I was used to Scilab for small experiments involving linear algebra. I also like some of Scilab choices in algorithms: for example it provides PCHIM monotonic spline algorithm, and uses Cody for the cumulative normal distribution.
Matlab like software is particularly well suited to express PDE solvers in a relatively concise manner. To illustrate some of my experiments, I started to write a Scilab script for the Arbitrage Free SABR problem. It worked nicely and is a bit nicer to read than my equivalent Scala program. But I was a bit surprised by the low performance.
Then I heard about Octave, which is even closer to Matlab syntax than Scilab and started wondering if it was better or faster. Here are my results for 1000 points and 10 time-steps:
Scilab 4.3s
Octave 4.1s
I then added the keyword sparse when I build the tridiagonal matrix and end up with:
Scilab 0.04s
Octave 0.02s
Scala 0.034s (first run)
Scala 0.004s (once Hotpot has kicked in)
So Octave looks a bit better than Scilab in terms of performance. However I could not figure out from the documentation what algorithm was used for the cumulative normal distribution and if there was a monotonic spline interpolation in Octave.
In general I find it impressive that Octave is faster than the first run of Scala or Java, and impressive as well that the Hotspot makes gain of x10.
Update 2024 I now use Julia, which offers good performance with concise code.
Joda has the concept of LocalDate LocalDateTime and DateTime. The LocalDate is just a simple date, while DateTime is a date and a time zone.
Where I work we have a similar distinction, although not the same: a simple “absolute” date object without time vs a relative date (a timestamp) like the JDK Date.
The standard JDK Date class is a date without a time zone, but Sun deprecated in JDK 1.1 all methods allowing to use it like a LocalDate, forcing to use it through a Calendar (i.e. like a DateTime), that is, with a TimeZone.
I have found one explanation for a potential use case of LocalDateTime vs DateTime: when you take an appointment to the doctor for July 22nd at 10am, the future date is a fixed event. Some people say you just don’t care about the TimeZone in this case, and therefore use LocalDateTime. I think it is a bit more subtle than that. One could think of using fixed arbitrary TimeZone, it could just easily be set to UTC or to the default Java time zone or even the correct one. While it’s not typically what the user want to worry about, it could be a default setting (like in Google Calendar or in your OS). And that is exactly what the LocalDateTime does internally, it uses a fixed, non modifiable TimeZone.
If the future event is in a few years and you want to store it in a database, it can become more problematic because daylight saving might not be well determined yet. The number stored today might not mean the same thing in a few years. I am not sure if it can be a real issue, but I am not the only one to worry about that. As the LocalDateTime internally relies on UTC, it is not affected by this.
There is another more technical use case for LocalDateTime, if you have a list of dates in a contract, they are all according to the contract TimeZone, you then probably don’t want to specify the TimeZone for each date. The question is then more is the DateTime concept a good idea?
This is a kind of following to the CUDA performance myth. There is a recent news on the java concurrent mailing list about SplittableRandom class proposed for JDK8. It is a new parallel random number generator a priori usable for Monte-Carlo simulations.
It seems to rely on some very recent algorithm. There are some a bit older ones: the ancestor, L’Ecuyer MRG32k3a that can be parallelized through relatively costless skipTo methods, a Mersenne Twister variant MTGP, and even the less rigourous XorWow popularized by NVidia CUDA.
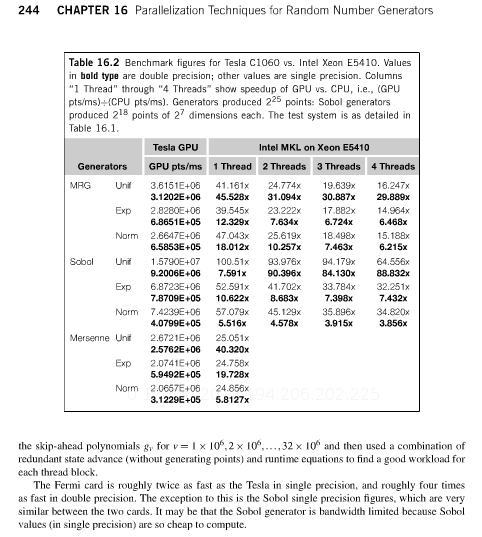
The book GPU Computing Gems provides some interesting stats as to GPU vs CPU performance for various generators (L’Ecuyer, Sobol, and Mersenne Twister)
Excerpt from the book
A Quad core Xeon is only 4 times slower to generate normally distributed random numbers with Sobol. Fermi cards are faster now, but probably so are newer Xeons. I would have expected this kind of task to be the typical not too complex parallelizable task doable by a GPU, and yet the improvements are not very good (except if you look at raw random numbers, which is almost useless in applications). It confirms the idea that many real world algorithms are not so much faster with GPUs than with CPUs. I suppose what’s interesting is that the GPU abstractions forces you to be relatively efficient, while the CPU flexibility might make you lazy.
The other day I installed the latest Ubuntu 13.04 under a VirtualBox virtual machine using Windows as host. To my surprise, unity failed to launch properly on the virtual machine reboot, with compiz complaining, something I have sometimes seen on my work laptop. It’s more surprising in a VM since it is in a way much more standard (no strange graphic card, no strange driver, the same stuff for every VirtualBox user (maybe I’m wrong there?)). I therefore installed KDE as a way to bypass this issue. Not only it worked, but the UI was much faster: there was some very noticeable lag in Unity, slow fade in fade out effects, when it worked before the reboot.
I am no hater of Unity, it looks well polished, nice to the eye and I use it on a home computer. I find KDE looks a tiny bit less nice, although I prefer the standard scrollbars of KDE. I wonder if others have the same dreadful experience with Unity under VirtualBox.
As Bessel (sometimes called Hermite) spline interpolation is only C1, like the Harmonic spline from Fritsch-Butland, the forward presents small kinks compared to a standard cubic spline. Hyman filtering also creates a kink where it fixes the monotonicity. Those are especially visible with a log scale in time. Here is how it looks on the Hagan-West difficult curve.
I discovered that suddenly emails sent to me bounced back yesterday. I logged in my godaddy account and to my surprise saw that I did not own any domain name anymore. I looked at my emails to see if I had received a warning as is usually the case when your domain is about to expire. There was none recent, the most recent was from may 2011, the last time I had renewed my domain.
I then tried to buy again the same domain name only to discover it was already taken! The whois record indicated a day old registration through godaddy itself.
It’s no coincidence that godaddy sells for 3 times the price the possibility to try to take over a domain as soon as it will expire. I find particularly dishonest that in this case they fail to warn their own customers that their domain is about to expire. As a result of this policy, someone else will take over the domain through them for a much higher price. A conflict of interest.
From now on I will not register a domain through a registrar that offers the service to snatch up a domain.
It’s been a while since I do a pet project in Scala, and today, after many trials before, I decided to give another go at Jetbrain Idea for Scala development, as Eclipse with the Scala plugin tended to crash a little bit too often for my taste (resulting sometimes in loss of a few lines of code). I could have just probably updated eclipse and the scala plugin, mine were not very old, but not the latest.
But it was just an opportunity to try Idea. I somehow always failed before to setup properly the scala support in Idea while it seemed to just work in Eclipse. I had difficulties making it find my scala compiler. After some google searches, I found that SBT, the scala build tool could create automatically a scala project for Idea (a hint to make it work with a project under Scala 2.10 is to put the plugins.sbt file in ~/.sbt/plugins).
It was reasonably easy to create a simple build.sbt file for my project. I added some dependencies (it handles them like Ivy, from Maven repositories), and was pleased to find you could also just put your jars in lib directory if you did not want/could not find some maven repository.
The tool is quick to launch, does not get in the way. So far the experience has been much much nicer than Gradle that we use now at work, which I find painfully slow to start, check dependencies, and extremely complicated to customize to your needs. It’s also nicer than Maven, which I always found painful as soon as one wanted a small specific behaviour.
The theta finite difference scheme is a common generalization of Crank-Nicolson. In finance, the book from Wilmott, a paper from A. Sepp, one from Andersen-Ratcliffe present it. Most of the time, it’s just a convenient way to handle implicit \(\theta=1\), explicit \(\theta=0\) and Crank-Nicolson \(\theta=0.5\) with the same algorithm.
Wilmott makes an interesting remark: one can choose a theta that will cancel out higher order terms in the local truncation error and therefore should lead to increased accuracy. $$\theta = \frac{1}{2}- \frac{(\Delta x)^2}{12 b \Delta t} $$
where \(b\) is the diffusion coefficient.
This leads to \(\theta < \frac{1}{2}\), which means the scheme is not unconditionally stable anymore but needs to obey (see Morton & Mayers p 30):
$$b \frac{\Delta t}{(\Delta x)^2} \leq \frac{5}{6}$$
and to ensure that \(\theta \geq 0 \):
$$b \frac{\Delta t}{(\Delta x)^2} \geq \frac{1}{6}$$
Crank-Nicolson has a similar requirement to ensure the absence of oscillations given non smooth initial value, but because it is unconditionality stable, the condition is actually much weaker if \(b\) depends on \(x\). Crank-Nicolson will be oscillation free if \(b(x_{j0}) \frac{\Delta t}{(\Delta x)^2} < 1\) where \(j0\) is the index of the discontinuity, while the theta scheme needs to be stable, that is \(\max(b) \frac{\Delta t}{(\Delta x)^2} \leq \frac{5}{6}\)
This is a much stricter condition if \(b\) varies a lot, as it is the case for the arbitrage free SABR PDE where \(\max(b) > 200 b_{j0}\)
The advantages of such a scheme are then not clear compared to a simpler explicit scheme (eventually predictor corrector), that will have a similar constraint on the ratio \( \frac{\Delta t}{(\Delta x)^2} \).
Today, a friend asked me if Scala could pass primitives (such as Double) by reference. It can be useful sometimes instead of creating a full blown object. In Java there is commons lang MutableDouble. It could be interesting if there was some optimized way to do that.
One answer could be: it’s not functional programming oriented and therefore not too surprising this is not encouraged in Scala.
Then he wondered if we could use it for C#.
I know this used to be possible in Scala 1.0, I believe it’s not anymore since 2.x. This was a cool feature, especially if they had managed to develop strong libraries around it. I think it was abandoned to focus on other things, because of lack of resources, but it’s sad.
Later today, I tried to use the nice syntax to return multiple values from a method:
var (a,b) = mymethod(1)
I noticed you then could not do:
(a,b) = mymethod(2)
So declaring a var seems pointless in this case.
One way to achieve this is to:
var tuple = mymethod(1)var a = tuple._1var b = tuple._2
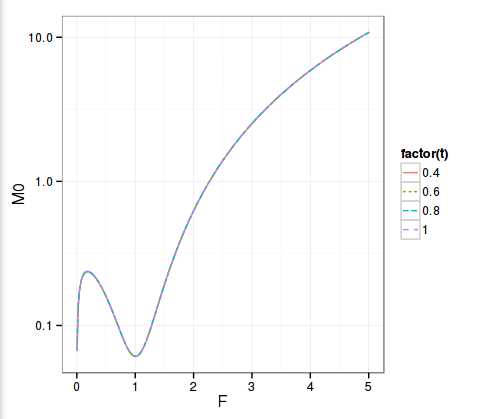
On my test of yield curve interpolations, focusing on parallel delta versus sequential delta, Akima is the worst of the lot. I am not sure why this interpolation is still popular when most alternatives seem much better. Hyman presented some of the issues with Akima in his paper in 1983.
In the following graph, a higher value is a higher parallel-vs-sequential difference.
That plus the Hagan-West example of a tricky curve looks a bit convoluted with it (although it does not have any negative forward).
I have used Quantlib implementation, those results make me wonder if there is not something wrong with the boundaries.