the following:
The AB suffix are the new SABR formula. Even though the formulas are different, that looks very much like Hagan's own illustration (with a better scale)!
It's relatively well known that Heston does not fit the market for short expiries. Given that there are just 5 parameters to fit a full surface, it's almost logical that one part of the surface of it is not going to fit well the market. I was more surprised to see how bad Heston or Schobel-Zhu were to fit a single short expiry volatility slice. As an example I looked at SP500 options with 1 week expiry. It does not really matter if one forces kappa and rho to constant values (even to 0) the behavior is the same and the error in fit does not change much.
Schobel-Zhu fit for a slice of maturity 1 week
In this graph, the brown, green and red smiles corresponds to Schobel-Zhu fit using an explicit guess (matching skew & curvature ATM), using Levenberg-Marquardt on this guess, and using plain differential evolution. What happens is that the smiles flattens to quickly in the strike dimension. One consequence is that the implied volatility can not be computed for extreme strikes: the smile being too low, the price becomes extremely small, under machine epsilon and the numerical method (Cos) fails. There is also a bogus angle in the right wing, because of numerical error. I paid attention to ignore too small prices in the calibration by truncating the initial data.
Heston fit, with Lord-Kahl (exact wings)
SABR behaves much better (fixing beta=1 in this case) in comparison (As I use the same truncation as for Schobel-Zhu, the flat left wing part is ignored).
SABR fit for a slice of maturity 1 week
For longer expiries, Heston & Schobel-Zhu, even limited to 3 parameters, actually give a better fit in general than SABR.
Most developers have strong opinions on dynamic types programming languages vs static types programming languages. The former is often assumed to be good for small projects/prototyping while the later better for bigger projects. But there is a surprisingly small number of studies to back those claims.
It's more interesting to look at generic types vs raw types use, where even less studies have been done. "Do developers benefit from generic types?: an empirical comparison of generic and raw types in java" concludes that generic types do not provide any advantages to fix typing errors, hardly surprising in my opinion. Generic types (especially with type erasure as in Java) is the typical idea that sounds good but that in practice does not really help: it makes the code actually more awkward to read and tend to make developers too lazy to create new classes that would often be more appropriate than a generic type (think Map<String,List<Map<String, Date>>>).
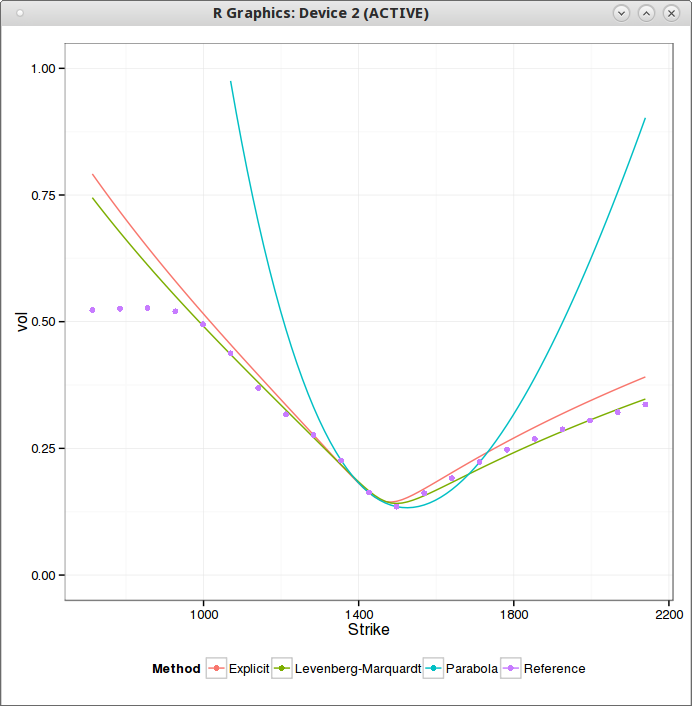
I have found a particularly nice initial guess to calibrate SABR. As it is quite close to the true best fit, it is tempting to use a very simple minimizer to go to the best fit. Levenberg-Marquardt works well on this problem, but can we shave off a few iterations?
I firstly considered the basic Newton's method, but for least squares minimization, the Hessian (second derivatives) is needed. It's possible to obtain it, even analytically with SABR, but it's quite annoying to derive it and code it without some automatic differentiation tool. It turns out that as I experimented with the numerical Hessian, I noticed that it actually did not help convergence in our problem. Gauss-Newton converges similarly (likely because the initial guess is good), and what's great about it is that you just need the Jacobian (first derivatives). Here is a good overview of Newton, Gauss-Newton and Levenberg-Marquardt methods.
While Gauss-Newton worked on many input data, I noticed it failed also on some long maturities equity smiles. The full Newton's method did not fare better. I had to take a close look at the matrices involved to understand what was going on. It turns out that sometimes, mostly when the SABR rho parameter is close to -1, the Jacobian would be nearly rank deficient (a row close to 0), but not exactly rank deficient. So everything would appear to work, but it actually misbehaves badly.
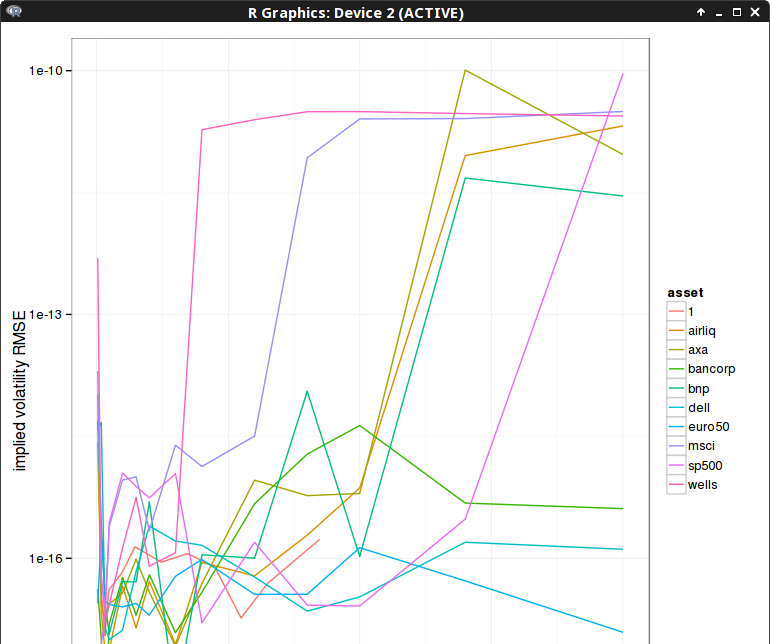
My first idea was to solve the reduced problem if a row of the Jacobian is too small, by just removing that row, and keep the previous value for the guess corresponding to that row. And this simplistic approach made the process work on all my input data. Here is the difference in RMSE compared to a highly accurate Levenberg-Marquardt minimization for 10 iterations:
Later, while reading some more material related to least square optimization, I noticed the use of the Moore-Penrose inverse in cases where a matrix is rank deficient. The Moore-Penrose inverse is defined as: $$ M^\star = V S^\star U^T$$ where \( S^\star \) is the diagonal matrix with inverted eigenvalues and 0 if those are deemed numerically close to 0, and \(U, V\) the eigenvectors of the SVD decomposition: $$M=U S V^T$$ It turns out to work very well, beside being simpler to code, I expected it to be more or less equivalent to the previous approach (a tiny bit slower but we don't care as we deal with small matrices, and the real slow part is the computation of the objective function and the Hessian, which is why looking at iterations is more important).
It seems to converge a little bit less quickly, likely due to the threshold criteria that I picked (1E-15). Three iterations is actually most of the time (90%) more than enough to achieve a good accuracy (the absolute RMSE is between 1E-4 and 5E-2) as the following graph shows. The few spikes near 1E-3 represent too large errors, the rest is accurate enough compared to the absolute RMSE.
To conclude, we have seen that using the Moore-Penrose inverse in a Gauss-Newton iteration allowed the Gauss-Newton method to work on rank-deficient systems. I am not sure how general that is, in my example, the true minimum either lies inside the region of interest, or on the border, where the system becomes deficient. Of course, this is related to a "physical" constraint, here namely rho > -1.
I presented in an earlier post that I was mostly disillusioned with interview questions, it’s better to find out if you can learn something out of a candidate.Well there is maybe one very simple question that could be revealing, for people who pretend to be vaguely familiar with Black-Scholes:What is the price of an at-the-money binary option under very high volatility? Alternatively it can be asked with just an at-the-money european option under very high volatility.What makes think of it is that some “product manager” recently tested risk with volatilities at 300% and was wondering why they did not see any vega (based on a 1% additive shift), and opened bugs, generated noise…
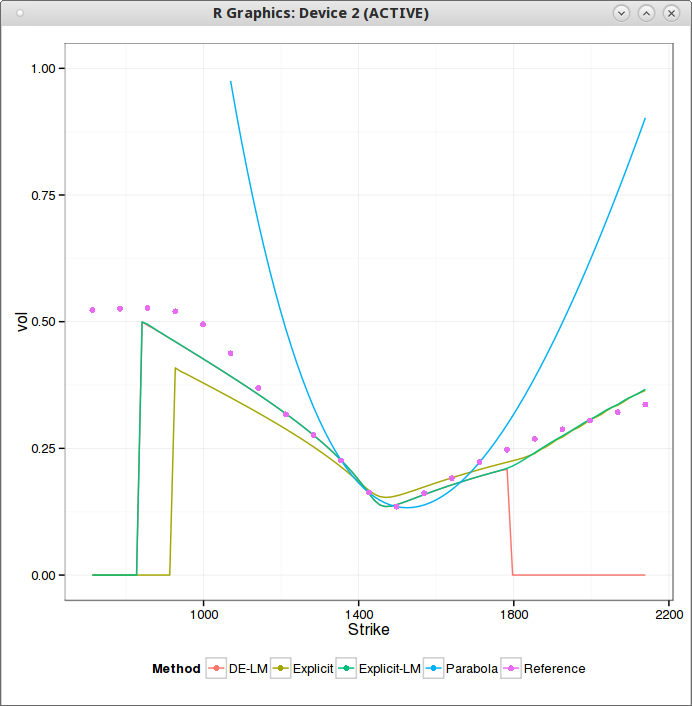
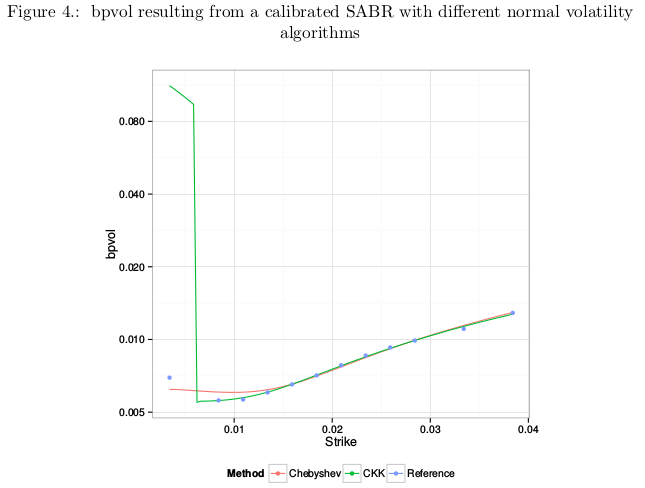
While I was playing around calibrating the arbitrage free SABR model from Hagan (using the PDE on probability density approach), I noticed a misbehavior for some short maturity smiles. I thought it was due to the PDE implementation. Actually some of it was, but the remaining large error was due to the bpvol solver.
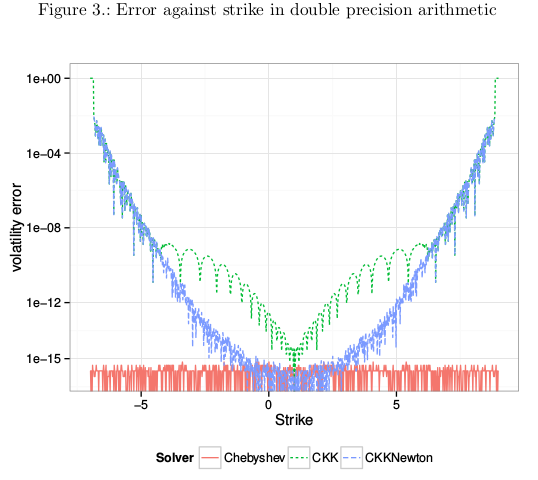
I initially took the same approach as Choi et al. in my solver, that is to work with in-the-money prices (they work with straddles) because it’s nice and convenient. I thought it was no big deal if prices lower than 1E-16 were not solved. It turns out I was wrong. Choi et al. solver has the same issue.
In the above figure, CKK denotes the Choi et al algorithm (similar with my old algorithm) and Chebyshev is my updated algorithm that is accurate with far out-of-the-money option. What happens is that even though the market price at the lowest strike is not very low, the price at the lowest strike stemming from the best fit smile is extremely low, and when we want to invert it, CKK produces a large error due to lack of representation of numbers near 1.0 as it uses indirectly the in-the-money price. That’s where it introduces a particularly big error in this case.
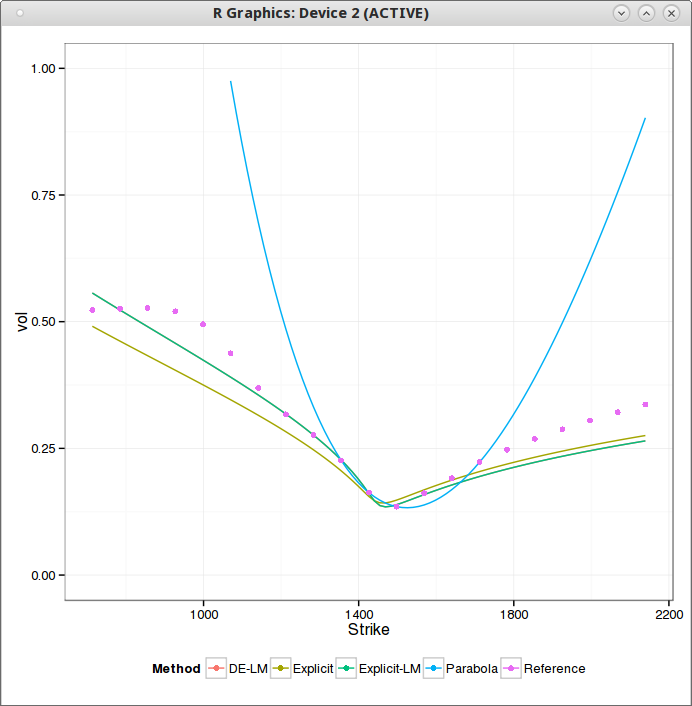
I have updated my solver since, to work with out-of-the-money option prices as well, and have near machine accuracy on the whole range. I also reduced the number of Chebyshev polynomials used in the process. All the details are in my updated paper at http://papers.ssrn.com/abstract=2420757
There was a big debate at work around Exception declaration in a Java API. I was quite surprised that such an apparently simple subject could end up being so controversial. The controversy was around the choice of declaring in the interfaces:
where MyAPI represents either a generic API related exception or a specific exception related to the method in question.
The choice of "throws Exception" did not even occur to me as a possibility, but after some digging, I found that some relatively famous libraries actually followed that principle at one point, for example Apache Struts 1.x or Spring MVC.
More modern libraries, like Google Guava, commons-math 3.x, Struts 2.x generally favor MyAPIRuntimeException where MyAPI is actually context-specific. Some old popular libraries declare a checked Exception, for example the HibernateException in Hibernate.
This comment from Anders is particularly acute: "To work around this requirement, people do ridiculous things. For example, they decorate every method with, "throws Exception." That just completely defeats the feature, and you just made the programmer write more gobbledy gunk. That doesn't help anybody. "
Today I believe the API in question declares "throws Exception"...
Many people (and notoriously, Linus Torvald) complained about Gnome-shell, especially the early iterations. Similarly KDE 4 was a nightmare of instability and inflexibility when it came out. And XFCE has always sounded a bit too basic. the moves of Gnome and KDE were particularly shocking as the earlier iteration: Gnome 2 and KDE 3 were well appreciated, productive environments.
Gnome Shell 3.10
It took me a bit of time to get used to it, and in the early stages I went to KDE 4 for a while, only to come back to it later.
Positive aspects: lots of space on the desktop, things don't get in the way, looks good,very good desktop overview (fast and well presented), a dock by default, great external monitor support (plug and play, remembers settings automatically), best OSD (volume) of all.
Negative aspects: the notifications bar looks awkward and badly integrated (better with an extension), still unstable and big memory leaks (on Fedora 20, where the integration should be the best, it regularly crashes, starts with 300Mb and goes up to 1Gb in a couple of days), fallback-session completely useless as one can not customize it at all. But the killer for my work was inability to share the desktop with Webex, while XFCE could.
KDE
I gave it a long try especially in 2012, it has not changed much in 2014. My opinion of it fell when I tried it a very short time after months of Gnome Shell, and even more so after seeing the trouble my parents had with it, compared to Gnome 2.
Positive aspects: desktop search (needs to be configured in order to scan only the relevant folders, used to be slow and resource intensive, not so much in 2014)
Negative aspects: resource hog, awful start menu, too many shiny effects by default that only distract the user from his task, silly concepts like activities, every aspect of the desktop seems to require tweaking in non obvious ways for it to be more usable, looks ok but not great.
XFCE
On Fedora, the default XFCE is very very basic, so much that I could hardly see a difference with one from 10 years ago. On Xubuntu, it's much much better. When I came to it from Gnome-Shell, I was surprised at how good was the "old" desktop paradigm for productivity. I also surprisingly found multiple desktops more natural to use than on Gnome Shell/KDE. On Fedora the way to make it like Xubuntu is to install elementary icons, the whisker menu and choose the greybird/bluebird themes. yum groups install "Xfce Desktop" yum install xfce4-mixer.x86_64 xfce4-whiskermenu-plugin.x86_64 xfce4-cpugraph-plugin.x86_64 xfce4-mount-plugin.x86_64 xfce4-icon-theme.noarch google-droid* elementary-xfce-icon-theme.noarch xfce4-volumed.x86_64 pavucontrol.x86_64
Positive aspects: fast and lean, great start menu.
Negative aspects: external monitor support could be more automatic like Gnome-Shell, no nice overview of all windows, default installation can be a bit too bare, sometimes not sexy (volume applet is ugly, xubuntu provides the unity indicators in xfce as a remedy), primitive OSD.
Cinnamon, Unity, Conclusion
I gave a short try to cinnamon as well, in hopes that it was more stable than gnome shell. In short, it was not. It's certainly less of a memory hog, but I had some strange behavior with an additional phantom panel sometimes appearing at the bottom at the screen. And overall it looks a lot less polished.
Unity is more interesting, but it's too Ubuntu centric, I don't like the start button equivalent (slow, badly presented, don't care about HUD), the windows overview is not as useful as Gnome shell, the dock, something I usually like, is strangely annoying.
This is a very subjective review, my feeling is that in 2014, people should not waste their time with KDE or Cinnamon. Gnome shell could be worth a try if you don't care so much about memory leaks and slight instability but value a distraction free desktop. Otherwise go for XFCE or Unity on (X)ubuntu.
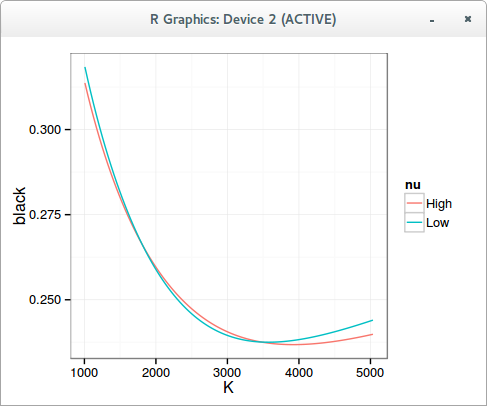
While playing around with differential evolution to calibrate SABR, I noticed that sometimes, several set of parameters can lead to a very similar smile, usually the good one is for relatively low vol of vol and the bad one is for relatively high vol of vol. I first looked for errors in my implementation, but it’s a real phenomenon.
I used the normal implied volatility formula with beta=1, then converted it to lognormal (Black) volatility. While it might not be a great idea to rely on the normal formula with beta=1, I noticed the same phenomenon with the arbitrage free PDE density approach, especially for long maturities. Interestingly, I did not notice such behavior before with other stochastic volatility models like Heston or Schobel-Zhu: I suspect it has to do with the approximations rather than with the true behavior of SABR.
Differential evolution is surprisingly good at finding the global minimum without much initial knowledge, however when there are close fits like this it can be more problematic, usually this requires pushing the population size up. I find that differential evolution is a neat way to test the robustness (as well as performance) of different SABR algorithms as it will try many crazy sets.
In practice, for real world calibration, there is not much use of differential evolution to calibrate SABR as it is relatively simple to find a good initial guess.
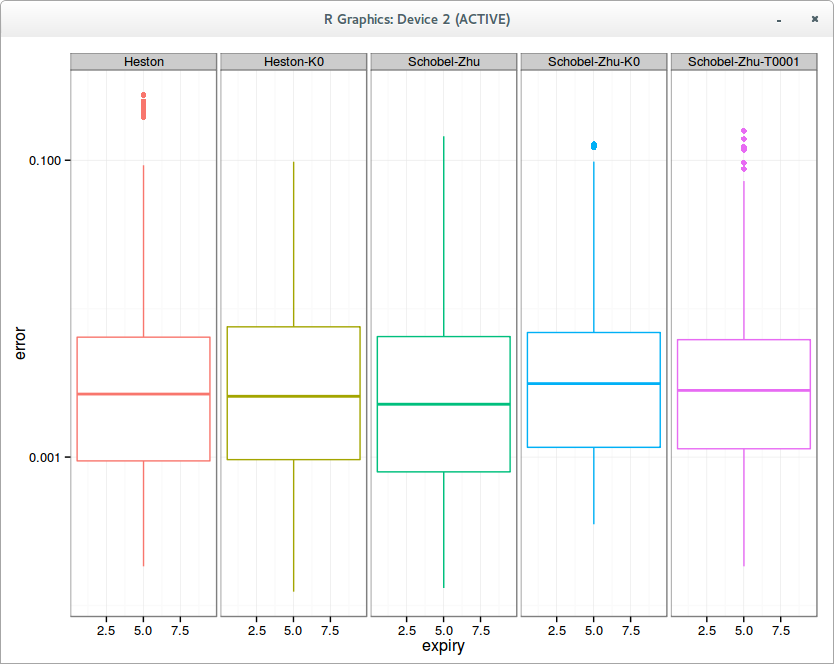
Some people use Heston to fit one slice of a volatility surface. In this case, some parameters are clearly redundant. Still, I was wondering how it fared against SABR, which is always used to fit a slice. And what about Schobel-Zhu?
Aggregated error in fit per slice on 10 surfaces
With Heston, the calibration is actually slightly better with kappa=0, that is, without mean reversion, because the global optimization is easier and the mean reversion is fully redundant. It’s still quite remarkable that 3 parameters result in a fit as good as 5 parameters.
This is however not the case for Schobel-Zhu, where each “redundant parameter” seem to make a slight difference in the quality of calibration. kappa = 0 deteriorate a little bit the fit (the mean error is clearly higher), and theta near 0 (so calibrating 4 parameters) is also a little worse (although better than kappa = 0). Also interestingly, the five parameters Schobel-Zhu fit is slightly better than Heston, but not so when one reduce the number of free parameters.
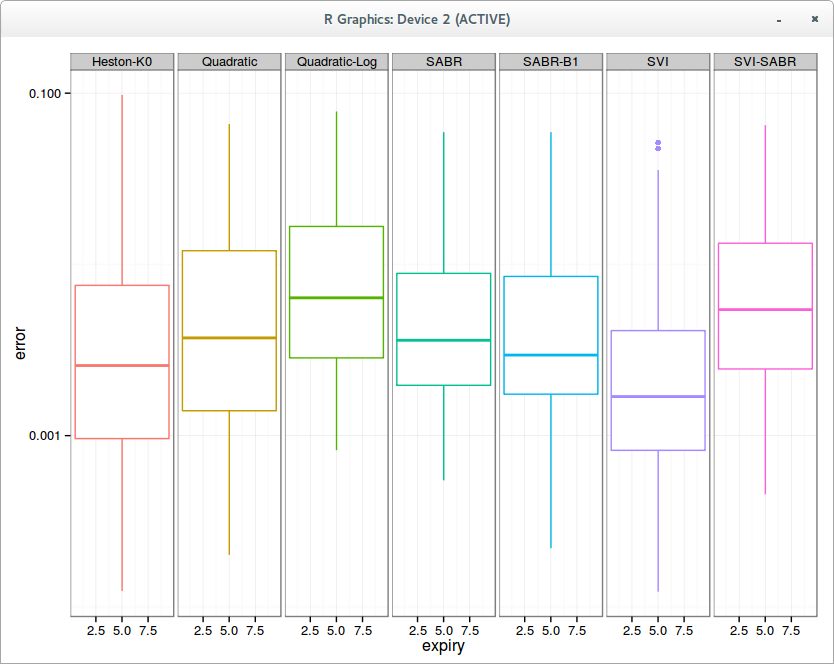
So what about Heston vs SABR. It is interesting to consider the case of general Beta and Beta=1: it turns out that as confirmed for equities, beta=1 is actually a better choice.
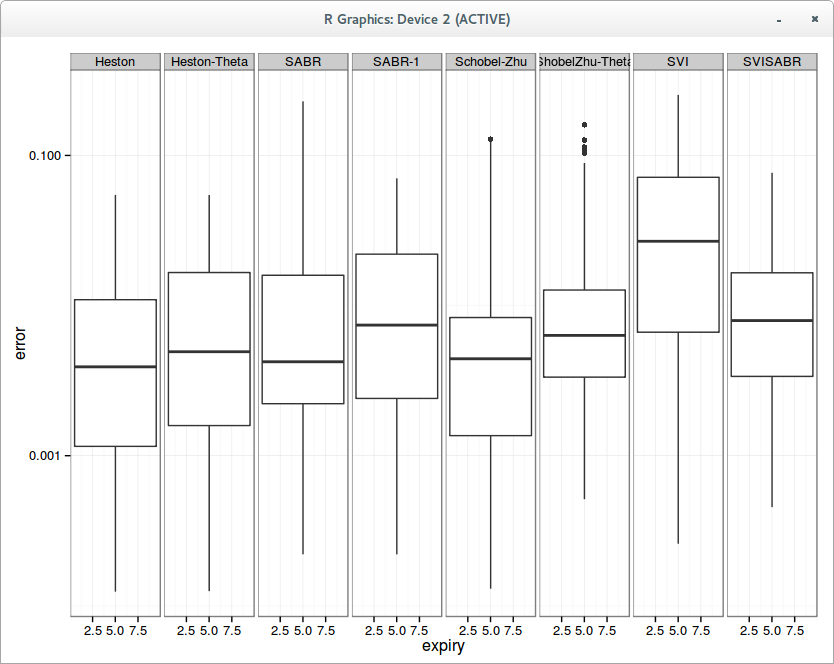
Aggregated error in fit per slice on 10 surfaces
Overall on my 10 surfaces composed each of around 10 slices, an admittedly small sample, Heston (without mean-reversion) fit is a little bit better than SABR. Also the SVI-SABR idea from Gatheral is not great: the fit is clearly worse than SABR with Beta=1 and even worse than a simple quadratic.
Of course the best overall fit is achieved with the classic SVI, because it has 6 parameters while the others have only 3.
All the calibrations so far were done slice by slice independently, using levenberg marquardt on an initial guess found by differential evolution. Some people advocate for speed or stability of parameters reasons the idea of calibrating each slice using the previous slice as initial guess with a local optimizer like levenberg marquardt, in a bootstrapping fashion.
The results can be quite different, especially for SVI, which then becomes the worst, even worse than SVI-SABR, which is actually a subset of SVI with fewer parameters. How can this be?
This is because as the number of parameters increases, the first slices optimizations have a disproportionate influence, and finding the real minimum is much more difficult, even with differential evolution for the first slice. It’s easy to picture that you’ll have much more chances to get stuck in some local minimum. It’s interesting to note that the real stochastic volatility models are actually better behaved in this regard, but I am not so sure that this kind of calibration is such a great idea in general.
In practice, the SVI parameters fitted independently evolve in a given surface on each slice in a smooth manner, mostly monotonically. It’s just that to go from one set on one slice to the other on the next slice, you might have to do something more than a local optimization.