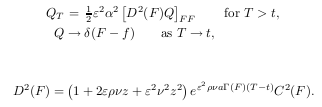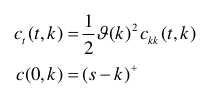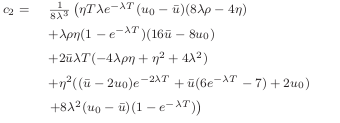Today, after wondering why my desktop computer became so unstable (frequent crashes under Fedora), I found out that the micro usb port of my cell phone has some kind of short circuit. My phone behaves strangely in 2014, it lasted nearly 1 week on battery (I lost it for half of the week), and seems to shutdown for no particular reason once in a while.
On the positive side, I also discovered, after owning my monitor for around 5 years, that it has SD card slots on the side, as well as USB ports. I always used the USB ports of my desktop and never really looked at the side of my monitor…
I also managed to seriously boost the speed of my home network with a cheap TP-Link wifi router. The one included in the ISP box-modem only supported 802.11g and had really crap coverage, so crap that it was seriously limiting the internet traffic. In the end it was just a matter of disabling wifi and DHCP on the box, adding the new router in the DMZ, and adding a static WAN IP for the box in the router configuration. I did not realize how much of a difference this could make, even on simple websites. I was also surprised that, for some strange reason, routers are cheaper than access points these days.
The Fortran minpack library has a good Levenberg-Marquardt minimizer, so good, that it has been ported to many programming languages. Unfortunately it does not support contraints, even simple bounds.
One way to achieve this is to transform the domain via a bijective function. For example, \(a+\frac{b-a}{1+e^{-\alpha t}}\) will transform \(]-\infty, +\infty[\) to ]a,b[. Then how should one choose \(\alpha\)?
A large \(\alpha\) will make tiny changes in \(t\) appear large. A simple rule is to ensure that \(t\) does not create large changes in the original range ]a,b[, for example we can make \(\alpha t \leq 1\), that is \( \alpha t= \frac{t-a}{b-a} \).
In practice, for example in the calibration of the Double-Heston model on real data, a naive \( \alpha=1 \) will converge to a RMSE of 0.79%, while our choice will converge to a RMSE of 0.50%. Both will however converge to the same solution if the initial guess is close enough to the real solution. Without any transform, the RMSE is also 0.50%. The difference in error might not seem large but this results in vastly different calibrated parameters. Introducing the transform can significantly change the calibration result, if not done carefully.
Another simpler way would be to just impose a cap/floor on the inputs, thus ensuring that nothing is evaluated where it does not make sense. In practice, it however will not always converge as well as the unconstrained problem: the gradient is not defined at the boundary. On the same data, the Schobel-Zhu, unconstrained converges with RMSE 1.08% while the transform converges to 1.22% and the cap/floor to 1.26%. The Schobel-Zhu example is more surprising since the initial guess, as well as the results are not so far:
Initial volatility (v0)
18.1961174789
Long run volatility (theta)
1
Speed of mean reversion (kappa)
101.2291161766
Vol of vol (sigma)
35.2221829015
Correlation (rho)
-73.7995231799
ERROR MEASURE
1.0614889526
Initial volatility (v0)
17.1295934569
Long run volatility (theta)
1
Speed of mean reversion (kappa)
67.9818356373
Vol of vol (sigma)
30.8491256097
Correlation (rho)
-74.614636128
ERROR MEASURE
1.2256421987
The initial guess is kappa=61% theta=11% sigma=26% v0=18% rho=-70%. Only the kappa is different in the two results, and the range on the kappa is (0,2000) (it is expressed in %), much larger than the result. In reality, theta is the issue (in (0,1000)). Forbidding a negative theta has an impact on how kappa is picked. The only way to be closer
Finally, a third way is to rely on a simple penalty: returning an arbitrary large number away from the boundary. In our examples this was no better than the transform or the cap/floor.
Trying out the various ways, it seemed that allowing meaningless parameters, as long as they work mathematically produced the best results with Levenberg-Marquardt, particularly, allowing for a negative theta in Schobel-Zhu made a difference.
One way is due to Andreasen and Huge, where they find an equivalent local volatility expansion, and then use a one-step finite difference technique to price.
The other way is due to Hagan himself, where he numerically solves an approximate PDE in the probability density, and then price with options by integrating on this density.
It turns out that the two ways are much closer than I first thought. Hagan PDE in the probability density is actually just the Fokker-Planck (forward) equation.
The \(\alpha D(F)\) is just the equivalent local volatility. Andreasen and Huge use nearly the same local volatility formula but without the exponential part (that is often negligible except for long maturities), directly in Dupire forward PDE:
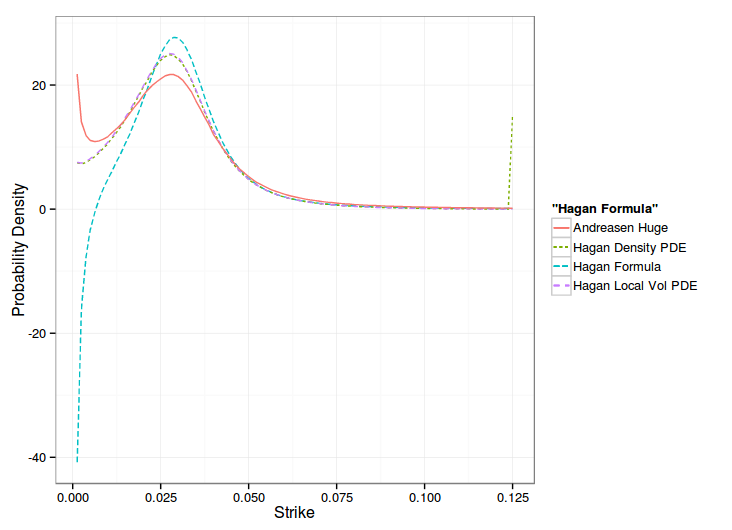
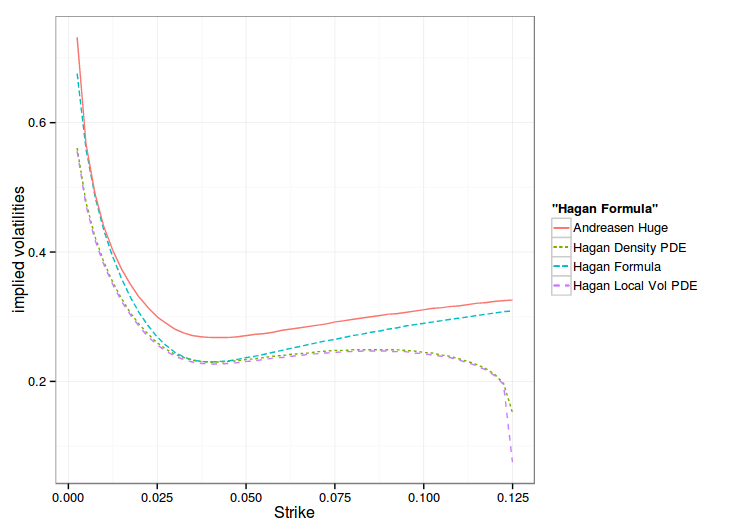
A common derivation (for example in Gatheral book of the Dupire forward PDE is to actually use the Fokker-Planck equation in the probability density integral formula. Out of curiosity, I tried to price direcly with Dupire forward PDE and the Hagan local volatility formula, using just linear boundary conditions. Here are the results on Hagan own example:
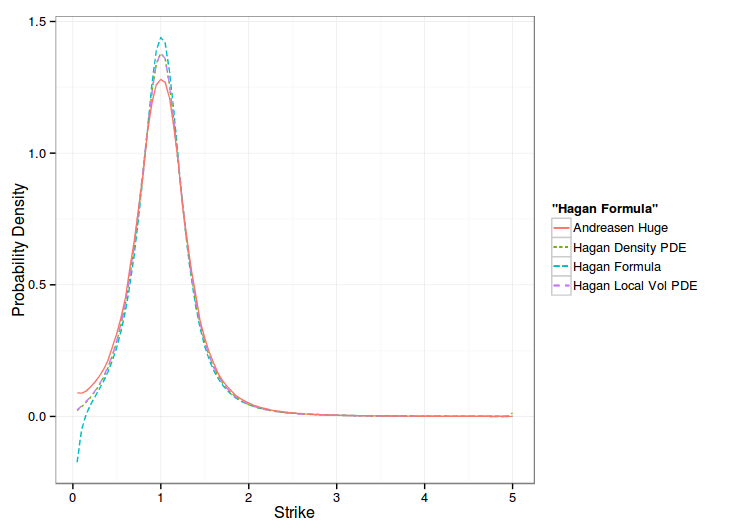
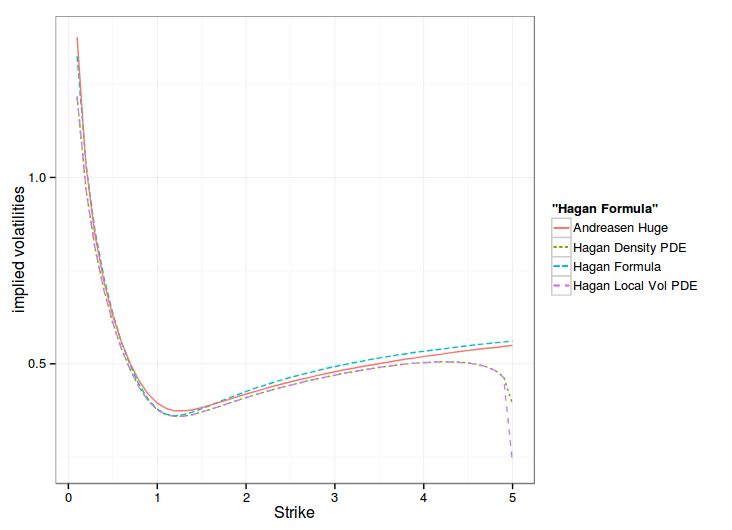
The Local Vol direct approach overlaps the Density approach nearly exactly, except at the high strike boundary, when it comes to probability density measure or to implied volatility smile. On Andreasen and Huge data, it gives the following:
One can see that the one step method approximation gives the overall same shape of smile, but shifted, while the PDE, in local vol or density matches the Hagan formula at the money.
Hagan managed to derive a slightly more precise local volatility by going through the probability density route, and his paper formalizes his model in a clearer way: the probability density accumulates at the boundaries. But in practice, this formalism does not seem to matter. The forward Dupire way is more direct and slightly faster. This later way also allows to use alternative boundaries, like Andreasen-Huge did.
Prices of a Future contract and a Forward contract are the same under the Black-Scholes assumptions (deterministic rates) but the price of options on Futures or options on Forwards might still differ. I did not find this obvious at first.
For example, when the underlying contract expiration date (Futures, Forward) is different from the option expiration date. For a Future Option, the Black-76 formula can be used, the discounting is done from the option expiry date, because one receives the cash on expiration due to the margin account. For a Forward Option, the discounting need to be done from the Forward contract expiry date.
European options prices will be the same when the underlying contract expiration date is the same as the option expiration date. However, this is not true for American options: the immediate exercise will need to be discounted to the Forward expiration date for a Forward underlying, not for a Future.
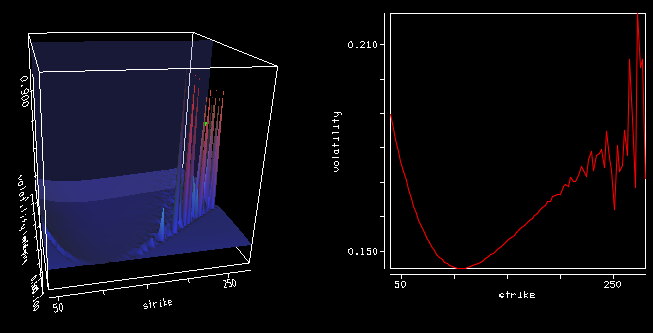
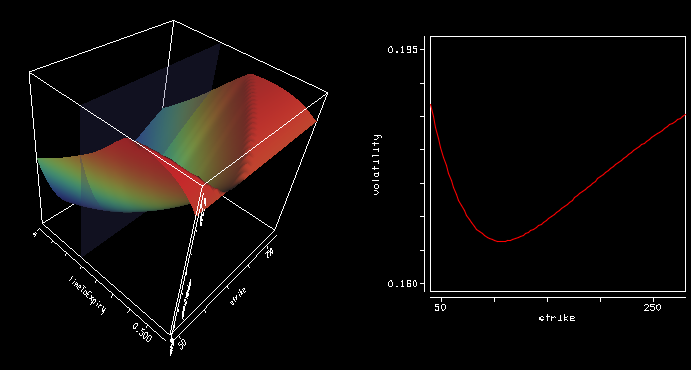
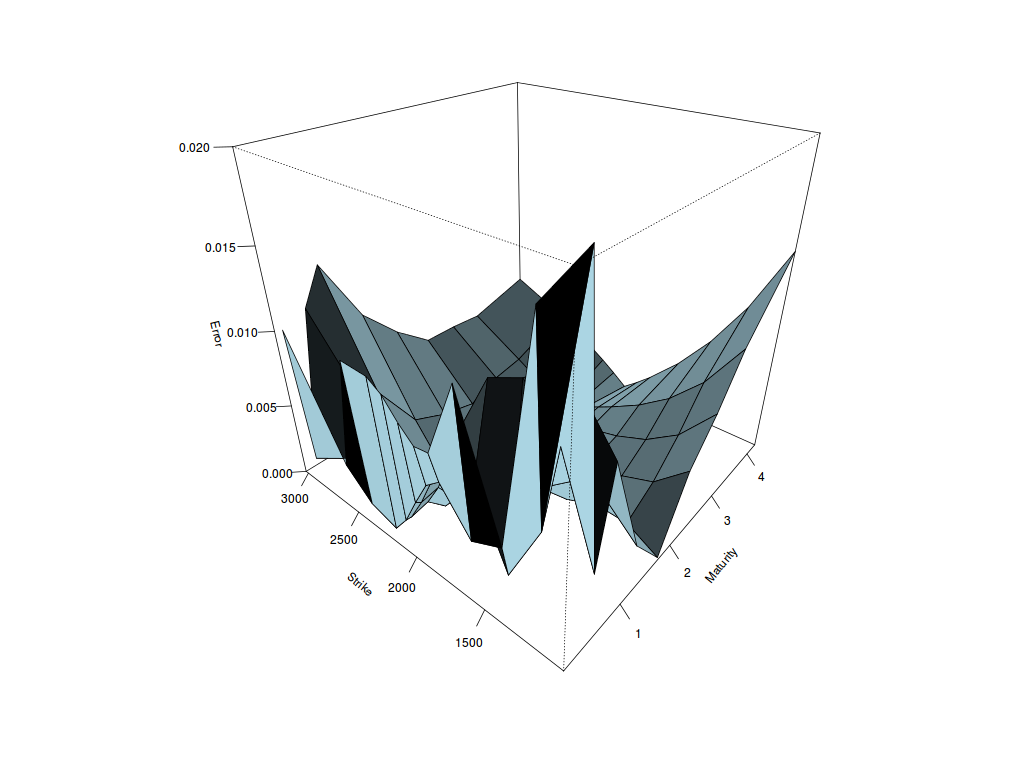
Using precise vanilla option pricing engine for Heston or Schobel-Zhu, like the Cos method with enough points and a large enough truncation can still lead to spikes in the Dupire local volatility (using the variance based formula).
Local volatility
Implied volatility
The large spikes in the local volatility 3d surface are due to constant extrapolation, but there are spikes even way before the extrapolation takes place at longer maturities. Even if the Cos method is precise, it seems to be not enough, especially for large strikes so that the second derivative over the strike combined with the first derivative over time can strongly oscillate.
After wondering about possible solutions (using a spline on the implied volatilities), the root of the error was much simpler: I used a too small difference to compute the numerical derivatives (1E-6). Moving to 1E-4 was enough to restore a smooth local volatility surface.
I always imagined local stochastic volatility to be complicated, and thought it would be very slow to calibrate.
After reading a bit about it, I noticed that the calibration phase could just consist in calibrating independently a Dupire local volatility model and a stochastic volatility model the usual way.
One can then choose to compute on the fly the local volatility component (not equal the Dupire one, but including the stochastic adjustment) in the Monte-Carlo simulation to price a product.
There are two relatively simple algorithms that are remarkably similar, one by Guyon and Henry-Labordère in "The Smile Calibration Problem Solved":
In the particle method, the delta function is a regularizing kernel approximating the Dirac function. If we use the notation of the second paper, we have a = psi.
The methods are extremely similar, the evaluation of the expectation is slightly different, but even that is not very different. The disadvantage is that all paths are needed at each time step. As a payoff is evaluated over one full path, this is quite memory intensive.
I did some experiments fitting Heston, Schobel-Zhu, Bates and Double-Heston to a real world equity index implied volatility surface. I used a global optimizer (differential evolution).
To my surprise, the Heston fit is quite good: the implied volatility error is less than 0.42% on average. Schobel-Zhu fit is also good (0.47% RMSE), but a bit worse than Heston. Bates improves quite a bit on Heston although it has 3 more parameters, we can see the fit is better for short maturities (0.33% RMSE). Double-Heston has the best fit overall but it is not that much better than simple Heston while it has twice the number of parameters, that is 10 (0.24 RMSE). Going beyond, for example Triple-Heston, does not improve anything, and the optimization becomes very challenging. With Double-Heston, I already noticed that kappa is very low (and theta high) for one of the processes, and kappa is very high (and theta low) for the other process: so much that I had to add a penalty to enforce constraints in my local optimizer. The best fit is at the boundary for kappa and theta. So double Heston already feels over-parameterized.
Heston volatility error
Schobel-Zhu volatility error
Bates volatility error
Double Heston volatility error
Another advantage of Heston is that one can find tricks to find a good initial guess for a local optimizer.
Update October 7: My initial fit relied only on differential evolution and was not the most stable as a result. Adding Levenberg-Marquardt at the end stabilizes the fit, and improves the fit a lot, especially for Bates and Double Heston. I updated the graphs and conclusions accordingly. Bates fit is not so bad at all.
I recently stumbled upon an error in the various papers related to the Heston Cos method regarding the second cumulant. It is used to define the boundaries of the Cos method. Letting phi be Heston characteristic function, the cumulant generating function is:
$$g(u) = \log(\phi(-iu))$$
And the second cumulant is defined a:
$$c_2 = g’’(0)$$
Compared to a numerical implementation, the c_2 from the paper is really off in many use cases.
This is where Maxima comes useful, even if I had to simplify the results by hand. It leads to the following analytical formula:
$$c_2 = \frac{v_0}{4\kappa^3}{ 4 \kappa^2 \left(1+(\rho\sigma t -1)e^{-\kappa t}\right) + \kappa \left(4\rho\sigma(e^{-\kappa t}-1)-2\sigma^2 t e^{-\kappa t}\right)+\sigma^2(1-e^{-2\kappa t}) }\\+ \frac{\theta}{8\kappa^3} { 8 \kappa^3 t - 8 \kappa^2 \left(1+ \rho\sigma t + (\rho\sigma t-1)e^{-\kappa t}\right) + 2\kappa \left( (1+2e^{-\kappa t})\sigma^2 t+8(1-e^{-\kappa t})\rho\sigma \right) \\+ \sigma^2(e^{-2\kappa t} + 4e^{-\kappa t}-5) }$$
In contrast, the paper formula was:
I saw this while trying to calibrate Heston on a bumped surface: the results were very different with the Cos method than with the other methods. The short maturities were mispriced, except if one pushed the truncation level L to 24 (instead of the usual 12), and as a result one would also need to significantly raise the number of points used in the Cos method. With the corrected formula, it works well with L=12.
Here is an example of failure on a call option of strike, spot 1.0 and maturity 1.0 and not-so-realistic Heston parameters $$\kappa=0.1, \theta=1.12, \sigma=1.0, v_0=0.2, \rho=-0377836$$ using 200 points:
A few years ago, I found an interesting open source symbolic calculus software called Xcas. It can however be quickly limited, for example, it does not seem to work well to compute Taylor expansions with several embedded functions. Google pointed me to another popular open source package, Maxima. It looks a bit rudimentary (command like interface), but formulas can actually be very easily exported to latex with the tex command. Here is a simple example:
$$-{{\left(e^{t,\lambda}-1\right),\eta^2,x}\over{2,e^{t,\lambda},\lambda}}+{{\left(\left(4,e^{t,\lambda},t,\eta^3,\rho+\left(4,\left(e^{t,\lambda}\right)^2-4,e^{t,\lambda}\right),\eta^2\right),\lambda^2+\left(\left(-4,\left(e^{t,\lambda}\right)^2+4,e^{t,\lambda}\right),\eta^3,\rho-2,e^{t,\lambda},t,\eta^4\right),\lambda+\left(\left(e^{t,\lambda}\right)^2-1\right),\eta^4\right),x^2}\over{8,\left(e^{t,\lambda}\right)^2,\lambda^3}}+{{\left(\left(8,\left(e^{t,\lambda}\right)^2,t^2,\eta^4,\rho^2-16,\left(e^{t,\lambda}\right)^2,t,\eta^3,\rho\right),\lambda^4+\left(16,\left(e^{t,\lambda}\right)^2,t,\eta^4,\rho^2+\left(-8,\left(e^{t,\lambda}\right)^2,t^2,\eta^5+\left(16,\left(e^{t,\lambda}\right)^3-16,\left(e^{t,\lambda}\right)^2\right),\eta^3\right),\rho+16,\left(e^{t,\lambda}\right)^2,t,\eta^4\right),\lambda^3+\left(\left(-16,\left(e^{t,\lambda}\right)^3+16,\left(e^{t,\lambda}\right)^2\right),\eta^4,\rho^2+\left(-16,\left(e^{t,\lambda}\right)^2-8,e^{t,\lambda}\right),t,\eta^5,\rho+2,\left(e^{t,\lambda}\right)^2,t^2,\eta^6+\left(-8,\left(e^{t,\lambda}\right)^3+8,e^{t,\lambda}\right),\eta^4\right),\lambda^2+\left(\left(12,\left(e^{t,\lambda}\right)^3-12,e^{t,\lambda}\right),\eta^5,\rho+\left(2,\left(e^{t,\lambda}\right)^2+4,e^{t,\lambda}\right),t,\eta^6\right),\lambda+\left(-2,\left(e^{t,\lambda}\right)^3-\left(e^{t,\lambda}\right)^2+2,e^{t,\lambda}+1\right),\eta^6\right),x^3}\over{32,\left(e^{t,\lambda}\right)^3,\lambda^5}}+\cdots $$
Regarding Taylor expansion, there seems to be quite a few options possible, but I found that the default expansion was already relatively easy to read. XCas produced less readable expansions, or just failed.
I tried today the Scala courses on coursera by the Scala creator, Martin Odersky. I was quite impressed by the quality: I somehow believed Scala to be only a better Java, now I think otherwise. Throughout the course, even though it all sounds very basic, you understand the key concepts of Scala and why functional programming + OO concepts are a natural idea. What’s nice about Scala is that it avoids the functional vs OO or even the functional vs procedural debate by allowing both, because both can be important, at different scales. Small details can be (and probably should be) procedural for efficiency, because a processor is a processor, but higher level should probably be more functional (immutable) to be clearer, easier to evolve and more easily parallelized.
I recently saw a very good example at work recently of how mutability could be very problematic, with no gain in this case because it was high level (and likely just the result of being too used to OO concepts).
I believe it will make my code more functional programming oriented in the future, especially at the high level.