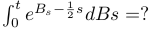Regularly, the unity dock made some applications inaccessible: clicking on the app icon did not show or start the app anymore, a very annoying bug. This is quite incredible given that this version of Ubuntu is supposed to be long term support. So I decided to give one more chance to Gnome Shell. Installing it on Ubuntu 12.04 is simple with this guide.
To my surprise it is very stable so far. Earlier Gnome Shell versions were not as stable. After installing various extensions (dock especially) it is as usable as Unity for my needs. It seems more responsive as well. I am not really into the Unity new features like HUD. It sounds to me like Ubuntu is making a mistake with Unity compared to Gnome Shell.
To make an old extension support latest Gnome Shell version, it is sometimes necessary to update the extension metadata with what's given by gnome-shell --version. For the weather extension you can just edit using gedit:
“Modify some of your utility object code to return new copies instead of self-mutating, and try throwing const in front of practically every non-iterator variable you use”.
Many people are not enthusiastic of this phone sound if you read silly forums. They are wrong! the sound coming out of this thin phone is amazing, at least with high quality headphones. I find the akg q601 incredible with it: much much better than with the old ipod nano or the cowon i7.
In general most complaints i have read about the phone were wrong. The battery is ok, the size is great.
In the past, I have seen that one could greatly improve performance of some Monte-Carlo simulation by using as much as possible double[][] instead of arrays of objects.
I am trying Scala again. Last time, several years ago, I played around with it as a web tool, combining it with a Servlet Runner like Tomcat. This time, I play around with it for some quantitative finance experiments.
Why Scala? It still seem the most advanced alternative to Java on the JVM, and the mix of functional programming and OO programming is interesting. Furthermore it goes quite far as it ships with its own library. I was curious to see if I could express some things better with Scala.
Here are my first impressions after a week:
I like the object keyword. It avoids the messy singleton pattern, or the classes with many static methods. I think it makes things much cleaner to not use static at all but distinguish between object & class.
I like the Array[Double], and especially ArrayBuffer[Double]. Finally we don't have to worry between the Double and double performance issues.
I was a bit annoyed by a(i) instead of a[i] but it makes sense. I wonder if there is a performance implication for arrays, hopefully not.
I like the real properties, automatic getter/setter: less boilerplate code, less getThis(), setThat(toto).
Very natural interaction with Java libraries.
I found a good use of case classes (to my surprise): typically an enum that can have some well defined parameters, and that you don't want to make a class (because it's not). My use case was to define boundaries of a spline.
I love the formatter in the scala (eclipse) IDE. Finally a formatter in eclipse that does not produce crap.
Now things I still need time to get used to:
member variable declared implicitly in the constructor. I first made the mistake (still?) to declare some variables twice.
I got hit by starting a line with a + instead of ending with a +. It is dangerous, but it certainly makes the code more consistent.
Performance impacts: I will need to take a look at the bytecode for some scala constructs to really understand the performance impact of some uses. For example I tend to use while loops instead of for comprehension after some scary post of the Twitter guys about for comprehension. But at first, it looks as fast as Java.
I wrote my code a bit fast. I am sure I could make use of more Scala features.
The scala IDE in eclipse 3.7.1 has known issues. I wish it was a bit more functional, but it's quite ok (search for references works, renaming works to some extent).
Scala unit tests: I used scala tests, but it seems a bit funny at first. Also I am not convinced by the syntax that avoid method names and prefer test("test name"). It makes it more difficult to browse the source code.
Some things they should consider:
Integrate directly a Log API. I just use SLF4J without any scala wrapper, but it feels like it should be part of the standard API (even if that did not work out so well for Sun).
Double.Epsilon is not the machine epsilon: very strange. I found out somewhere else there was the machine epsilon, don't remember where because I ended up just making a small object.
Unit tests should be part of the standard API.
Overall I found it quite exciting as there are definitely new ways to solve problems. It was a while since I had been excited with actual coding.
KDE 4.8 finally has a dock: you just have to add the plasma icon tasks. Also the flexibility around ALT+TAB is welcome. With Krusader as file manager, Thunderbird and Firefox for email and web, it is becoming a real nice desktop, but it took a while since the very bad KDE 4.0 release.
It is easy to install under ubuntu 11.10 through the backports and seems very stable so far.
Something quite important is to tweak the fonts: use Déjà Vu Sans instead of Ubuntu fonts, use RGB subpixel rendering, use Crisp desktop effects. With those settings, KDE looks very nice. It's sad that they are not default in Kubuntu.
Update March 2013: It's been a while now that it is in the standard Ubuntu repositories and I believe installed by default, one has just to remove the task manager widget add the icon task widget:
One can also change the settings using a right click (I find useful not to highlight the windows) and it can look like:
I have never really thought very much about generating random numbers according to a precise discrete distribution, for example to simulate an unfair dice.
In finance, we are generally interested in continuous distributions, where there is typically 2 ways:
The inverse transform is often preferred, because it’s usable method for Quasi Monte-Carlo simulations while the acceptance rejection is not.I would have thought about the simple way to generate random numbers according to a discrete distribution as first described here. But establishing a link with Huffman encoding is brilliant. Some better performing alternative (unrelated to Huffman) is offered there.
Recently, I interviewed someone for a quant position. I was very surprised to find out that someone who did one of the best master in probabilities and finance in France could not solve a very basic probability problem:
This is accessible to someone with very little knowledge of probabilities
When I asked this problem around to co-workers (who have all at least a master in a scientific subject), very few could actually answer it properly. Most of the time, I suspect it is because they did not dedicate enough time to do it properly, and wanted to answer it too quickly.
It was more shocking that someone just out of school, with a major in probabilities could not answer that properly. It raises the question: what is all this education worth?
The results were not better as soon as the question was not exactly like what students in those masters are used to, like for example, this simple stochastic calculus question:
My opinion is that, today in our society, people study for too long. The ideal system for me would be one where people learn a lot in math/physics the first 2 years of university, and then have more freedom in their education, much like a doctorate.
We still offered the job to this person, because live problem solving is not the most important criteria. Other qualities like seriousness and motivation are much more valuable.
In a previous post, I was complaining how bad Gnome 3 was. Since I have installed a real dock: docky, it is now much more usable. I can easily switch / launch applications without an annoying full screen change.
In addition I found out that it had a good desktop search (tracker). The ALT+F2 also does some sort of completion, too bad it can not use tracker here as well.
So it looks like Gnome 3 + gnome-tweak-tool + docky makes a reasonably good desktop. XFCE does not really fit the bill for me: bad handling of sound, bad default applications, not so good integration with gnome application notifications.
Now if only I found a way to change this ugly big white scrollbar…