The theta finite difference scheme is a common generalization of Crank-Nicolson. In finance, the book from Wilmott, a paper from A. Sepp, one from Andersen-Ratcliffe present it. Most of the time, it’s just a convenient way to handle implicit \(\theta=1\), explicit \(\theta=0\) and Crank-Nicolson \(\theta=0.5\) with the same algorithm.
Wilmott makes an interesting remark: one can choose a theta that will cancel out higher order terms in the local truncation error and therefore should lead to increased accuracy. $$\theta = \frac{1}{2}- \frac{(\Delta x)^2}{12 b \Delta t} $$
where \(b\) is the diffusion coefficient.
This leads to \(\theta < \frac{1}{2}\), which means the scheme is not unconditionally stable anymore but needs to obey (see Morton & Mayers p 30):
$$b \frac{\Delta t}{(\Delta x)^2} \leq \frac{5}{6}$$
and to ensure that \(\theta \geq 0 \):
$$b \frac{\Delta t}{(\Delta x)^2} \geq \frac{1}{6}$$
Crank-Nicolson has a similar requirement to ensure the absence of oscillations given non smooth initial value, but because it is unconditionality stable, the condition is actually much weaker if \(b\) depends on \(x\). Crank-Nicolson will be oscillation free if \(b(x_{j0}) \frac{\Delta t}{(\Delta x)^2} < 1\) where \(j0\) is the index of the discontinuity, while the theta scheme needs to be stable, that is \(\max(b) \frac{\Delta t}{(\Delta x)^2} \leq \frac{5}{6}\)
This is a much stricter condition if \(b\) varies a lot, as it is the case for the arbitrage free SABR PDE where \(\max(b) > 200 b_{j0}\)
The advantages of such a scheme are then not clear compared to a simpler explicit scheme (eventually predictor corrector), that will have a similar constraint on the ratio \( \frac{\Delta t}{(\Delta x)^2} \).
Today, a friend asked me if Scala could pass primitives (such as Double) by reference. It can be useful sometimes instead of creating a full blown object. In Java there is commons lang MutableDouble. It could be interesting if there was some optimized way to do that.
One answer could be: it’s not functional programming oriented and therefore not too surprising this is not encouraged in Scala.
Then he wondered if we could use it for C#.
I know this used to be possible in Scala 1.0, I believe it’s not anymore since 2.x. This was a cool feature, especially if they had managed to develop strong libraries around it. I think it was abandoned to focus on other things, because of lack of resources, but it’s sad.
Later today, I tried to use the nice syntax to return multiple values from a method:
var (a,b) = mymethod(1)
I noticed you then could not do:
(a,b) = mymethod(2)
So declaring a var seems pointless in this case.
One way to achieve this is to:
var tuple = mymethod(1)var a = tuple._1var b = tuple._2
On my test of yield curve interpolations, focusing on parallel delta versus sequential delta, Akima is the worst of the lot. I am not sure why this interpolation is still popular when most alternatives seem much better. Hyman presented some of the issues with Akima in his paper in 1983.
In the following graph, a higher value is a higher parallel-vs-sequential difference.
That plus the Hagan-West example of a tricky curve looks a bit convoluted with it (although it does not have any negative forward).
I have used Quantlib implementation, those results make me wonder if there is not something wrong with the boundaries.
I had explored the issue of pricing a barrier using finite difference discretization of the Black-Scholes PDE a few years ago. Briefly, for explicit schemes, one just need to place the barrier on the grid and not worry about much else, but for implicit schemes, either the barrier should be placed on the grid and the grid truncated at the barrier, or a fictitious point should be introduced to force the correct price at the barrier level (0, typically).
The fictitious point approach is interesting for the case of varying rebates, or when the barrier moves around. I first saw this idea in the book "Paul Wilmott on Quantitative Finance".
Recently, I noticed that Hagan made use of the ficitious point approach in its "Arbitrage free SABR" paper, specifically he places the barrier in the middle of 2 grid points. There is very little difference between truncating the grid and the fictitious point for a constant barrier.
In this specific case there is a difference because there are 2 additional ODE solved on the same grid, at the boundaries. I was especially curious if one could place the barrier exactly at 0 with the fictitious point, because then one would potentially need to evaluate coefficients for negative values. It turns out you can, as values at the fictitious point are actually not used: the mirror point inside is used because of the mirror boundary conditions.
So the only difference is the evaluation of the first derivative at the barrier (used only for the ODE): the fictitious point uses the value at barrier+h/2 where h is the space between two points at the same timestep, while the truncated barrier uses a value at barrier+h (which can be seen as standard forward/backward first order finite difference discretization at the boundaries). For this specific case, the fictitious point will be a little bit more precise for the ODE.
At a presentation of the Thalesians, Hagan has presented a new PDE based approach to compute arbitrage free prices under SABR. This is similar in spirit as Andreasen-Huge, but the PDE is directly on the density, not on the prices, and there is no one-step procedure: it's just like a regular PDE with proper boundary conditions.
I was wondering how it compared to Andreasen Huge results.
My first implementation was quite slow. I postulated it was likely the Math.pow function calls. It turns out they could be reduced a great deal. As a result, it's now quite fast. But it would still be much slower than Andreasen Huge. Typically, one might use 40 time steps, while Andreasen Huge is 1, so it could be around a 40 to 1 ratio. In practice it's likely to be less than 10x slower, but still.
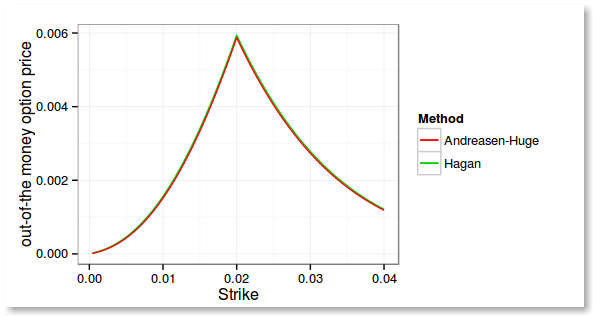
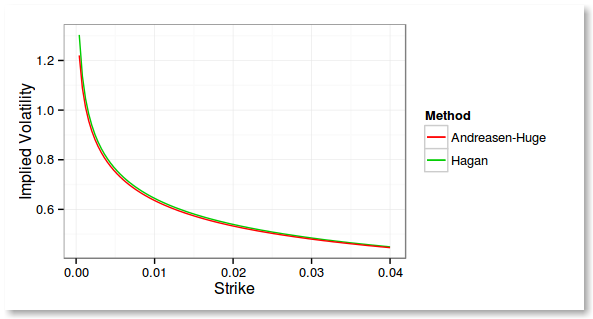
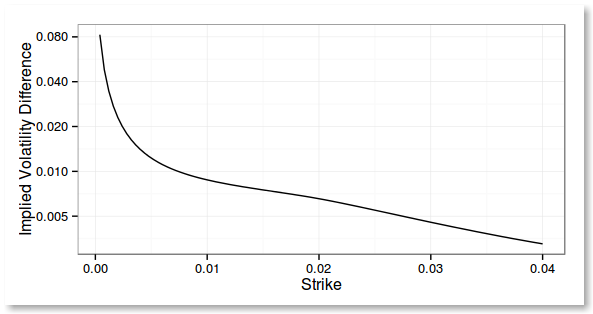
While looking at the implied volatilities I found something intriguing with Andreasen Huge: the implied volatilities from the refined solution using the corrected forward volatility look further away from the Hagan implied volatilitilies than without adjustment, and it's quite pronounced at the money.
Interestingly, the authors don't plot that graph in their paper. They plot a similar graph of their own closed form analytic formula, that is in reality used to compute the forward volatility. I suppose that because they calibrate and price through their method, they don't really care so much that the ATM prices don't match Hagan original formula.
We can see something else on that graph: Hagan PDE boundary is not as nice as Andreasen Huge boundary for high strikes (they use a Hagan like approx at the boundaries, this is why it crosses the Hagan implied volatilities there).
If we use a simple option gamma = 0 boundary in Andreasen Huge, this results in a very similar shape as the Hagan PDE. This is because the option price is effectively 0 at the boundary. Hagan chose a specifically taylored Crank-Nicolson scheme. I was wondering how it fared when I reduced the number of time-steps.
The answer is: not good. This is the typical Crank-Nicolson issue. It could be interesting to adapt the method to use Lawson-Morris-Goubet or TR-BDF2, or a simple Euler Richardson extrapolation. This would allow to use less time steps, as in practice, the accuracy is not so bad with 10 time steps only.
What I like about the Hagan PDE approach is that the implied vols and the probability density converge well to the standard Hagan formula, when there is no negative density problem, for example for shorter maturities. This is better than Andreasen Huge, where there seems to be always 1 vol point difference. However their method is quite slow compared to the original simple analytic formula.
I am on holiday today. Unfortunately I am still thinking about work-related matters, and out of curiosity, wanted to do a little experiment. I know it is not very good to spend free time on work related stuff: there is no reward for it, and there is so much more to life. Hopefully it will be over after this post.
Around 2 years ago, I saw a presentation from Andreasen and Huge about how they were able to price/calibrate SABR by a one-step finite difference technique. At that time, I did not understand much their idea. My mind was too focused on more classical finite differences techniques and not enough on the big picture in their idea. Their idea is quite general and can be applied to much more than SABR.
Recently there has been some talk and development going on where I work about SABR (a popular way to interpolate the option implied volatility surface for interest rate derivatives), especially regarding the implied volatility wings at low strike, and sometimes on how to price in a negative rates environment. There are actually quite a bit of research papers around this. I am not really working on that part so I just mostly listened. Then a former coworker suggested that the Andreasen Huge method was actually what banks seemed to choose in practice. A few weeks later, the Thalesians (a group for people interested in quantitative finance) announced a presentation by Hagan (one of the inventor of SABR) about a technique that sounded very much like Andreasen-Huge to deal with the initial SABR issues in low rates.
As the people working on this did not investigate Andreasen-Huge technique, I somehow felt that I had to and that maybe, this time, I would be able to grasp their idea.
It took me just a few hours to have meaningful results. Here is the price of out of the money vanilla options using alpha = 0.0758194, nu = 0.1, beta = 0.5, rho = -0.1, forward = 0.02, and a maturity of 2 years.
I did not have in my home library a way to find the implied volatility for a given price. I knew of 2 existing methods, Jaeckel "By Implication", and Li rational functions approach. I discovered that Li wrote a new paper on the subject where he uses a SOR method to find the implied volatility and claims it's very accurate, very fast and very robust. Furthermore, the same idea can be applied to normal implied volatility. What attracted me to it is the simplicity of the underlying algorithm. Jaeckel's way is a nice way to do Newton-Raphson, but there seems to be so many things to "prepare" to make it work in most cases, that I felt it would be too much work for my experiment. It took me a few more hours to code Li SOR solvers, but it worked amazingly well for my experiment.
At first I had an error in my boundary condition and had no so good results especially with a long maturity. The traps with Andreasen-Huge technique are very much the same as with classical finite differences: be careful to place the strike on the grid (eventually smooth it), and have good boundaries.
Van Haastrecht, Lord and Pelsser present an effective way to price derivatives by Monte-Carlo under the Schobel-Zhu model (as well as under the Schobel-Zhu-Hull-White model). It's quite similar to Andersen QE scheme for Heston in spirit.
In their paper they evolve the (log) asset process together with the volatility process, using the same discretization times. A while ago, when looking at Joshi and Chan large steps for Heston, I noticed that, inspired by Broadie-Kaya exact Heston scheme, they present the idea to evolve the variance process using small steps and the asset process using large steps (depending on the payoff) using the integrated variance value computed by small steps. The asset steps correspond to payoff evaluation dates At that time I had applied this idea to Andersen QE scheme and it worked reasonably well.
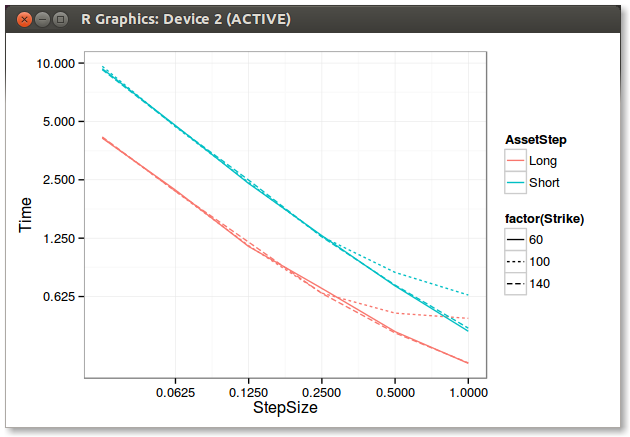
So I tried to apply the same logic to Schobel Zhu, and my first tests show that it works too. Interestingly, the speed gain is about 2x. Here are the results for a vanilla call option of different strikes.
Similar Error between long and short asset steps
Long steps take around 1/2 the time to compute
I would have expected the difference in performance to increase when the step size is decreasing, but it's not the case on my computer.
It's not truly large steps like Joshi and Chan do in their integrated double gamma scheme as the variance is still discretized in relatively small steps in my case, but it seems like a good, relatively simple optimization. A while ago, I did also implement the full Joshi and Chan scheme, but it's really interesting if one is always looking for long steps: it is horribly slow when the step size is small, which might occur for many exotic payoffs, while Andersen QE scheme perform almost as well as log-Euler in terms of computational cost.
Where I work, there used to be quite a bit of a confusion on which rates one should use as input to a Local Volatility Monte-Carlo simulation.
In particular there is a paper in the Journal of Computation Finance by Andersen and Ratcliffe “The Equity Option Volatility Smile: a Finite Difference Approach” which explains one should use specially tailored rates for the finite difference scheme in order to reproduce exact Bond price and exact Forward contract prices
Code has been updated and roll-backed, people have complained around it. But nobody really made the effort to simply write clearly what’s going on, or even write a unit test around it. So it was just FUD, until this paper.
In short, for log-Euler, one can use the intuitive forward drift rate: r1t1-r0t0 (ratio of discount factors), but for Euler, one need to use a less intuitive forward drift rate to reproduce a nearly exact forward price.
I have been wondering if there was any better alternative than the standard Sobol (+ Brownian Bridge) quasi random sequence generator for the Monte Carlo simulations of finance derivatives.
Here is what I found:
Scrambled Sobol. The idea is to rerandomize the quasi random numbers slightly. It can provide better uniformity properties and allows for a real estimate of the standard error. There are many ways to do that. The simple Cranley Patterson rotation consisting in adding a pseudo random number modulo 1, Owen scrambling (permutations of the digits) and simplifications of it to achieve a reasonable speed. This is all very well described in Owen Quasi Monte Carlo document
Lattice rules. It is another form of quasi random sequences, which so far was not very well adapted to finance problems. A presentation from Giles & Kuo look like it's changing.
Fast PCA. An alternative to Brownian Bridge is the standard PCA. The problem with PCA is the performance in O(n^2). A possible speedup is possible in the case of a equidistant time steps. This paper shows it can be generalized. But the data in it shows it is only advantageous for more than 1024 steps - not so interesting in Finance.
Recently, that I completed a project that I had initially estimated to around 2 months, in nearly 4 hours. This morning I fixed the few remaining bugs. I looked at the clock, surprised it was still so early and I still had so many hours left in the day.
Now I have more time to polish the details and go beyond the initial goal (I think this scares my manager a bit), but I could (and I believe some people do this often) stop now and all the management would be satisfied.
What’s interesting is that everybody bought the 2 months estimate without questions (I almost even believed it myself). This reminded me of my productivity zero post.