The CUDA Performance Myth II
This is a kind of following to the CUDA performance myth. There is a recent news on the java concurrent mailing list about SplittableRandom class proposed for JDK8. It is a new parallel random number generator a priori usable for Monte-Carlo simulations.
It seems to rely on some very recent algorithm. There are some a bit older ones: the ancestor, L’Ecuyer MRG32k3a that can be parallelized through relatively costless skipTo methods, a Mersenne Twister variant MTGP, and even the less rigourous XorWow popularized by NVidia CUDA.
The book GPU Computing Gems provides some interesting stats as to GPU vs CPU performance for various generators (L’Ecuyer, Sobol, and Mersenne Twister)
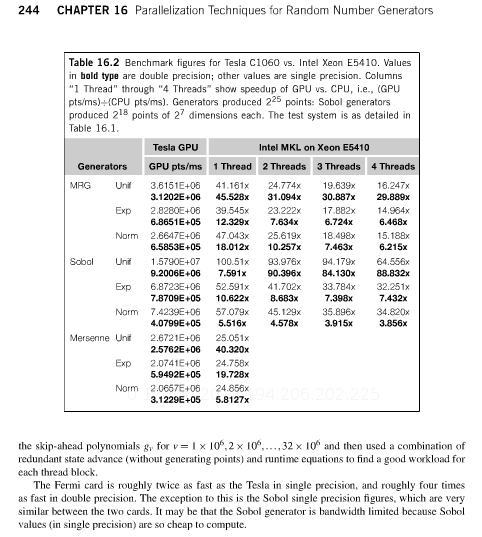
Excerpt from the book
A Quad core Xeon is only 4 times slower to generate normally distributed random numbers with Sobol. Fermi cards are faster now, but probably so are newer Xeons. I would have expected this kind of task to be the typical not too complex parallelizable task doable by a GPU, and yet the improvements are not very good (except if you look at raw random numbers, which is almost useless in applications). It confirms the idea that many real world algorithms are not so much faster with GPUs than with CPUs. I suppose what’s interesting is that the GPU abstractions forces you to be relatively efficient, while the CPU flexibility might make you lazy.