In the book Monte Carlo Methods in Financial Engineering, Glasserman explains that if one reuses the paths used in the optimization procedure for the parameters of the exercise boundary (in this case the result of the regression in Longstaff-Schwartz method) to compute the Monte-Carlo mean value, we will introduce a bias: the estimate will be biased high because it will include knowledge about future paths.
However Longstaff and Schwartz seem to just reuse the paths in their paper, and Glasserman himself, when presenting Longstaff-Schwartz method later in the book just use the same paths for the regression and to compute the Monte-Carlo mean value.
How large is this bias? What is the correct methodology?
I have tried with Sobol quasi random numbers to evaluate that bias on a simple Bermudan put option of maturity 180 days, exercisable at 30 days, 60 days, 120 days and 180 days using a Black Scholes volatility of 20% and a dividend yield of 6%. As a reference I use a finite difference solver based on TR-BDF2.
I found it particularly difficult to evaluate it: should we use the same number of paths for the 2 methods or should we use the same number of paths for the monte carlo mean computation only? Should we use the same number of paths for regression and for monte carlo mean computation or should the monte carlo mean computation use much more paths?
I have tried those combinations and was able to clearly see the bias only in one case: a large number of paths for the Monte-Carlo mean computation compared to the number of paths used for the regression using a fixed total number of paths of 256*1024+1, and 32*1024+1 paths for the regression.
Those numbers are too good to be a real. If one reduces too much the total number of paths or the number of paths for the regression, the result is not precise enough to see the bias. For example, using 4K paths for the regression leads to 2.83770 vs 2.83767. Using 4K paths for regression and only 16K paths in total leads to 2.8383 vs 2.8387. Using 32K paths for regressions and increasing to 1M paths in total leads to 2.838539 vs 2.838546.
For this example the Longstaff-Schwartz price is biased low, the slight increase due to path reuse is not very visible and most of the time does not deteriorate the overall accuracy. But as a result of reusing the paths, the Longstaff-Schwartz price might be higher than the real value.
In finance, because one often dicretize the log process instead of the direct process for Monte-Carlo simulation, the Math.exp function can be called a lot (millions of times for a simulation) and can be a bottleneck. I have noticed that the simpler Euler discretization was for local volatility Monte-Carlo around 30% faster, because it avoids the use of Math.exp.
Can we improve the speed of exp over the JDK one? At first it would seem that the JDK would just call either the processor exp using an intrinsic function call and that should be difficult to beat. However what if one is ok for a bit lower accuracy? Could a simple Chebyshev polynomial expansion be faster?
Out of curiosity, I tried a Chebyshev polynomial expansion with 10 coefficients stored in a final double array. I computed the coefficient using a precise quadrature (Newton-Cotes) and end up with 1E-9, 1E-10 absolute and relative accuracy on [-1,1].
Here are the results of a simple sum of 10M random numbers:
0.75s for Math.exp sum=1.7182816693332244E7 0.48s for ChebyshevExp sum=1.718281669341388E7 0.40s for FastMath.exp sum=1.7182816693332244E7
So while this simple implementation is actually faster than Math.exp (but only works within [-1,1]), FastMath from Apache commons maths, that relies on a table lookup algorithm is just faster (in addition to being more precise and not limited to [-1,1]).
Of course if I use only 5 coefficients, the speed is better, but the relative error becomes around 1e-4 which is unlikely to be satisfying for a finance application.
0.78s for Math.exp sum=1.7182816693332244E7 0.27s for ChebyshevExp sum=1.718193001875838E7 0.40s for FastMath.exp sum=1.7182816693332244E7
Scaling: scaling the call price appropriately allows to increase the maximum precision significantly, because the Carr-Madan formula operates on log(Forward) and log(Strike) directly, but not the ratio, and alpha is multiplied by the log(Forward). I simply scale by the spot, the call price is (S_0*max(S/S_0-K/S0)). Here are the results for Lord-Kahl, Kahl-Jaeckel (the more usual way limited to machine epsilon accuracy), Forde-Jacquier-Lee ATM implied volatility without scaling for a maturity of 1 day:
Strike
Lord-Kahl
Kahl-Jaeckel
Forde-Jacquier-Lee
62.5
2.919316809400033E-34
8.405720564041985E-12
0.0
68.75
-8.923683388191852E-28
1.000266536266281E-11
0.0
75.0
-3.2319611910032E-22
2.454925152051146E-12
0.0
81.25
1.9401743410877718E-16
2.104982854689297E-12
0.0
87.5
-Infinity
-1.6480150577535824E-11
0.0
93.75
Infinity
1.8277663826893331E-9
1.948392142070432E-9
100.0
0.4174318393886519
0.41743183938679845
0.4174314959743768
106.25
1.326968012594355E-11
7.575717830832218E-11
1.1186618909114702E-11
112.5
-5.205783145942609E-21
2.5307755890935368E-11
6.719872683111381E-45
118.75
4.537094156599318E-25
1.8911094912255066E-11
3.615356241778357E-114
125.0
1.006555799739525E-27
3.2365221613872563E-12
2.3126009701775733E-240
131.25
4.4339539263484925E-31
2.4794388764348696E-11
0.0
One can see negative prices and meaningless prices outside ATM. With scaling it changes to:
Strike
Lord-Kahl
Kahl-Jaeckel
Forde-Jacquier-Lee
62.5
2.6668642552659466E-182
8.405720564041985E-12
0.0
68.75
7.156278101597845E-132
1.000266536266281E-11
0.0
81.25
7.863105641534119E-55
2.104982854689297E-12
0.0
87.5
7.073641308465115E-28
-1.6480150577535824E-11
0.0
93.75
1.8375145950924849E-9
1.8277663826893331E-9
1.948392142070432E-9
100.0
0.41743183938755385
0.41743183938679845
0.4174314959743768
106.25
1.3269785342953315E-11
7.575717830832218E-11
1.1186618909114702E-11
112.5
8.803247187972696E-42
2.5307755890935368E-11
6.719872683111381E-45
118.75
5.594342441346233E-90
1.8911094912255066E-11
3.615356241778357E-114
125.0
7.6539757567179276E-149
3.2365221613872563E-12
2.3126009701775733E-240
131.25
0.0
2.4794388764348696E-11
0.0
One can now now see that the Jacquier-Lee approximation is quickly not very good.
Put: the put option price can be computed using the exact same Carr-Madan formula, but using a negative alpha instead of a positive alpha. When I derived this result (by just reproducing the Carr-Madan steps with the put payoff instead of the call payoff), I was surprised, but it works.
In my previous post, I explored the Lord-Kahl method to compute the call option prices under the Heston model. One of the advantages of this method is to go beyond machine epsilon accuracy and be able to compute very far out of the money prices or very short maturities. The standard methods to compute the Heston price are based on a sum/difference where both sides are far from 0 and will therefore be limited to less than machine epsilon accuracy even if the integration is very precise.
However the big trick in it is to find the optimal alpha used in the integration. A suboptimal alpha will often lead to high inaccuracy, because of some strong oscillations that will appear in the integration. So the method is robust only if the root finding (for the optimal alpha) is robust.
The original paper looks the Ricatti equation for B where B is the following term in the characteristic function:
$$\phi(u) = e^{iuf+A(u,t)+B(u,t)\sigma_0}$$
The solution defines the \(\alpha_{max}\) where the characteristic function explodes. While the Ricatti equation is complex but not complicated:
$$ dB/dt = \hat{\alpha}(u)-\beta(u) B+\gamma B^2 $$
I initially did not understand its role (to compute \(\alpha_{max}\)), so that, later, one can compute alpha_optimal with a good bracketing. The bracketing is particularly important to use a decent solver, like the Brent solver. Otherwise, one is left with, mostly, Newton’s method. It turns out that I explored a reduced function, which is quite simpler than the Ricatti and seems to work in all the cases I have found/tried: solve $$1/B = 0$$ If B explodes, \(\phi\) will explode. The trick, like when solving the Ricatti equation, is to have either a good starting point (for Newton) or, better, a bracketing. It turns out that Lord and Kahl give a bracketing for (1/B), even if they don’t present it like this: their \(\tau_{D+}\) on page 10 for the lower bracket, and \(\tau_+\) for the upper bracket. \(\tau_+\) will make \(1/B\) explode, exactly. One could also find the next periods by adding \(4\pi/t\) instead of \(2\pi/t\) like they do to move from \(\tau_{D+}\) to \(\tau_+\). But this does not have much interest as we don’t want to go past the first explosion.
It’s quite interesting to see that my simple approach is actually closely related to the more involved Ricatti approach. The starting point could be the same. Although it is much more robust to just use Brent solver on the bracketed max. I actually believe that the Ricatti equation explodes at the same points, except, maybe for some rare combination of Heston parameters.
From a coding perspective, I found that Apache commons maths was a decent library to do complex calculus or solve/minimize functions. The complex part was better than some in-house implementation: for example the square root was more precise in commons maths, and the solvers are robust. It even made me think that it is often a mistake to reinvent to wheel. It’s good to choose the best implementations/algorithms as possible. But reinventing a Brent solver??? a linear interpolator??? Also the commons maths library imposes a good structure. In house stuff tends to be messy (not real interfaces, or many different ones). I believe the right approach is to use and embrace/extends Apache commons maths. If some algorithms are badly coded/not performing well, then write your own using the same kind of interfaces as commons maths (or some other good maths library).The next part of this series on Lord-Kahl method is here.
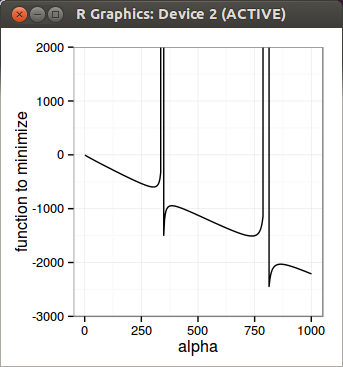
I just tried to implement Lord Kahl algorithm to compute the Heston call price. The big difficulty of their method is to find the optimal alpha. That’s what make it work or break. The tricky part is that the function of alpha we want to minimize has multiple discontinuities (it’s periodic in some ways). This is why the authors rely on the computation of an alpha_max: bracketing is very important, otherwise your optimizer will jump the discontinuity without even noticing it, while you really want to stay in the region before the first discontinuity.
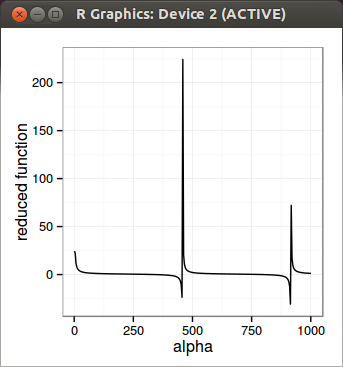
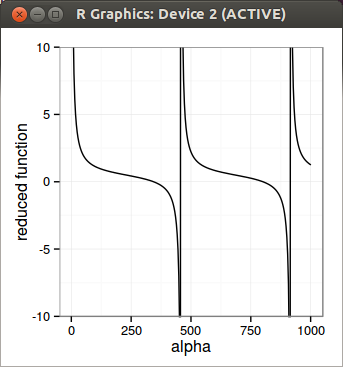
To find alpha_max, they solve a non linear differential equation, for which I would need a few more readings to really understand it. Given that the problem looked simple: if you graph the function to minimize, it seems so simple to find the first discontinuity. So I just tried to do it directly. Numerically, I was surprised it was not so simple. I did find a solution that, amazingly seems to work in all the examples of the paper, but it’s luck. I use Newton-Raphson to find the discontinuity, on a reduced function where the discontinuity really lies. I solve the inverse of the discontinuity so that I can just solve for 0. Earlier on I reduced the function too much and it did not work, this is why I believe it is not very robust. Newton-Raphson is quite simple, but also simple to understand why it breaks if it breaks, and does not need a bracketing (what I am looking for in the first place). Once I find the discontinuity, I can just use Brent on the right interval and it works well.
In the end, it’s neat to be able to compute option prices under machine epsilon. But in practice, it’s probably not that useful. For calibration, those options should have a very small (insignificant) weight. The only use case I found is really for graphing so that you don’t have some flat extrapolation too quickly, especially for short maturities. I was curious as well about the accuracy of some approximations of the implied volatility in the wings, to see if I could use them instead of all this machinery.
In any case I did not think that such a simple problem was so challenging numerically.
Marsaglia in his paper on Normal Distribution made the same mistake I initially did while trying to verify the accuracy of the normal density.In his table of values comparing the true value computed by Maple for some values of x to the values computed by Sun or Ooura erfc, he actually does not really use the same input for the comparison. One example is the last number: 16.6. 16.6 does not have an exact representation in double precision, even though it is displayed as 16.6 because of the truncation at machine epsilon precision. Using Python mpmath, one can see that:>>> mpf(-16.6)mpf(’-16.6000000000000014210854715202004’)This is the more accurate representation if one goes beyond double precision (here 30 digits). And the value of the cumulative normal distribution is:>>> ncdf(-16.6)mpf(‘3.4845465199503256054808152068743e-62’)It is different from:>>> ncdf(mpf("-16.6"))mpf(‘3.48454651995040810217553910503186e-62’)where in this case it is really evaluated around -16.6 (up to 30 digits precision). Marsaglia gives this second number as reference. But all the other algorithms will actually take as input the first input. It is more meaningful to compare results using the exact same input. Using human readable but computer truncated numbers is not the best. The cumulative normal distribution will often be computed using some output of some calculation where one does not have an exact human readable input.The standard code for Ooura and Schonfelder (as well as Marsaglia) algorithms for the cumulative normal distribution don’t use Cody’s trick to evaluate the exp(-xx). This function appears in all those implementations because it is part of the dominant term in the usual expansions. Out of curiosity, I replaced this part with Cody trick. For Ooura I also made minor changes to make it work directly on the CND instead of going through the error function erfc indirection. Here are the results without the Cody trick (except for Cody):and with it:All 3 algorithms are now of similiar accuracy (note the difference of scale compared to the previous graph), with Schonfelder being a bit worse, especially for x >= -20. If one uses only easily representable numbers (for example -37, -36,75, -36,5, …) in double precision then, of course, Cody trick importance won’t be visible and here is how the 3 algorithms would fare with or without Cody trick:Schonfelder looks now worse than it actually is compared to Cody and Ooura.To conclude, if someone claims that a cumulative normal distribution is up to double precision accuracy and it does not use any tricks to compute exp(-xx), then beware, it probably is quite a bit less than double precision.
In my previous post, I stated that some library (SPECFUN by W.D. Cody) computes \(e^{-\frac{x^2}{2}}\) the following way:
xsq =fint(x *1.6) /1.6;
del = (x - xsq) * (x + xsq);
result =exp(-xsq * xsq *0.5) *exp(-del *0.5);
where fint(z) computes the floor of z.
Why 1.6?
An integer divided by 1.6 will be an exact representation of the corresponding number in double: 1.6 because of 16 (dividing by 1.6 is equivalent to multiplying by 10 and dividing by 16 which is an exact operation). It also allows to have something very close to a rounding function: x=2.6 will make xsq=2.5, x=2.4 will make xsq=1.875, x=2.5 will make xsq=2.5. The maximum difference between x and xsq will be 0.625.
(a-b) * (a+b) decomposition
del is of the order of 2* x * (x-xsq). When (x-xsq) is very small, del will, most of the cases be small as well: when x is too high (beyond 39), the result will always be 0, because there is no small enough number to represent exp(-0.5*39*39) in double precision, while (x-xsq) can be as small as machine epsilon (around 2E-16). By splitting x * x into xsq * xsq and del, the exp function works on a more refined value of the remainder del, which in turn should lead to an increase of accuracy.
Real world effect
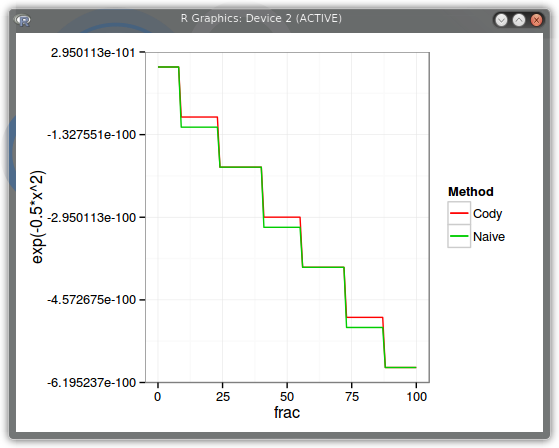
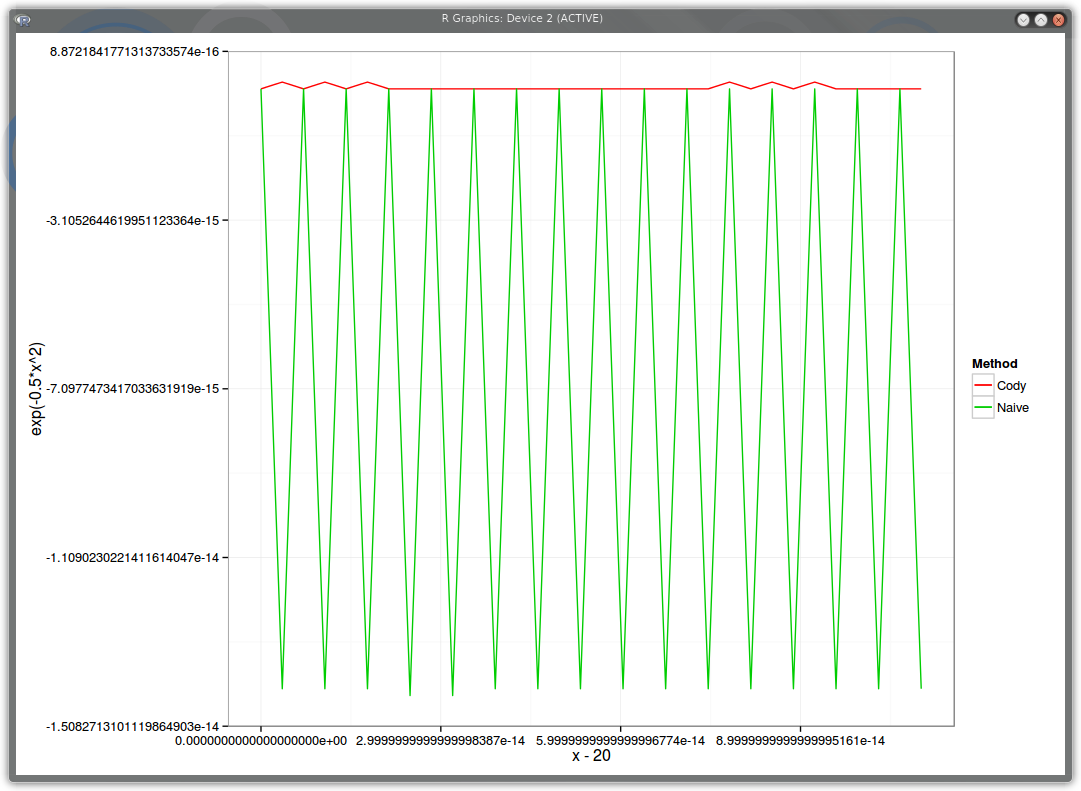
Let’s make x move by machine epsilon and see how the result varies using the naive implementation exp(-0.5*x*x) and using the refined Cody way. We take x=20, and add machine epsilon a number of times (frac).
PDF
The staircase happens because if we add machine epsilon to 20, this results in the same 20, until we add it enough to describe the next number in double precision accuracy. But what’s interesting is that Cody staircase is regular, the stairs have similar height while the Naive implementation has stairs of uneven height.
To calculate the actual error, we must rely on higher precision arithmetic.
Update March 22, 2013
I thus looked for a higher precision exp implementation, that can go beyond double precision. I initially found an online calculator (not so great to do tests on), and after more search, I found one very simple way: mpmath python library. I did some initial tests with the calculator and thought Cody was in reality not much better than the Naive implementation. The problem is that my tests were wrong, because the online calculator expects an input in terms of human digits, and I did not always use the correct amount of digits. For example a double of -37.7 is actually -37.
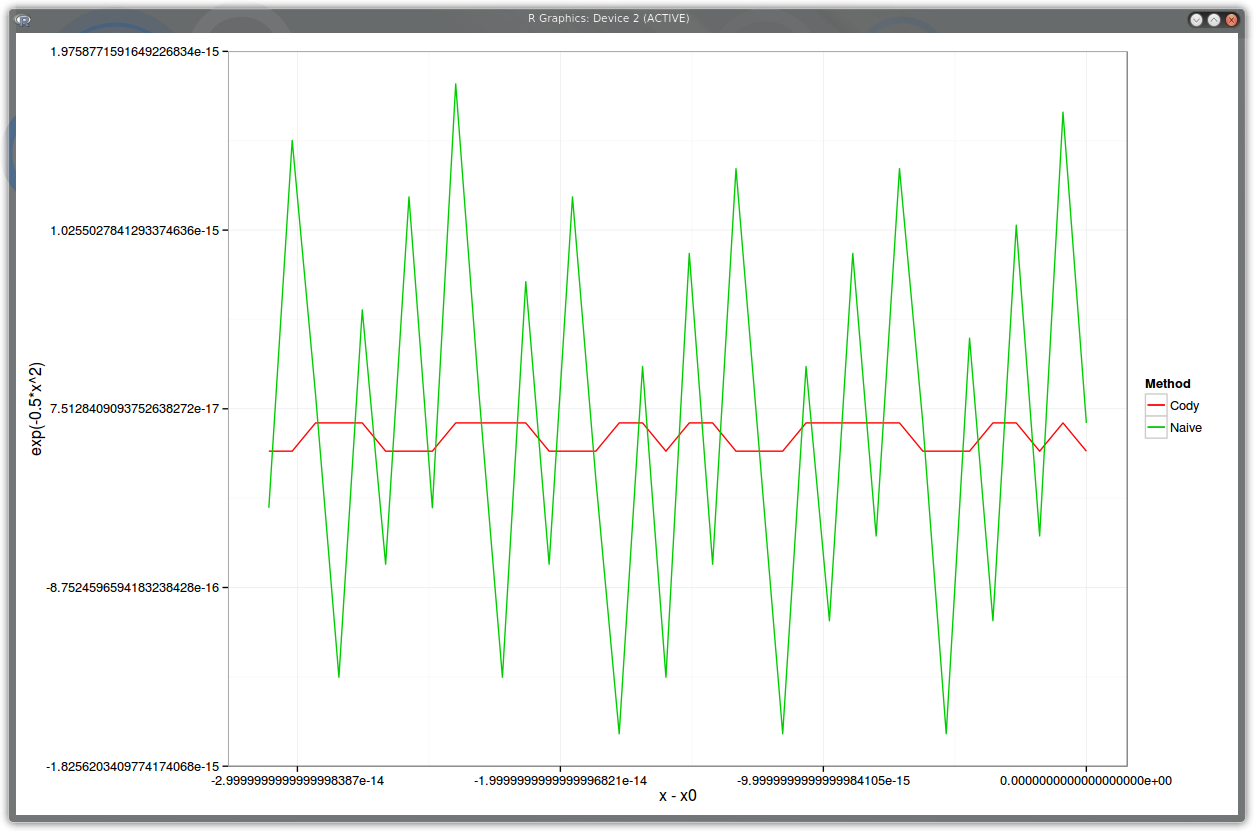
Here is a plot of the relative error of our methods compared to the high accuracy python implementation, but using as input strict double numbers around x=20. The horizontal axis is x-20, the vertical is the relative error.
PDF relative error around x=20
We can see that Cody is really much more accurate (more than 20x). The difference will be lower when x is smaller, but there is still a factor 10 around x=-5.7:
PDF relative error around x=-5.7
Any calculation using a Cody like Gaussian density implementation, will likely not be as careful as this, so one can doubt of the usefulness in practice of such accuracy tricks. The Cody implementation uses 2 exponentials, which can be costly to evaluate, however Gary Kennedy commented out that we can cache the exp xsq because of fint and therefore have accuracy and speed.
Some library computes the Gaussian density function $$e^{-\frac{x^2}{2}}$$ the following way:
xsq =fint(x *1.6) /1.6;
del = (x - xsq) * (x + xsq);
result =exp(-xsq * xsq *0.5) *exp(-del *0.5);
where fint(z) computes the floor of z.
Basically, x*x is rewritten as xsq*xsq+del. I have seen that trick once before, but I just can’t figure out where and why (except that it is probably related to high accuracy issues).
This is very much what's in the Carr-Lee paper "Robust Replication of Volatility Derivatives", but it wasn't so easy to obtain in practice:
The formulas as written in the paper are not usable as is: they can be simplified (not too difficult, but intimidating at first)
The numerical integration is not trivial: a simple Gauss-Laguerre is not precise enough (maybe if I had an implementation with more points), a Gauss-Kronrod is not either (maybe if we split it in different regions). Funnily a simple adaptive Simpson works ok (but my boundaries are very basic: 1e-5 to 1e5).
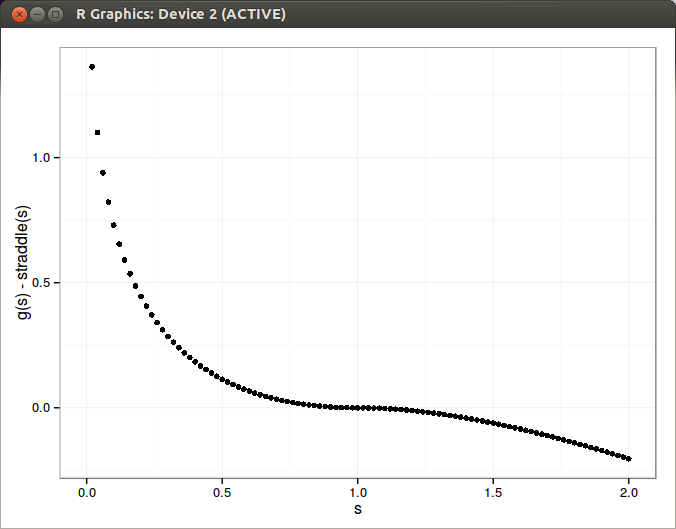
A Volatility swap is a forward contract on future realized volatility. The pricing of such a contract used to be particularly challenging, often either using an unprecise popular expansion in the variance, or a model specific way (like Heston or local volatility with Jumps). Carr and Lee have recently proposed a way to price those contracts in a model independent way in their paper “robust replication of volatility derivatives”. Here is the difference between the value of a synthetic volatility swap payoff at maturity (a newly issued one, with no accumulated variance) and a straddle.
Those are very close payoffs!
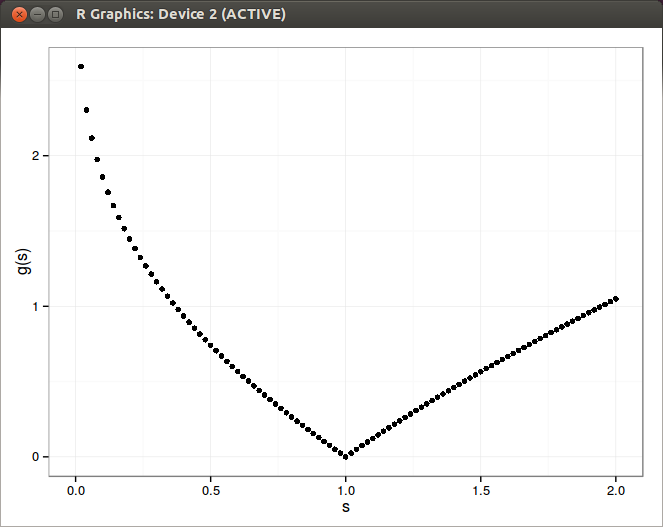
I wonder how good is the discrete Derman approach compared to a standard integration for such a payoff as well as how important is the extrapolation of the implied volatility surface.The real payoff (very easy to obtain through Carr-Lee Bessel formula):