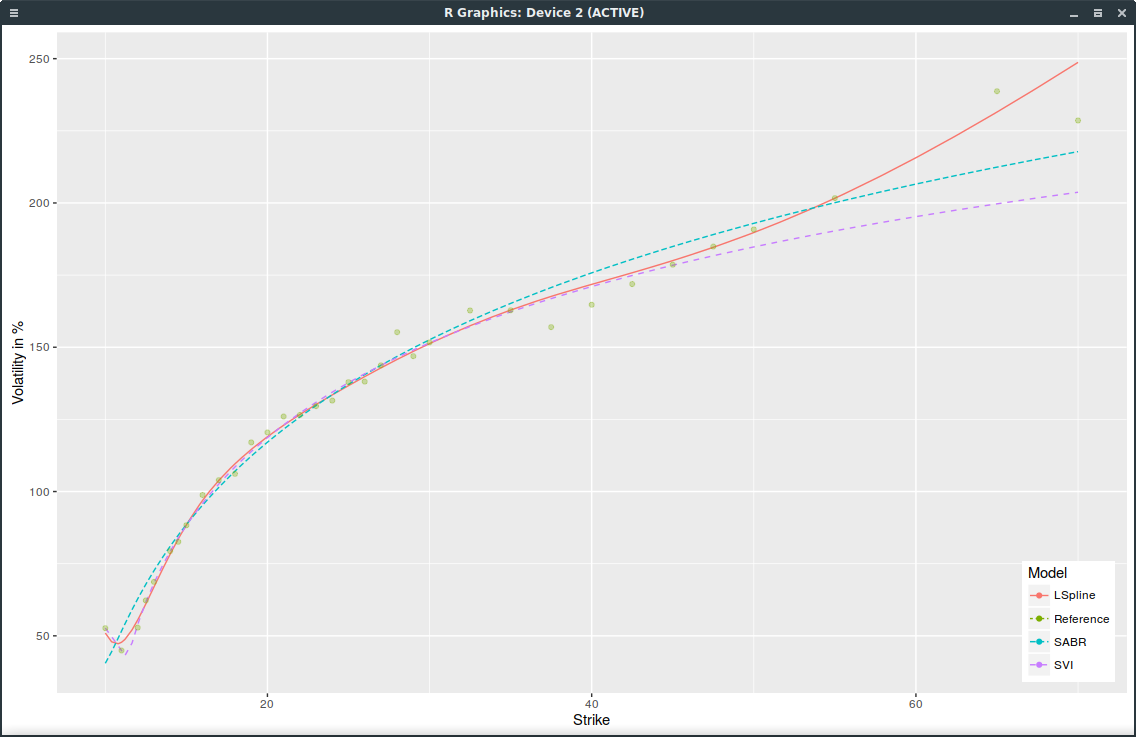
The VIX implied volatilities used to look like a logarithmic function of the strikes. I don’t look at them often, but today, I noticed that the VIX had the start of a smile shape.
1m VIX implied volatilities on March 21, 2017 with strictly positive volume.
Very few strikes trades below the VIX future level (12.9). All of this is likely because the VIX is unusually low: not many people are looking to trade it much lower.
Update March 22: Actually the smile in VIX is not particularly new, it is visible in Jim Gatheral 2013 presentation Joint modeling of SPX and VIX for the short maturities. Interestingly, the issue with SVI is also visible in those slides in the shortest maturity.
In order to fit the implied volatility smile of equity options, one of the most popular parameterization is Jim Gatheral’s SVI, which I have written about before here.
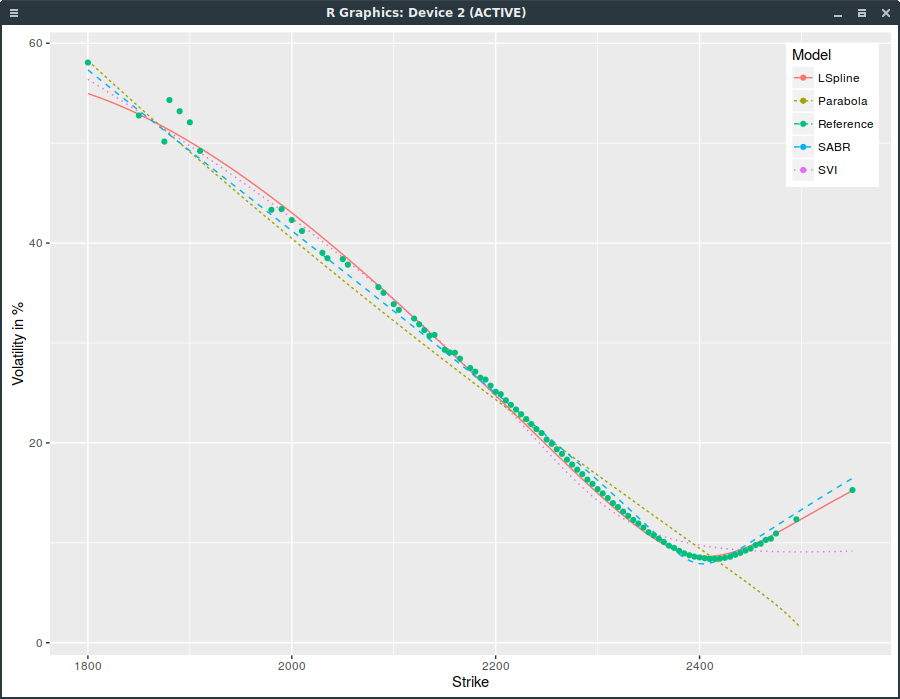
It turns out that in the current market conditions, SVI does not work well for short maturities. SPX options expiring on March 24, 2017 (one week) offer a good example. I paid attention to include only options with non zero volume, that is options that are actually traded.
SPXW implied volatilities on March 16, 2017 with strictly positive volume.
SVI does not fit well near the money (the SPX index is at 2385) and has an obviously wrong right wing. This is not due to the choice of weights used for the calibration (I used the volume as weight; equal weights would be even worse). Interestingly, SABR (with beta=1) does much better, even though it has two less parameters than SVI. Also a simple least squares parabola here does not work at all as it ends up fitting only the left wing.
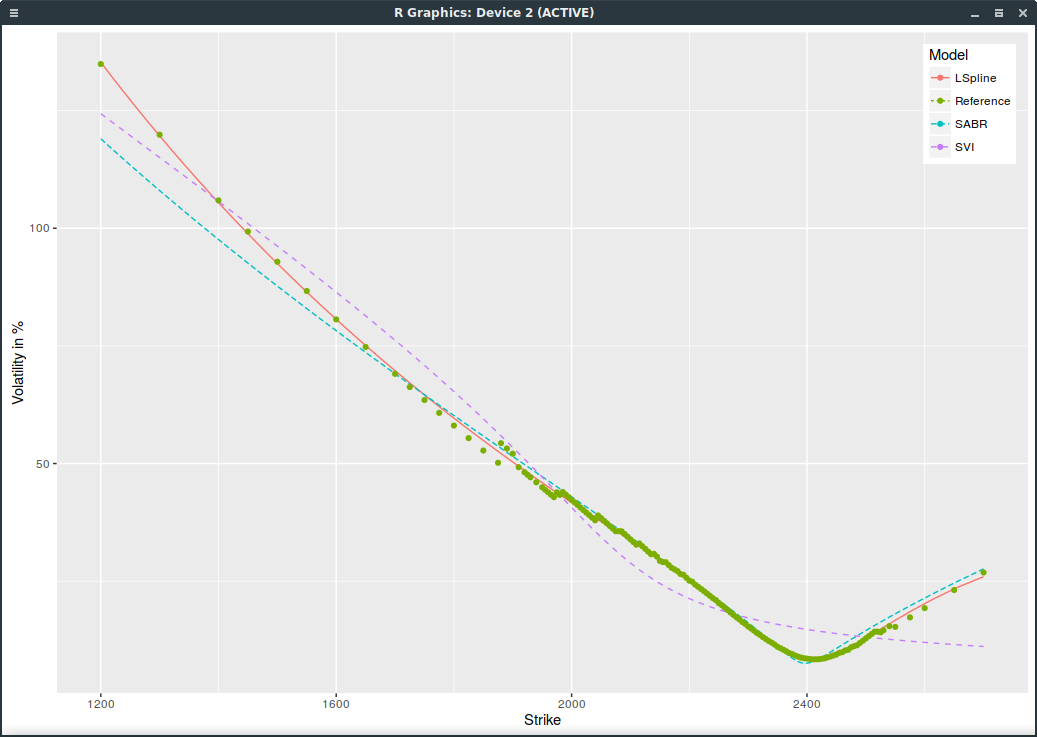
If we include all options with non zero open interest and use ask/(bid-ask) weights, SVI is even worse:
SPXW implied volatilities on March 16, 2017 with strictly positive open interest.
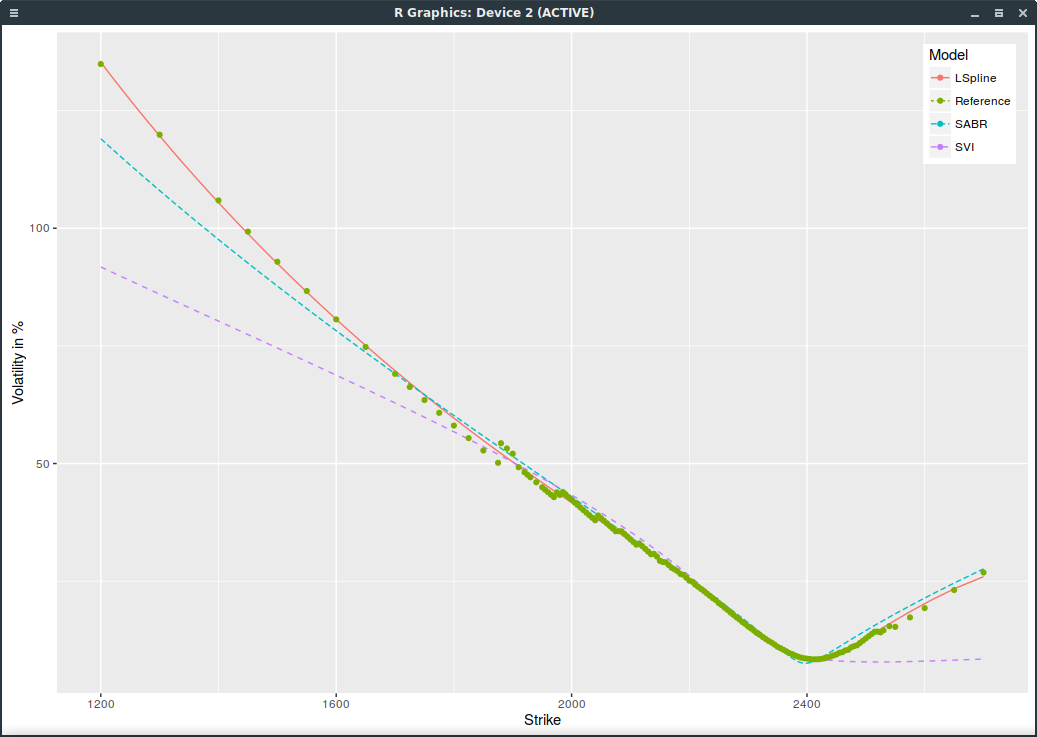
We can do a bit better with SVI by squaring the weights and it shows the problem of SVI more clearly:
SPXW implied volatilities on March 16, 2017 with strictly positive open interest and SVI weights squared.
These days, the VIX index is particularly low. Today, it is at 11.32. Usually, a low VIX translates to growing stocks as investors are confident in a low volatility environment. The catch with those extremely low ATM vols, is that the curvature is more pronounced, and so people are not so confident after all.
The new Heston discretisation scheme I wrote about a few weeks ago makes use
a discrete random variable matching the first five moments of the normal distribution instead of the usual
normally distributed random variable, computed via the inverse cumulative distribution function. Their discrete random
variable is:
$$\xi = \sqrt{1-\frac{\sqrt{6}}{3}} \quad \text{ if } U_1 < 3,,$$
$$ \xi =-\sqrt{1-\frac{\sqrt{6}}{3}} \quad \text{ if } U_1 > 4,,$$
$$\xi = \sqrt{1+\sqrt{6}} \quad \text{ if } U_1 = 3,,$$
$$\xi = -\sqrt{1+\sqrt{6}} \quad \text{ if } U_1 = 4,,$$
with \(U_1 \in \{0,1,…,7\}\)
The advantage of the discrete variable is that it is much faster to generate. But there are some interesting
side-effects. The first clue I found is a loss of accuracy on forward-start vanilla options.
By accident, I found a much more interesting side-effect: you can not use the Brownian-Bridge variance reduction
on the discrete random variable. This is very well illustrated by the case
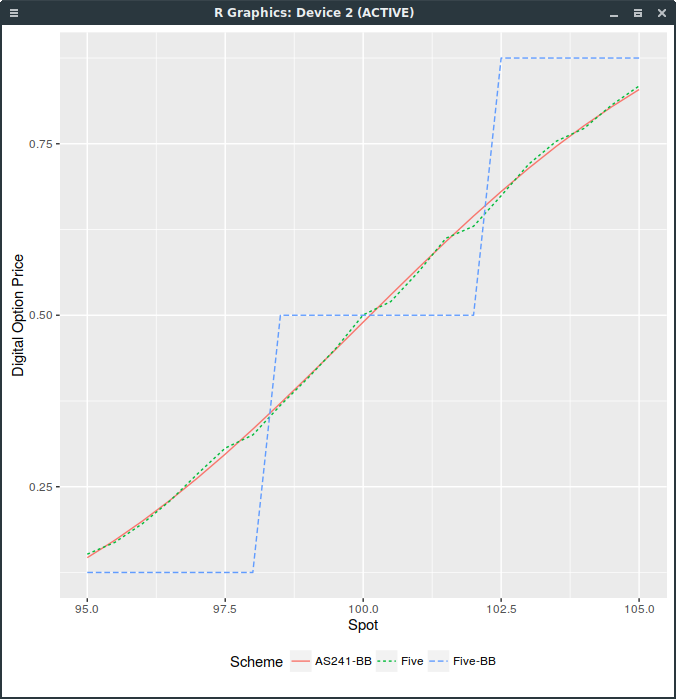
of a digital option in the Black model, for example with volatility 10% and a 3 months maturity, zero interest rate and dividends. For the following graph,
I use 16000 Sobol paths composed of 100 time-steps.
Digital Call price with different random variables.
The “-BB” suffix stands for the Brownian-Bridge path construction, “Five” for five moments discrete variable
and “AS241” for the inverse cumulative distribution function (continuous approach). As you can see,
the price is discrete, and follows directly from the discrete distribution.
The use of any random number generator with a large enough number of paths would lead to the same conclusion.
This is because with the Brownian-Bridge technique, the last point in the path, corresponding to the maturity,
is sampled first, and the other path points are then completed inside from the first and last points.
But the digital option depends only on the value of the path at maturity, that is, on this last point.
As this point corresponds follows our discrete distribution, the price of the digital option is a step function.
In contrast, for the incremental path construction, each point is computed from the previous point.
The last point will thus include the variation of all points in the path, which will be very close to normal, even with a discrete distribution per point.
The take-out to price more exotic derivatives (including forward-start options) with discrete random variables
and the incremental path construction, is that several intermediate time-steps (between payoff observations)
are a must-have with discrete random variables, however small is the original time-step size.
Furthermore, one can notice the discrete staircase even with a relavely small time-step for example of 1/32 (meaning 8 intermediate time-steps in
our digital option example). I suppose this is a direct consequence of the digital payoff discontinuity. In Talay
“Efficient numerical schemes for the approximation of expectations of functionals of the solution of a SDE, and applications” (which you can
read by adding .sci-hub.cc to the URL host name), second order convergence
is proven only if the payoff function and its derivatives up to order 6 are continuous. There is something natural
that a discrete random variable imposes continuity conditions on the payoff, not necessary with a continuous,
smooth random variable: either the payoff or the distribution needs to be smooth.
This is a note for those who want to setup a Samsung wireless printer under Linux. It is quite simple,
this forum post helped me, the actual useful steps on Fedora 25 are:
download tar.gz linux driver from Samsung website. As root, unpack & install:
tar xvzf SamsungPrinterInstaller.tar.gz
cd uld
./install.sh
in the printer menu, lookup for the wireless key (8 digits),
connect to the printer Wifi network with a computer using the wireless key,
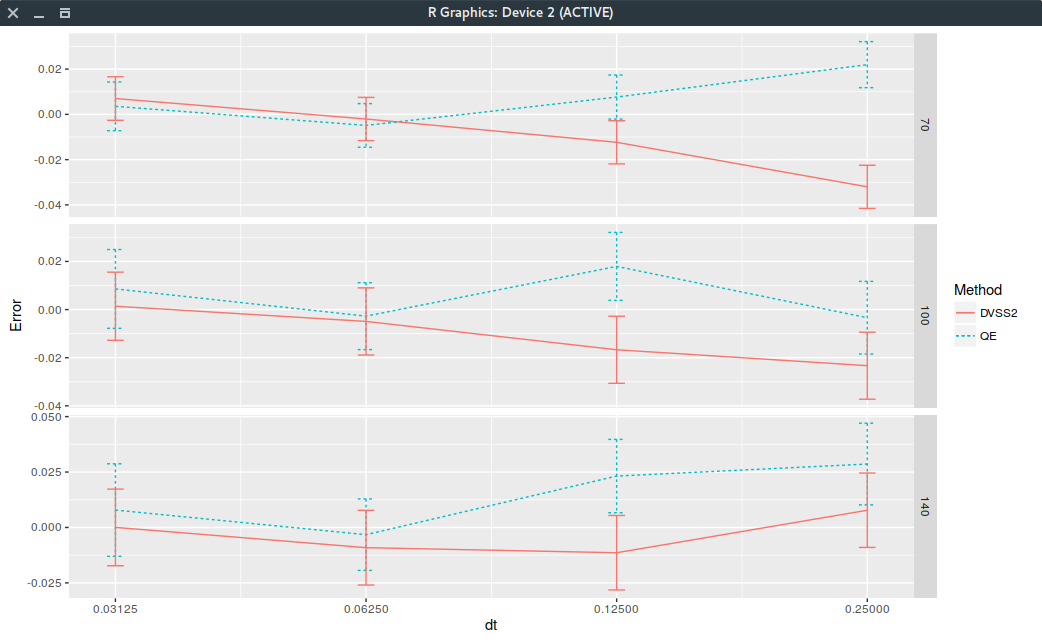
A couple weeks ago, I wrote about a new Heston discretisation scheme which was at least as accurate as Andersen QE scheme and faster, called DVSS2.
It turns out that it does not behave very well on the following Vanilla forward start option example (which is quite benign).
The Heston parameters comes from a calibration to the market and are
On a standard vanilla option, DVSS2 behaves as advertised in the paper but not on a forward-start option
with forward start date at \(T_1=\frac{7}{8}\) (relatively close to the maturity).
A forward start call option will pay \(\max(S(T)-k S(T_1),0)\).
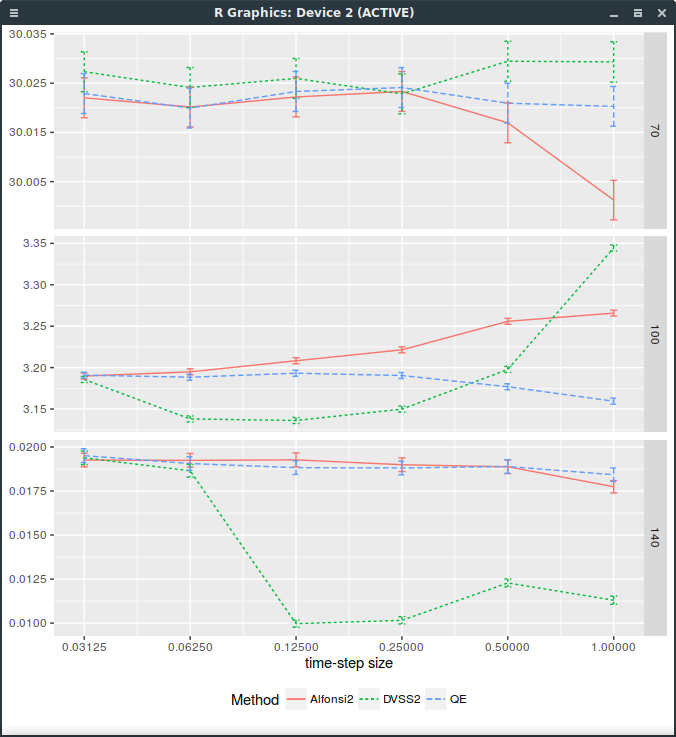
This is particularly visible on the following graph of the price against
the time-step size (1,1/2,1/4,1/8,1/16,1/32), for strikes 100% and 140% (it works well for strike=70%)
where 32 time-steps are necessary.
Forward start Call price with different discretization schemes.
It would appear that the forward dynamic is sometimes poorly captured by the DVSS2 scheme.
This makes DVSS2 not competitive in practice compared to Andersen’s QE or even Alfonsi as it can not be trusted
for a time step larger than 1/32.
Note that I insert an extra step at 7/8 for time step sizes greater or equal than 1/4: a time-step size of 1 corresponds in reality
to two time-steps respectively of size 7/8 and 1/8.
The error is actually because the log-asset process is sampled using a discrete random variables that matches
the first 5 moments of the normal distribution. The so-called step 5 of the algorithm specifies:
$$\hat{X} := \bar{x} + \xi \sqrt{\frac{1}{2}(\bar{y}+\hat{Y})h}$$
The notation is quite specific to the paper, what you need to know is that \(\hat{X}\) corresponds to the log-asset process
while \(\hat{Y}\) corresponds to the stochastic volatility process and \(\xi\) is the infamous discrete random variable.
In reality, there is no good reason to use a discrete random variable beside lowering the computational cost.
And it is obviously detrimental in the limit case where the volatility is deterministic (Black-Scholes case) as then
the log-process will only match the first 5 moments of the normal distribution, while it should be exactly normal.
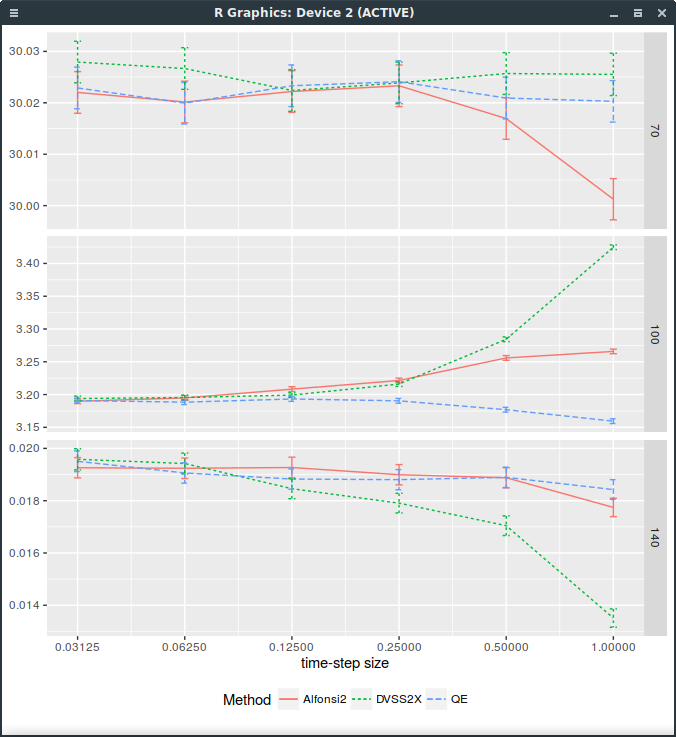
Replacing \(\xi\) by a standard normally distributed random variable is enough to fix DVSS2. Note
that it could also be discretized like the QE scheme, using a Broadie-Kaya interpolation scheme.
Forward start Call price with different discretization schemes. DVSS2X denotes here the scheme with continuous normal random variable.
The problem is that then, it is not faster than QE anymore. So it is not clear why it would be preferable.
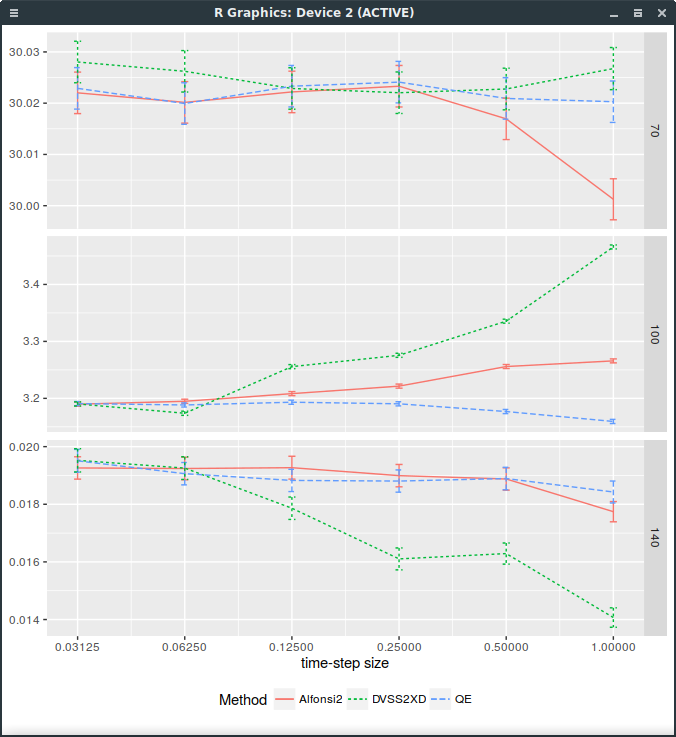
A discrete distribution matching the first 9 moments of the normal distribution
I then tried to see if matching more moments with a discrete distribution would help. More than 8 bits
are available when generating a uniform random double precision number (as it is represented by 53 bits).
The game is then to find nodes so that the distribution with discrete probabilities in i/256 with some interger i
match the moments of the normal distribution. It is a non linear problem unfortunately, but I found a solution
for the probabilities
While this helps a bit for small steps as shown on the following graph, it is far from good:
Forward start Call price with different discretization schemes. DVSS2X denotes here the scheme with discrete random variable matching the first 9 moments of the normal distribution.
The gnome shell has been crashing on me more regularly lately.
XFCE is a good and fast more tradional desktop, but, from past experiences,
it does not play well with power management if you only install it via
dnf install @xfce-desktop-environment
My typical experience is a black screen after resuming from suspend (sometimes, not always), or hibernate (always) and
most of the time I end up just rebooting. It turns out this is all caused by the interaction between the gdm login daemon and xfce. Moving
to the lightdm login daemon instead fixes those issues for Fedora 25:
Many papers present formulae to price Asian options in the Black-Scholes world only for the fixed strike Asian case, that is
a contract that pays \( \max(A-K,0)\) at maturity \(T\) where \(A = \sum_{i=0}^{n-1} w_i S(t_i) \) is the Asian average.
More generally, this can be seen as the payoff of a Basket option where the underlyings are just the same asset but at different times.
And any Basket option formula can actually be used to price fixed-strike Asian options by letting the correlation correspond to the correlation between the asset at the averaging times
and the variances correspond to the variance at each averaging time. The basket approach allows then naturally for a term-structure of rates, dividends and volatilities.
We have:
$$
V_{\textsf{floating}}(\eta,S_0,k,\bar{\sigma}_i^2 t_i, C(0,t_i), B(0,T)) =\\
\quad k V_{\textsf{fixed}}\left(-\eta,S_0, \frac{S_0}{k},\bar{\sigma}^2(T) T-\bar{\sigma}_i^2 t_i,\frac{C(0,t_i)}{C(0,T)},B(0,T)C(0,T) \right)
$$
where \(\eta = \pm 1\) for a call (respectively a put), \(\bar{\sigma}_i\) are the Vanilla options implied volatilities at the averaging times \(t_i\), \(C(0,t_i)\) are the capitalization factors, and \(B(0,T)\) is the discount factor.
Proof:
We assume that \(S\) follows \(dS = \mu_t S dt + \sigma_t S dW_t\). The discount factor \(B\) is defined as \(B(0,T)=e^{-\int_{0}^T r_s ds}\). Let \(C(0,t) = e^{\int_{0}^t \mu_s ds}\). The process associated to the forward to time \(t\) is \(F_t=S_0 C(0,t)M_t\) with \(M_t = e^{\int_0^t \sigma_s dW_s - \frac{1}{2}\int_0^t \sigma_s^2 ds}\) being a martingale.
We have:
$$
V_{\textsf{floating}}(\eta,S_0,k,\bar{\sigma}_i^2 t_i, C(0,t_i), B(0,T))\\
= B(0,T)\mathbb{E}\left[\max\left(\eta F_T-\eta k\sum_{i=0}^{n-1}w_i F_{t_i},0\right)\right]\\
= k B(0,T)\mathbb{E}\left[\max\left(\eta\frac{1}{k}F_T-\eta\sum_{i=0}^{n-1}w_i F_{t_i},0\right)\right]\\
=k B(0,T)C(0,T)\mathbb{E}\left[ M_T \max\left(\eta\frac{S_0}{k}-\eta\sum_{i=0}^{n-1}w_i S_0 \frac{C(0,t_i)M_{t_i}}{C(0,T) M_T },0\right)\right]
$$
We now proceed to a change of measure defined by \(M_T\). Under the new measure \(\mathbb{Q}^T\), \(\bar{W}_t = W_t - \int_0^t \sigma_s ds\) is a Brownian motion. \(\frac{M_t}{M_T}\) under \(\mathbb{Q}\) has the same law as \(\frac{M_t}{M_T} e^{-\int_t^T \sigma_s^2 ds}\) under \(\mathbb{Q}^T\) or equivalently as
\(\bar{M}_t = e^{\int_t^T \sigma_s d\bar{W}_s - \frac{1}{2}\int_t^T \sigma_s^2 ds}\) under \(\mathbb{Q}^T\).
Defining \(\mathbb{E}^T\) to be the expectation under \(\mathbb{Q}^T\), we thus have
$$
V_{\textsf{floating}}(\eta,S,k,\bar{\sigma}_i^2 t_i, C(0,t_i), B(0,T))\\
=k B(0,T)C(0,T)\mathbb{E}^{T}\left[\max\left(\eta\frac{S_0}{k}-\eta\sum_{i=0}^{n-1}w_i S_0 \frac{C(0,t_i)}{C(0,T)}\bar{M}_{t_i},0\right)\right]\\
=k V_{\textsf{fixed}}\left(-\eta,S_0, \frac{S_0}{k},\bar{\sigma}^2(T) T-\bar{\sigma}_i^2 t_i,\frac{C(0,t_i)}{C(0,T)},B(0,T)C(0,T) \right)
$$
This concludes the proof.
With the increasing use of the b.p. (a.k.a Normal, a.k.a Bachelier) vols, a natural question (that Gary asked) is:
Is there a similar rule for the Normal volatility?
It turns out that the answer is not as simple. It can easily be shown that the normal volatility can not grow faster than linear
in strike (not the variance this time). But it does not mean that linear is acceptable, in fact, it is not.
The upper bound can be refined to
$$ \frac{K-F}{\sqrt{2T \ln \frac{K}{F}}} $$
It is still an asymptotic upper bound only.
It can be shown that any number larger than the factor 2 in the denominator will not lead to asymptotic arbitrage.
The boundary could even be made tighter with, I suspect, additional terms in \( \ln \ln K \), but there is no
simple exact formula for the limit as in the Black-Scholes world.
I stumbled recently upon a new Heston discretisation scheme, in the spirit of Alfonsi, not more complex and more accurate.
My first attempt at coding the scheme resulted in a miserable failure even though the described algorithm looked
not too difficult. I started wondering if the paper, from a little known Lithuanian mathematical journal, was any good.
Still, the math in it is very well written, with a great emphasis on the settings for each proposition.
I decided to simply send an email to Prof. Mackevicius, and got a reply the next day (the internet is wonderful sometimes).
The exchange helped me to find out that the error was not where I was looking. After spending a bit more time on the paper, I discovered there was simply a missing step
in the algorithm.
In between step 3 and step 4, we should have
$$ \bar{x} = \frac{\bar{x}\sigma - \bar{y}\rho}{\sigma^2 \sqrt{1-\rho^2}}$$
$$ \bar{y} = \frac{\bar{y}}{\sigma^2}$$
corresponding to the transformation between equations 4.2 and 4.3 of the 2015 paper.
With the added step, the scheme works well. Even if there is clearly an effort from the authors to make their
very mathematically detailed paper more practical with a description of an algorithm, it looks like I have been the first person
to actually try it.
Jesper Andreasen and Brian Huge propose an arbitrage-free interpolation method
based on a single-step forward Dupire PDE solution in their paper Volatility interpolation.
To do so, they consider a piecewise constant representation of the local volatility in maturity time and strike
where the number of constants matches the number of market option prices.
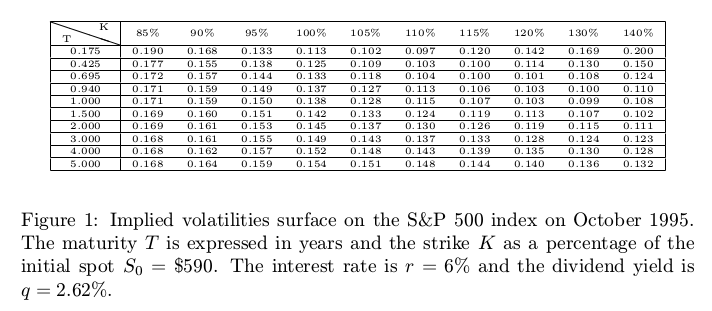
An interesting example that shows some limits to the technique as described in Jesper Andreasen and Brian Huge paper comes from
Nabil Kahale paper on an arbitrage-free interpolation of volatilities.
option volatilities for the SPX500 in October 1995.
Yes, the data is quite old, and as a result, not of so great quality. But it will well illustrate the issue.
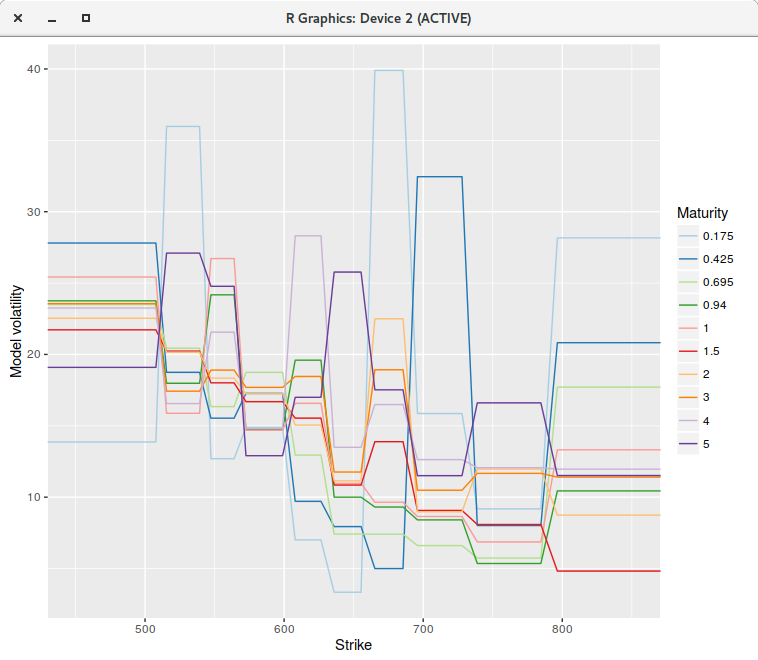
The calibration of the piecewise constant volatilities on a uniform grid of 200 points (on the log-transformed problem) leads to a perfect fit:
the market vols are exactly reproduced by the following piecewise constant vols:
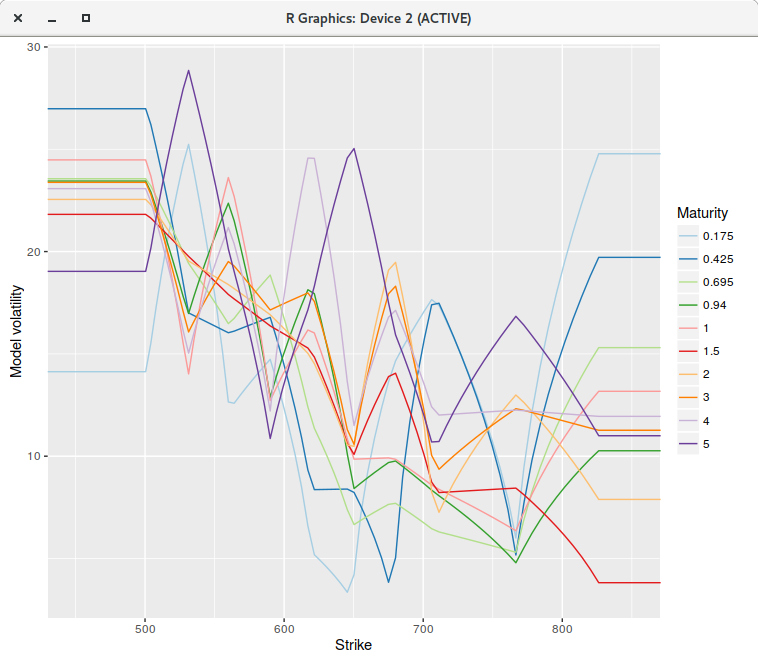
piecewise constant model on a grid of 200 points.
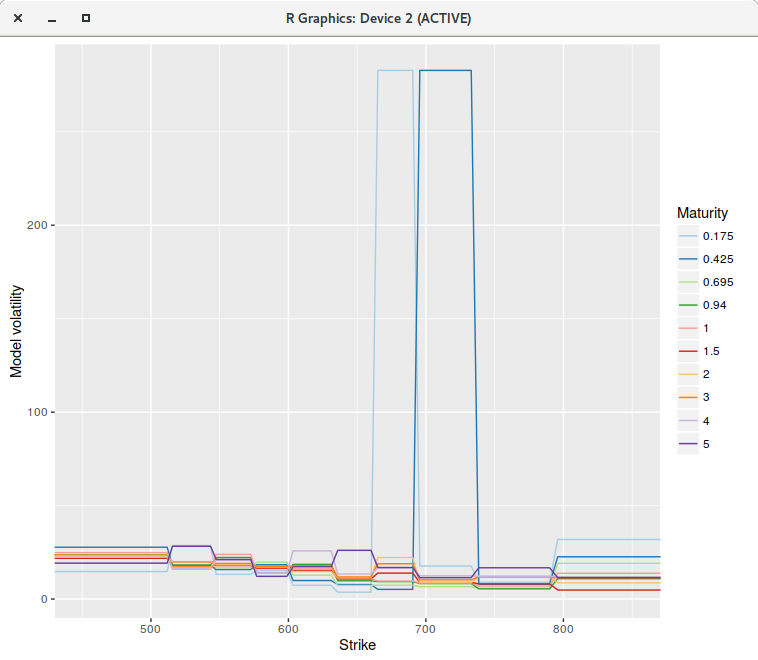
However, if we increase the number of points to 400 or even much more (to 2000 for example), the fit is not perfect anymore, and
some of the piecewise constant vols explode (for the first two maturities), even though there is no arbitrage in the market option prices.
piecewise constant model on a grid of 400 points.
The single step continuous model can not represent the market implied volatilities, while for some reason,
the discrete model with 200 points can. Note that the model vols were capped, otherwise they would explode even higher.
If instead of using a piecewise constant representation, we consider a continuous piecewise linear interpolation
(a linear spline with flat extrapolation), where each node falls on the grid point closest market strike, the calibration
becomes stable regardless of the number of grid points.
piecewise linear model on a grid of 400 points.
The RMSE is back to be close to machine epsilon. As a side effect the Levenberg-Marquardt minimization takes much less iterations to converge, either with 200 or 400 points when compared to the piecewise constant model,
likely because the objective function derivatives are smoother.
In the most favorable case for the piecewise constant model,
the minimization with the linear model requires about 40% less iterations.
We could also interpolate with a cubic spline, as long as we make sure that the volatility does not go below zero, for example by imposing a limit on the derivative values.
Overall, this raises questions on the interest of the numerically much more complex continuous time version of the piecewise-constant model
as described in Filling the gaps by Alex Lipton and Artur Sepp: a piecewise constant representation is too restrictive.