Sometimes it feels like big companies try to enforce the Productivity Zero rule.
Here is a guide:
involve as many team as possible. It will help ensuring endless discussions about who is doing what, and then how do I interface with them. This is most (in)efficient when team managers interact and are not very technically competent. One consequence is that nobody is fully responsible/accountable, which helps reinforce the productivity zero.
meetings, meetings and meetings. FUD (Fear Uncertainty and Doubt) is king here. By spreading FUD, there will be more and more meetings. Even if the “project” is actually not a real project, but amounts to 10 lines of code, it is possible to have many meetings around it, over the span of several months (because everybody is always busy with other tasks). Another strategy is to use vocabulary, talk about technical or functional parts the others don’t understand. Some people are masters are talking technical to functional people and vice versa.
multiply by 20, not 2. It is surprisingly easy to tell upper management something is going to take 3 months, when, in fact, it can be done in 3 days. This is a bit like bargaining in South East Asia: it’s always amazing to find out how much you can push the price down (or how much they push it up).
hire as many well paid managers and product specialists as you can, and make sure they know nothing about the product or the functional parts but are very good at playing the political game without any content. Those people often manage to stay a long time, a real talent.
In Pricing Financial Instruments - The Finite Difference Method, Tavella and Randall explain that boundary conditions using a higher order discretization (for example their “BC2” boundary condition) can not be solved in one pass with a simple tridiagonal solver, and suggest the use of SOR or some conjugate gradient based solver.
It is actually very simple to reduce the system to a tridiagonal system. The more advanced boundary conditions only use 3 adjacent values, just 1 value makes it non tridiagonal, the one in bold is the following matrix representation
x x x
x x x
x x x
……
x x x
x x x
x x x
One just needs to replace the first line by a simple linear combination of the first 2 lines to remove the extra x and similarly for the last 2 lines. This amounts to ver little computational work. Then one can use a standard tridiagonal solver. This is how I implemented it in a past post about boundary conditions of a bond in the CIR model. It is very surprising that they did not propose that simple solution in an otherwise very good book.
I was looking for an implementation of the non central chi squared distribution function in Java, in order to price bond options under the Cox Ingersoll Ross (CIR) model and compare to a finite difference implementation. It turned out it was not so easy to find existing code for that in a library. I would have imagined that Apache common maths would do this but it does not.
OpenGamma has a not too bad implementation. It relies on Apache commons maths for the Gamma function implementation. I looked at what was there in C/C++. There is some old fortran based ports with plenty of goto statements. There is also a nice implementation in the Boost library. It turns out it is quite easy to port it to Java. One still needs a Gamma function implementation, I looked at Boost implementation of it and it turns out to be very similar to the Apache commons maths one (which is surprisingly not too object oriented and therefore quite fast - maybe they ported it from Boost or from a common source).
The Boost implementation seems much more robust in general thanks to:
The use of complimentary distribution function when the value is over 0.5. One drawback is that there is only one implementation of this, the Benton and Krishnamoorthy one, which is a bit slower than Ding's method.
It is interesting to note that both implementations of Ding method are wildly different, Boost implementation has better performance and is simpler (I measured that my Java port is around 50% faster than OpenGamma implementation).
If only it was simple to commit to open-source projects while working for a software company...
A while ago, someone asked me to reference him in a paper of mine because I used formulas of a finite difference approximation of a derivative on a non uniform grid. I was shocked as those formula are very widespread (in countless papers, courses and books) and not far off elementary mathematics.
There are however some interesting old papers on the technique. Usually people approximate the first derivative by the central approximation of second order:
However there are some other possibilities. For example one can find a formula directly out of the Taylor expansions of \(f(x_{i+1})\) and \(f(x_{i-1})\). This paper and that one seems to indicate it is more precise, especially when the grid does not vary smoothly (a typical example is uniform by parts).
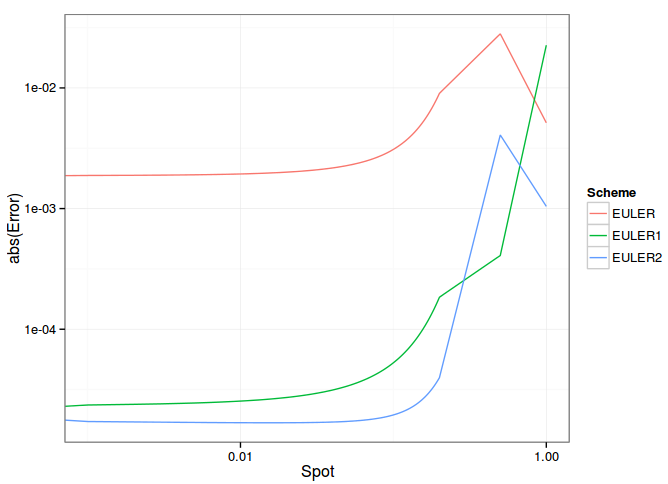
This can make a big difference in practice, here is the example of a Bond priced under the Cox-Ingersoll-Ross model by finite differences. EULER is the classic central approximation, EULER1 uses the more refined approximation based on Taylor expansion, EULER2 uses Taylor expansion approximation as well as a higher order boundary condition. I used the same parameters as in the Tavella-Randall book example and a uniform grid between [0, 0.2] except that I have added 2 points at the far end at 0.5 and 1.0. So the only difference between EULER and EULER1 lies in the computation of derivatives at the 3 last points.
I also computed the backward 2nd order first derivative on a non uniform grid (for the refined boundary). I was surprised not to find this easily on the web, so here it is:
$$ f’(x_i) = \left(\frac{1}{h_i}+\frac{1}{h_i+h_{i-1}}\right) f(x_i)- \left(\frac{1}{h_{i-1}}+\frac{1}{h_i}\right) f(x_{i-1})+ \left(\frac{1}{h_{i-1}} - \frac{1}{h_i+h_{i-1}} \right) f(x_{i-2}) + …$$
Incidently while writing this post I found out it was a pain to write Math in HTML (I initially used a picture). MathML seems a bit crazy, I wonder why they couldn’t just use the LaTeX standard.
Update January 3rd 2013 - I now use Mathjax. It’s not very good solution as I think this should typically be handled by the browser directly instead of huge javascript library, but it looks a bit better
I am comparing various finite difference schemes on simple problems and am currently stumbling upon a strange discontinuity at the boundary for some of the schemes (Crank-Nicolson, Rannacher, and TR-BDF2) when I plot an American Put Option Gamma using a log grid. It actually is more pronounced with some values of the strike, not all. The amplitude oscillates with the strike. And it does not happen on a European Put, so it's not a boundary approximation error in the code. It might well be due to the nature of the scheme as schemes based on implicit Euler work (maybe monotonicity preservation is important). This appears on this graph around S=350.
Update December 13, 2012: after a close look at what was happening. It was after all a boundary issue. It's more visible on the American because the Gamma is more spread out. But I reproduced it on a European as well.
I spent quick a bit of time to figure out why something that is usually simple to do in Java did not work in Scala: Arrays and ArrayLists with generics.
For some technical reason (type erasure at the JVM level), Array sometimes need a parameter with a ClassManifest !?! a generic type like [T :< Point : ClassManifest] need to be declared instead of simply [T :< Point].
And then the quickSort method somehow does not work if invoked on a generic… like quickSort(points) where points: Array[T]. I could not figure out yet how to do this one, I just casted to points.asInstanceOf[Array[Point]], quite ugly.
In contrast I did not even have to think much to write the Java equivalent. Generics in Scala, while having a nice syntax, are just crazy. This is something that goes beyond generics. Some of the Scala library and syntax is nice, but overall, the IDE integration is still very buggy, and productivity is not higher
Update Dec 12 2012: here is the actual code (this is kept close to the Java equivalent on purpose):
objectPoint{def sortAndRemoveIdenticalPoints[T<:Point:ClassManifest](points :Array[T]):Array[T]={Sorting.quickSort(points.asInstanceOf[Array[Point]])val l =newArrayBuffer[T](points.length)var previous = points(0) l += points(0)for(i <-1 until points.length){if(math.abs(points(i).value - previous.value)<Epsilon.MACHINE_EPSILON_SQRT){ l += points(i)}}return l.toArray
}return points
}classPoint(val value:Double,val isMiddle:Boolean)extendsOrdered[Point]{def compare(that:Point):Int={return math.signum(this.value - that.value).toInt
}}
In Java one can just use Arrays.sort(points) if points is a T[]. And the method can work with a subclass of Point.
This will be a very technical post, I am not sure that it will be very understandable by people not familiar with the implied volatility surface.
Something one notices when computing an option price under local volatility using a PDE solver, is how different is the Delta from the standard Black-Scholes Delta, even though the price will be very close for a Vanilla option. In deed, the Finite difference grid will have a different local volatility at each point and the Delta will take into account a change in local volatility as well.
But this finite-difference grid Delta is also different from a standard numerical Delta where one just move the initial spot up and down, and takes the difference of computed prices. The numerical Delta will eventually include a change in implied volatility, depending if the surface is sticky-strike (vol will stay constant) or sticky-delta (vol will change). So the numerical Delta produced with a sticky-strike surface will be the same as the standard Black-Scholes Delta. In reality, what happens is that the local volatility is different when the spot moves up, if we recompute it: it is not static. The finite difference solver computes Delta with a static local volatility. If we call twice the finite difference solver with a different initial spot, we will reproduce the correct Delta, that takes into account the dynamic of the implied volatility surface.
Here how different it can be if the delta is computed from the grid (static local volatility) or numerically (dynamic local volatility) on an exotic trade:
This is often why people assume the local volatility model is wrong, not consistent. It is wrong if we consider the local volatility surface as static to compute hedges.
After too many upgrades of Ubuntu, and switching from Gnome to KDE and back, my Ubuntu system became behaving strangely in KDE: authorization issues, frequent crashes, pulseaudio and ardour problems. I decided to give another try to OpenSuse, as Linux makes it easy to switch system without losing too much time reinstalling the useful applications.
It’s been only a few days, but I am pleasantly surprised with OpenSuse. It feels more polished than Kubuntu. I could not point out to a specific feature, but so far I have not had to fiddle with any configuration file, everything works well out of the box. Somehow Kubuntu always felt flaky, read to break at any moment, while OpenSuse feels solid. But they should consider changing the default font settings in KDE to take advantage properly of antialiasing and pretty fonts (it’s only a few clicks away, but still the default is not the prettiest).
It's a bit incredible, but in 2012, some linux distros (like Fedora, or Kubuntu) still have trouble to have pretty fonts everywhere. I found a nice tip initially for Google Chrome but that seems to improve more than Chrome: create ~/.fonts.conf with the following: